 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOmniVLA-RL: A Vision-Language-Action Model with Spatial Understanding and Online RL
Apr 20, 2026Visual-Language-Action (VLA) models represent a paradigm shift in embodied AI, yet existing frameworks often struggle with imprecise spatial perception, suboptimal multimodal fusion, and instability in reinforcement learning. To bridge these gaps, we propose OmniVLA-RL, a novel architecture that leverages a Mix-of-Transformers (MoT) design to synergistically integrate reasoning, spatial, and action experts. Furthermore, we introduce Flow-GSPO, which reformulates flow matching as a Stochastic Differential Equation (SDE) process and integrates it with Group Segmented Policy Optimization (GSPO) to enhance action precision and training robustness. Extensive evaluations on the LIBERO and LIBERO-Plus benchmarks demonstrate that OmniVLA-RL significantly outperforms state-of-the-art methods, effectively overcoming the fundamental limitations of current VLA models.
DynStatF: An Efficient Feature Fusion Strategy for LiDAR 3D Object Detection
May 24, 2023


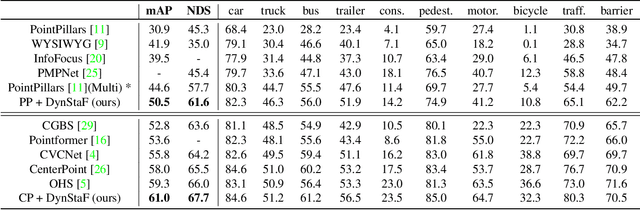
Augmenting LiDAR input with multiple previous frames provides richer semantic information and thus boosts performance in 3D object detection, However, crowded point clouds in multi-frames can hurt the precise position information due to the motion blur and inaccurate point projection. In this work, we propose a novel feature fusion strategy, DynStaF (Dynamic-Static Fusion), which enhances the rich semantic information provided by the multi-frame (dynamic branch) with the accurate location information from the current single-frame (static branch). To effectively extract and aggregate complimentary features, DynStaF contains two modules, Neighborhood Cross Attention (NCA) and Dynamic-Static Interaction (DSI), operating through a dual pathway architecture. NCA takes the features in the static branch as queries and the features in the dynamic branch as keys (values). When computing the attention, we address the sparsity of point clouds and take only neighborhood positions into consideration. NCA fuses two features at different feature map scales, followed by DSI providing the comprehensive interaction. To analyze our proposed strategy DynStaF, we conduct extensive experiments on the nuScenes dataset. On the test set, DynStaF increases the performance of PointPillars in NDS by a large margin from 57.7% to 61.6%. When combined with CenterPoint, our framework achieves 61.0% mAP and 67.7% NDS, leading to state-of-the-art performance without bells and whistles.
Partial Relaxed Optimal Transport for Denoised Recommendation
Apr 19, 2022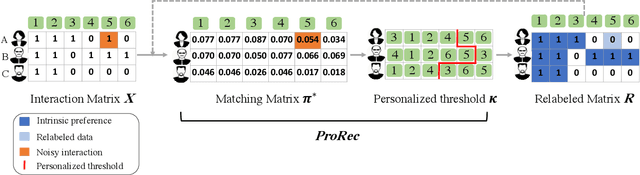
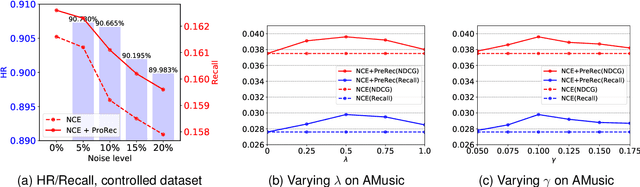
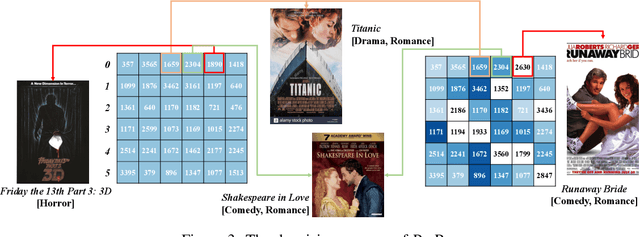
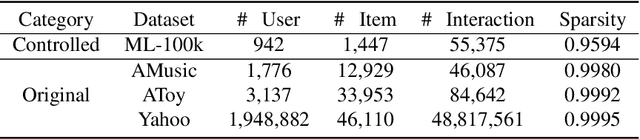
The interaction data used by recommender systems (RSs) inevitably include noises resulting from mistaken or exploratory clicks, especially under implicit feedbacks. Without proper denoising, RS models cannot effectively capture users' intrinsic preferences and the true interactions between users and items. To address such noises, existing methods mostly rely on auxiliary data which are not always available. In this work, we ground on Optimal Transport (OT) to globally match a user embedding space and an item embedding space, allowing both non-deep and deep RS models to discriminate intrinsic and noisy interactions without supervision. Specifically, we firstly leverage the OT framework via Sinkhorn distance to compute the continuous many-to-many user-item matching scores. Then, we relax the regularization in Sinkhorn distance to achieve a closed-form solution with a reduced time complexity. Finally, to consider individual user behaviors for denoising, we develop a partial OT framework to adaptively relabel user-item interactions through a personalized thresholding mechanism. Extensive experiments show that our framework can significantly boost the performances of existing RS models.
Multi-Facet Recommender Networks with Spherical Optimization
Mar 27, 2021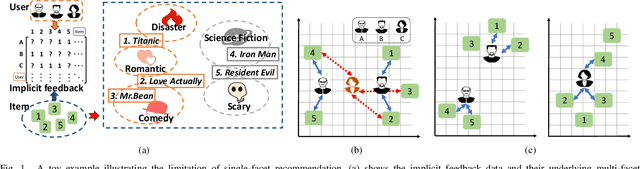
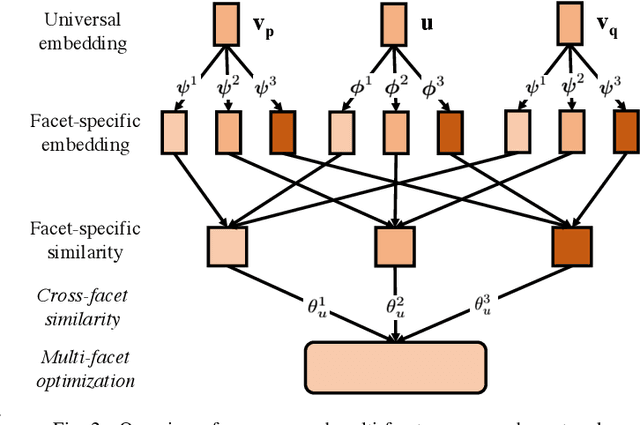
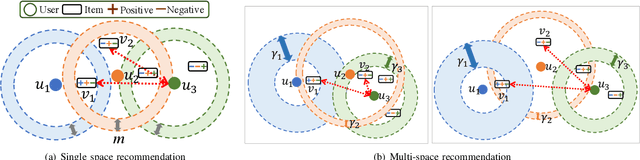
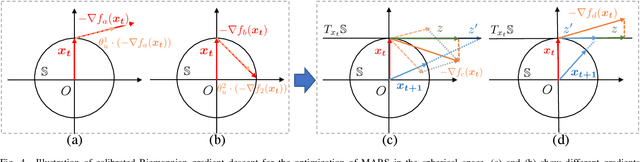
Implicit feedback is widely explored by modern recommender systems. Since the feedback is often sparse and imbalanced, it poses great challenges to the learning of complex interactions among users and items. Metric learning has been proposed to capture user-item interactions from implicit feedback, but existing methods only represent users and items in a single metric space, ignoring the fact that users can have multiple preferences and items can have multiple properties, which leads to potential conflicts limiting their performance in recommendation. To capture the multiple facets of user preferences and item properties while resolving their potential conflicts, we propose the novel framework of Multi-fAcet Recommender networks with Spherical optimization (MARS). By designing a cross-facet similarity measurement, we project users and items into multiple metric spaces for fine-grained representation learning, and compare them only in the proper spaces. Furthermore, we devise a spherical optimization strategy to enhance the effectiveness and robustness of the multi-facet recommendation framework. Extensive experiments on six real-world benchmark datasets show drastic performance gains brought by MARS, which constantly achieves up to 40\% improvements over the state-of-the-art baselines regarding both HR and nDCG metrics.
You Only Watch Once: A Unified CNN Architecture for Real-Time Spatiotemporal Action Localization
Nov 15, 2019
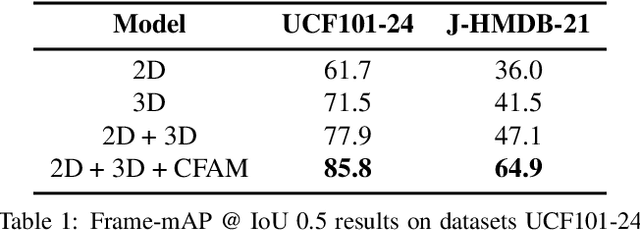
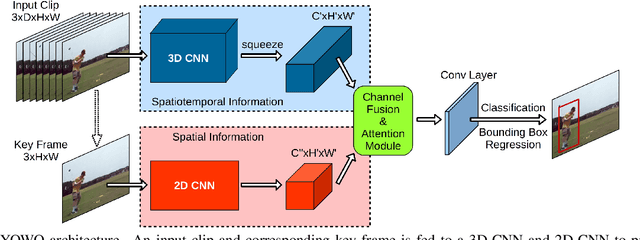
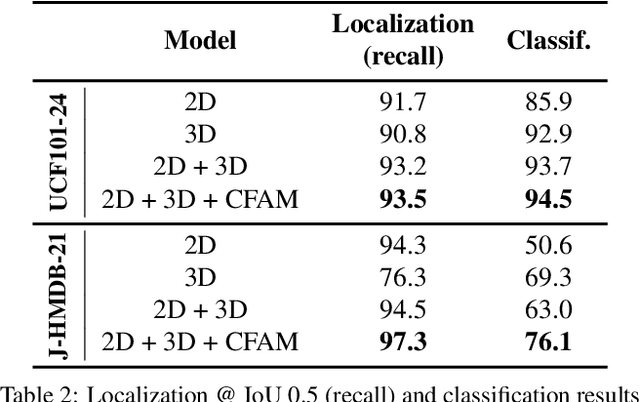
Spatiotemporal action localization requires incorporation of two sources of information into the designed architecture: (1) Temporal information from the previous frames and (2) spatial information from the key frame. Current state-of-the-art approaches usually extract these information with separate networks and use an extra mechanism for fusion to get detections. In this work, we present YOWO, a unified CNN architecture for real-time spatiotemporal action localization in video stream. YOWO makes use of a single neural network to extract temporal and spatial information concurrently and predict bounding boxes and action probabilities directly from video clips in one evaluation. Since the whole architecture is unified, it can be optimized end-to-end. The YOWO architecture is fast providing 34 frames-per-second on 16-frames input clips and 62 frames-per-second on 8-frames input clips. Remarkably, YOWO outperforms the previous state-of-the art results on J-HMDB-21 (71.1%) and UCF101-24 (75.0%) with 74.4% and 87.2% frame-mAP, respectively.