 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTAdaRAG: Task Adaptive Retrieval-Augmented Generation via On-the-Fly Knowledge Graph Construction
Nov 16, 2025Retrieval-Augmented Generation (RAG) improves large language models by retrieving external knowledge, often truncated into smaller chunks due to the input context window, which leads to information loss, resulting in response hallucinations and broken reasoning chains. Moreover, traditional RAG retrieves unstructured knowledge, introducing irrelevant details that hinder accurate reasoning. To address these issues, we propose TAdaRAG, a novel RAG framework for on-the-fly task-adaptive knowledge graph construction from external sources. Specifically, we design an intent-driven routing mechanism to a domain-specific extraction template, followed by supervised fine-tuning and a reinforcement learning-based implicit extraction mechanism, ensuring concise, coherent, and non-redundant knowledge integration. Evaluations on six public benchmarks and a real-world business benchmark (NowNewsQA) across three backbone models demonstrate that TAdaRAG outperforms existing methods across diverse domains and long-text tasks, highlighting its strong generalization and practical effectiveness.
OpenViewer: Openness-Aware Multi-View Learning
Dec 17, 2024



Multi-view learning methods leverage multiple data sources to enhance perception by mining correlations across views, typically relying on predefined categories. However, deploying these models in real-world scenarios presents two primary openness challenges. 1) Lack of Interpretability: The integration mechanisms of multi-view data in existing black-box models remain poorly explained; 2) Insufficient Generalization: Most models are not adapted to multi-view scenarios involving unknown categories. To address these challenges, we propose OpenViewer, an openness-aware multi-view learning framework with theoretical support. This framework begins with a Pseudo-Unknown Sample Generation Mechanism to efficiently simulate open multi-view environments and previously adapt to potential unknown samples. Subsequently, we introduce an Expression-Enhanced Deep Unfolding Network to intuitively promote interpretability by systematically constructing functional prior-mapping modules and effectively providing a more transparent integration mechanism for multi-view data. Additionally, we establish a Perception-Augmented Open-Set Training Regime to significantly enhance generalization by precisely boosting confidences for known categories and carefully suppressing inappropriate confidences for unknown ones. Experimental results demonstrate that OpenViewer effectively addresses openness challenges while ensuring recognition performance for both known and unknown samples. The code is released at https://github.com/dushide/OpenViewer.
Rethinking the Representation in Federated Unsupervised Learning with Non-IID Data
Mar 25, 2024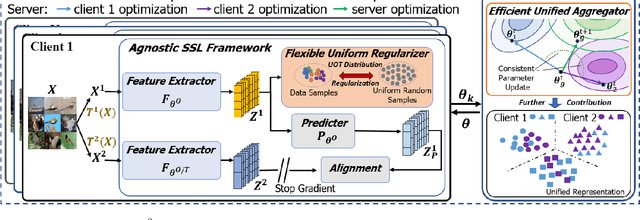
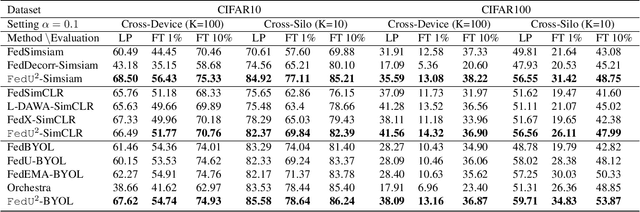

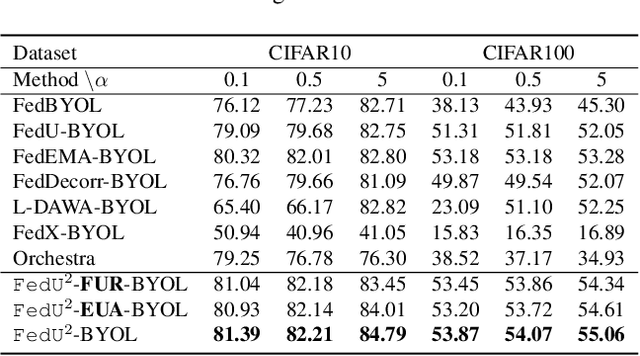
Federated learning achieves effective performance in modeling decentralized data. In practice, client data are not well-labeled, which makes it potential for federated unsupervised learning (FUSL) with non-IID data. However, the performance of existing FUSL methods suffers from insufficient representations, i.e., (1) representation collapse entanglement among local and global models, and (2) inconsistent representation spaces among local models. The former indicates that representation collapse in local model will subsequently impact the global model and other local models. The latter means that clients model data representation with inconsistent parameters due to the deficiency of supervision signals. In this work, we propose FedU2 which enhances generating uniform and unified representation in FUSL with non-IID data. Specifically, FedU2 consists of flexible uniform regularizer (FUR) and efficient unified aggregator (EUA). FUR in each client avoids representation collapse via dispersing samples uniformly, and EUA in server promotes unified representation by constraining consistent client model updating. To extensively validate the performance of FedU2, we conduct both cross-device and cross-silo evaluation experiments on two benchmark datasets, i.e., CIFAR10 and CIFAR100.
MuseGraph: Graph-oriented Instruction Tuning of Large Language Models for Generic Graph Mining
Mar 13, 2024Graphs with abundant attributes are essential in modeling interconnected entities and improving predictions in various real-world applications. Traditional Graph Neural Networks (GNNs), which are commonly used for modeling attributed graphs, need to be re-trained every time when applied to different graph tasks and datasets. Although the emergence of Large Language Models (LLMs) has introduced a new paradigm in natural language processing, the generative potential of LLMs in graph mining remains largely under-explored. To this end, we propose a novel framework MuseGraph, which seamlessly integrates the strengths of GNNs and LLMs and facilitates a more effective and generic approach for graph mining across different tasks and datasets. Specifically, we first introduce a compact graph description via the proposed adaptive input generation to encapsulate key information from the graph under the constraints of language token limitations. Then, we propose a diverse instruction generation mechanism, which distills the reasoning capabilities from LLMs (e.g., GPT-4) to create task-specific Chain-of-Thought-based instruction packages for different graph tasks. Finally, we propose a graph-aware instruction tuning with a dynamic instruction package allocation strategy across tasks and datasets, ensuring the effectiveness and generalization of the training process. Our experimental results demonstrate significant improvements in different graph tasks, showcasing the potential of our MuseGraph in enhancing the accuracy of graph-oriented downstream tasks while keeping the generation powers of LLMs.
Joint Local Relational Augmentation and Global Nash Equilibrium for Federated Learning with Non-IID Data
Aug 17, 2023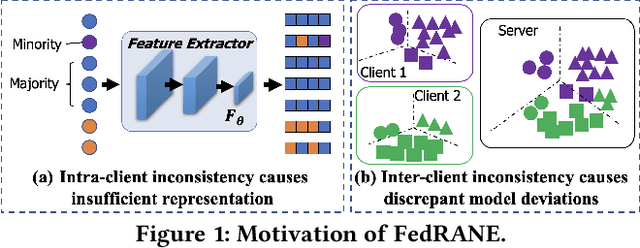
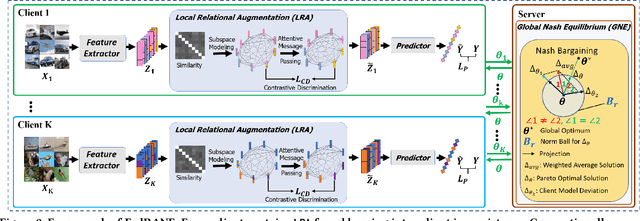
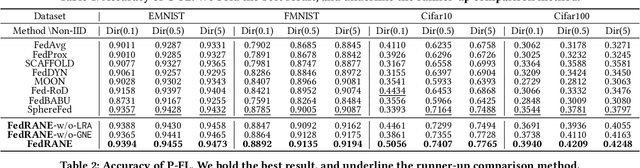
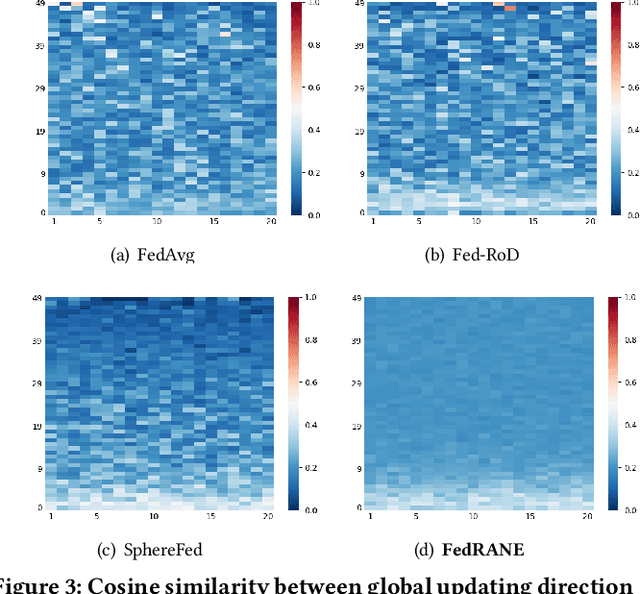
Federated learning (FL) is a distributed machine learning paradigm that needs collaboration between a server and a series of clients with decentralized data. To make FL effective in real-world applications, existing work devotes to improving the modeling of decentralized data with non-independent and identical distributions (non-IID). In non-IID settings, there are intra-client inconsistency that comes from the imbalanced data modeling, and inter-client inconsistency among heterogeneous client distributions, which not only hinders sufficient representation of the minority data, but also brings discrepant model deviations. However, previous work overlooks to tackle the above two coupling inconsistencies together. In this work, we propose FedRANE, which consists of two main modules, i.e., local relational augmentation (LRA) and global Nash equilibrium (GNE), to resolve intra- and inter-client inconsistency simultaneously. Specifically, in each client, LRA mines the similarity relations among different data samples and enhances the minority sample representations with their neighbors using attentive message passing. In server, GNE reaches an agreement among inconsistent and discrepant model deviations from clients to server, which encourages the global model to update in the direction of global optimum without breaking down the clients optimization toward their local optimums. We conduct extensive experiments on four benchmark datasets to show the superiority of FedRANE in enhancing the performance of FL with non-IID data.
Bridging Trustworthiness and Open-World Learning: An Exploratory Neural Approach for Enhancing Interpretability, Generalization, and Robustness
Aug 07, 2023

As researchers strive to narrow the gap between machine intelligence and human through the development of artificial intelligence technologies, it is imperative that we recognize the critical importance of trustworthiness in open-world, which has become ubiquitous in all aspects of daily life for everyone. However, several challenges may create a crisis of trust in current artificial intelligence systems that need to be bridged: 1) Insufficient explanation of predictive results; 2) Inadequate generalization for learning models; 3) Poor adaptability to uncertain environments. Consequently, we explore a neural program to bridge trustworthiness and open-world learning, extending from single-modal to multi-modal scenarios for readers. 1) To enhance design-level interpretability, we first customize trustworthy networks with specific physical meanings; 2) We then design environmental well-being task-interfaces via flexible learning regularizers for improving the generalization of trustworthy learning; 3) We propose to increase the robustness of trustworthy learning by integrating open-world recognition losses with agent mechanisms. Eventually, we enhance various trustworthy properties through the establishment of design-level explainability, environmental well-being task-interfaces and open-world recognition programs. These designed open-world protocols are applicable across a wide range of surroundings, under open-world multimedia recognition scenarios with significant performance improvements observed.
HyperFed: Hyperbolic Prototypes Exploration with Consistent Aggregation for Non-IID Data in Federated Learning
Jul 26, 2023



Federated learning (FL) collaboratively models user data in a decentralized way. However, in the real world, non-identical and independent data distributions (non-IID) among clients hinder the performance of FL due to three issues, i.e., (1) the class statistics shifting, (2) the insufficient hierarchical information utilization, and (3) the inconsistency in aggregating clients. To address the above issues, we propose HyperFed which contains three main modules, i.e., hyperbolic prototype Tammes initialization (HPTI), hyperbolic prototype learning (HPL), and consistent aggregation (CA). Firstly, HPTI in the server constructs uniformly distributed and fixed class prototypes, and shares them with clients to match class statistics, further guiding consistent feature representation for local clients. Secondly, HPL in each client captures the hierarchical information in local data with the supervision of shared class prototypes in the hyperbolic model space. Additionally, CA in the server mitigates the impact of the inconsistent deviations from clients to server. Extensive studies of four datasets prove that HyperFed is effective in enhancing the performance of FL under the non-IID set.
Partial Relaxed Optimal Transport for Denoised Recommendation
Apr 19, 2022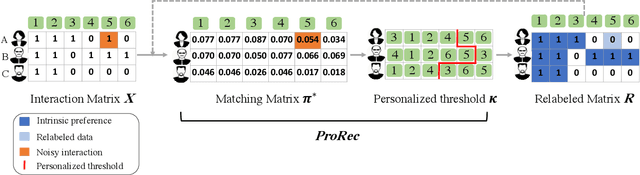
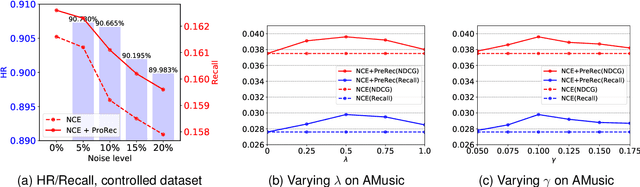
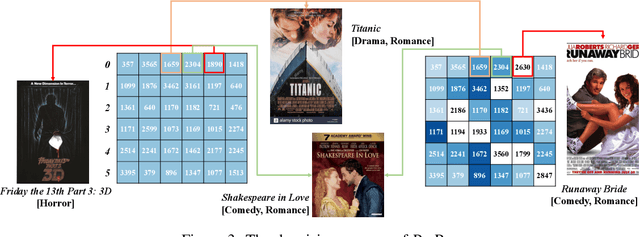
The interaction data used by recommender systems (RSs) inevitably include noises resulting from mistaken or exploratory clicks, especially under implicit feedbacks. Without proper denoising, RS models cannot effectively capture users' intrinsic preferences and the true interactions between users and items. To address such noises, existing methods mostly rely on auxiliary data which are not always available. In this work, we ground on Optimal Transport (OT) to globally match a user embedding space and an item embedding space, allowing both non-deep and deep RS models to discriminate intrinsic and noisy interactions without supervision. Specifically, we firstly leverage the OT framework via Sinkhorn distance to compute the continuous many-to-many user-item matching scores. Then, we relax the regularization in Sinkhorn distance to achieve a closed-form solution with a reduced time complexity. Finally, to consider individual user behaviors for denoising, we develop a partial OT framework to adaptively relabel user-item interactions through a personalized thresholding mechanism. Extensive experiments show that our framework can significantly boost the performances of existing RS models.
Multi-Modal Fusion in Contact-Rich Precise Tasks via Hierarchical Policy Learning
Feb 17, 2022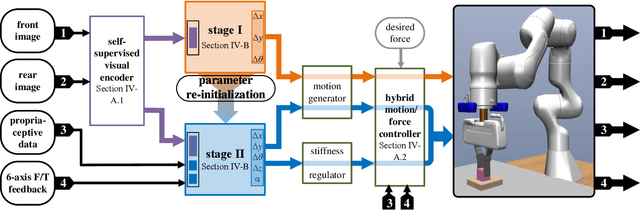

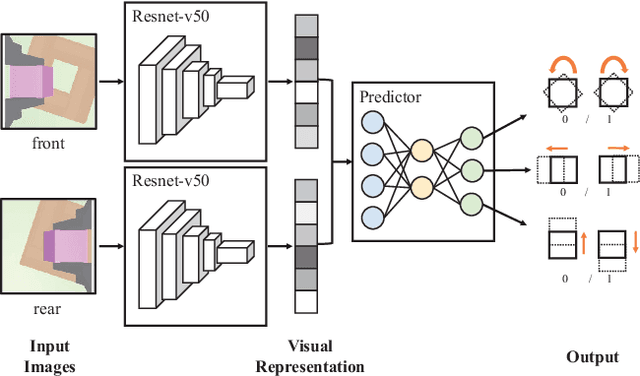
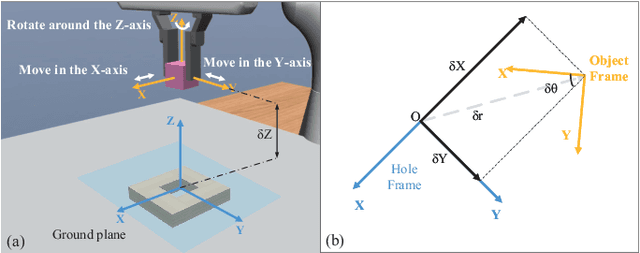
Combined visual and force feedback play an essential role in contact-rich robotic manipulation tasks. Current methods focus on developing the feedback control around a single modality while underrating the synergy of the sensors. Fusing different sensor modalities is necessary but remains challenging. A key challenge is to achieve an effective multi-modal and generalized control scheme to novel objects with precision. This paper proposes a practical multi-modal sensor fusion mechanism using hierarchical policy learning. To begin with, we use a self-supervised encoder that extracts multi-view visual features and a hybrid motion/force controller that regulates force behaviors. Next, the multi-modality fusion is simplified by hierarchical integration of the vision, force, and proprioceptive data in the reinforcement learning (RL) algorithm. Moreover, with hierarchical policy learning, the control scheme can exploit the visual feedback limits and explore the contribution of individual modality in precise tasks. Experiments indicate that robots with the control scheme could assemble objects with 0.25mm clearance in simulation. The system could be generalized to widely varied initial configurations and new shapes. Experiments validate that the simulated system can be robustly transferred to reality without fine-tuning.
Multi-Facet Recommender Networks with Spherical Optimization
Mar 27, 2021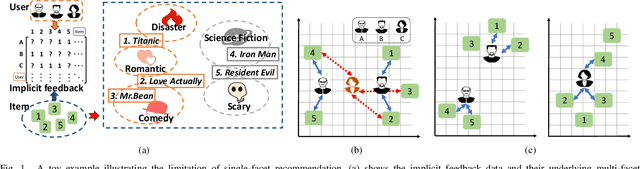
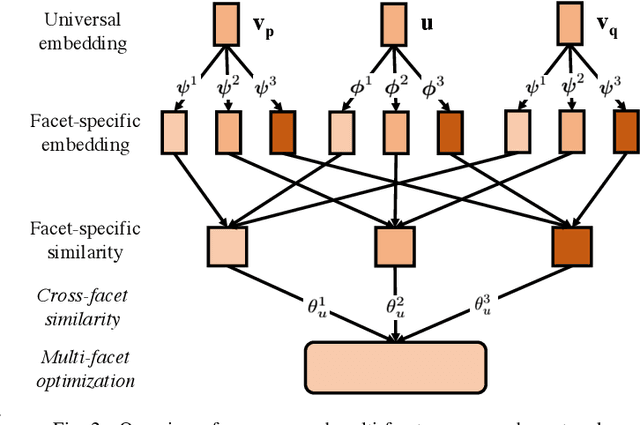
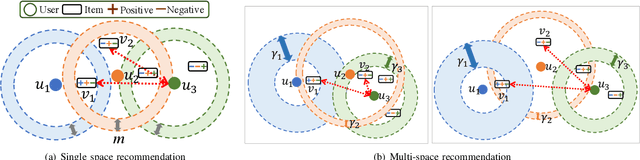
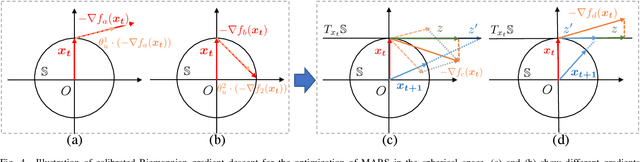
Implicit feedback is widely explored by modern recommender systems. Since the feedback is often sparse and imbalanced, it poses great challenges to the learning of complex interactions among users and items. Metric learning has been proposed to capture user-item interactions from implicit feedback, but existing methods only represent users and items in a single metric space, ignoring the fact that users can have multiple preferences and items can have multiple properties, which leads to potential conflicts limiting their performance in recommendation. To capture the multiple facets of user preferences and item properties while resolving their potential conflicts, we propose the novel framework of Multi-fAcet Recommender networks with Spherical optimization (MARS). By designing a cross-facet similarity measurement, we project users and items into multiple metric spaces for fine-grained representation learning, and compare them only in the proper spaces. Furthermore, we devise a spherical optimization strategy to enhance the effectiveness and robustness of the multi-facet recommendation framework. Extensive experiments on six real-world benchmark datasets show drastic performance gains brought by MARS, which constantly achieves up to 40\% improvements over the state-of-the-art baselines regarding both HR and nDCG metrics.