 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Huber loss-based super learner with applications to healthcare expenditures
May 13, 2022
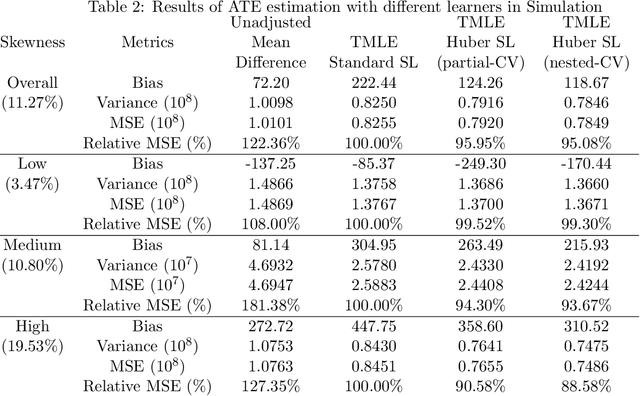
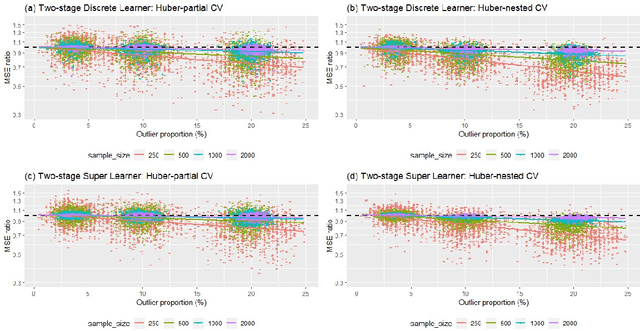
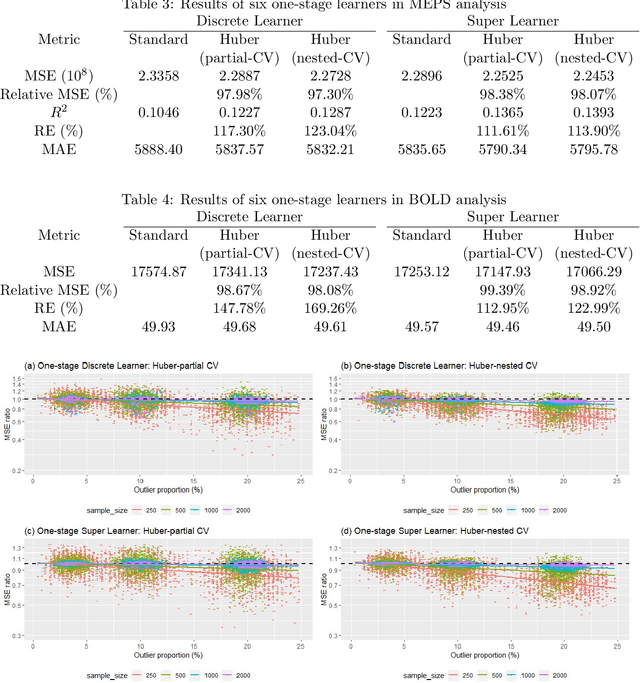
Complex distributions of the healthcare expenditure pose challenges to statistical modeling via a single model. Super learning, an ensemble method that combines a range of candidate models, is a promising alternative for cost estimation and has shown benefits over a single model. However, standard approaches to super learning may have poor performance in settings where extreme values are present, such as healthcare expenditure data. We propose a super learner based on the Huber loss, a "robust" loss function that combines squared error loss with absolute loss to down-weight the influence of outliers. We derive oracle inequalities that establish bounds on the finite-sample and asymptotic performance of the method. We show that the proposed method can be used both directly to optimize Huber risk, as well as in finite-sample settings where optimizing mean squared error is the ultimate goal. For this latter scenario, we provide two methods for performing a grid search for values of the robustification parameter indexing the Huber loss. Simulations and real data analysis demonstrate appreciable finite-sample gains in cost prediction and causal effect estimation using our proposed method.
Partial Relaxed Optimal Transport for Denoised Recommendation
Apr 19, 2022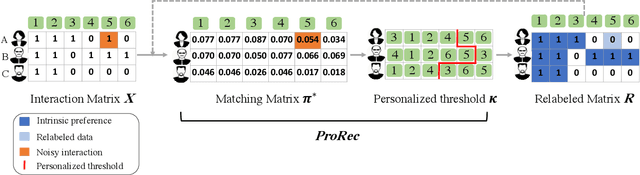
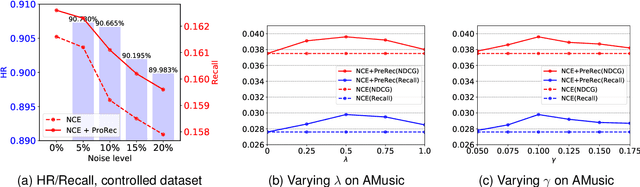
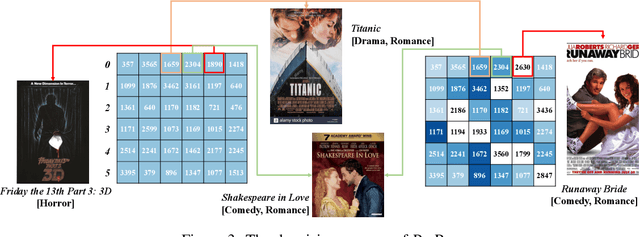
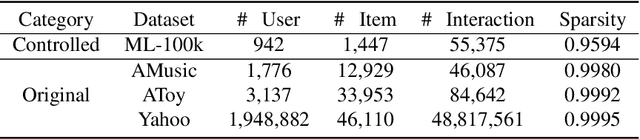
The interaction data used by recommender systems (RSs) inevitably include noises resulting from mistaken or exploratory clicks, especially under implicit feedbacks. Without proper denoising, RS models cannot effectively capture users' intrinsic preferences and the true interactions between users and items. To address such noises, existing methods mostly rely on auxiliary data which are not always available. In this work, we ground on Optimal Transport (OT) to globally match a user embedding space and an item embedding space, allowing both non-deep and deep RS models to discriminate intrinsic and noisy interactions without supervision. Specifically, we firstly leverage the OT framework via Sinkhorn distance to compute the continuous many-to-many user-item matching scores. Then, we relax the regularization in Sinkhorn distance to achieve a closed-form solution with a reduced time complexity. Finally, to consider individual user behaviors for denoising, we develop a partial OT framework to adaptively relabel user-item interactions through a personalized thresholding mechanism. Extensive experiments show that our framework can significantly boost the performances of existing RS models.
Learning Commonsense-aware Moment-Text Alignment for Fast Video Temporal Grounding
Apr 12, 2022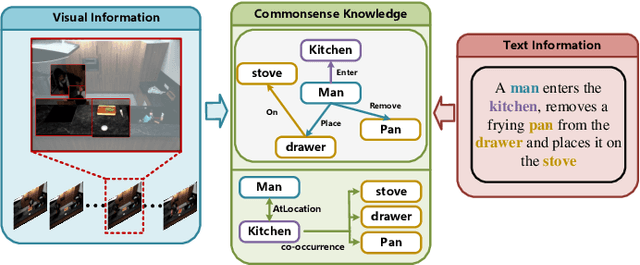
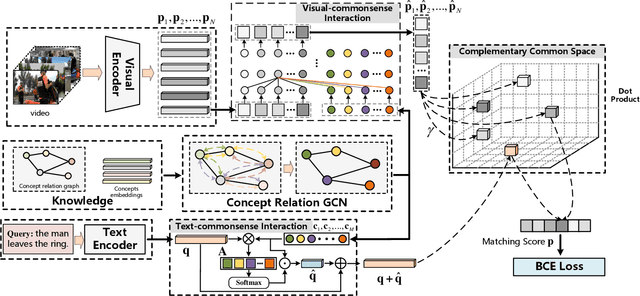
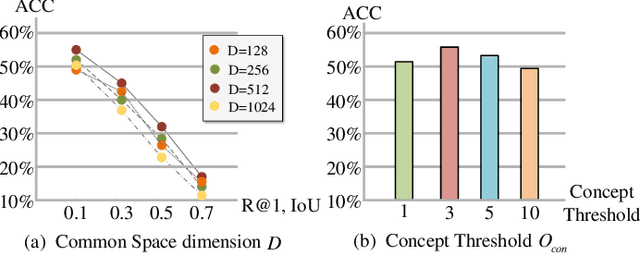
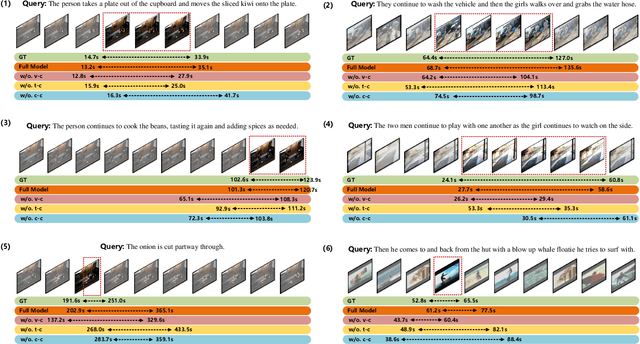
Grounding temporal video segments described in natural language queries effectively and efficiently is a crucial capability needed in vision-and-language fields. In this paper, we deal with the fast video temporal grounding (FVTG) task, aiming at localizing the target segment with high speed and favorable accuracy. Most existing approaches adopt elaborately designed cross-modal interaction modules to improve the grounding performance, which suffer from the test-time bottleneck. Although several common space-based methods enjoy the high-speed merit during inference, they can hardly capture the comprehensive and explicit relations between visual and textual modalities. In this paper, to tackle the dilemma of speed-accuracy tradeoff, we propose a commonsense-aware cross-modal alignment (CCA) framework, which incorporates commonsense-guided visual and text representations into a complementary common space for fast video temporal grounding. Specifically, the commonsense concepts are explored and exploited by extracting the structural semantic information from a language corpus. Then, a commonsense-aware interaction module is designed to obtain bridged visual and text features by utilizing the learned commonsense concepts. Finally, to maintain the original semantic information of textual queries, a cross-modal complementary common space is optimized to obtain matching scores for performing FVTG. Extensive results on two challenging benchmarks show that our CCA method performs favorably against state-of-the-arts while running at high speed. Our code is available at https://github.com/ZiyueWu59/CCA.