 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInference-Adaptive Neural Steering for Real-Time Area-Based Sound Source Separation
Aug 23, 2024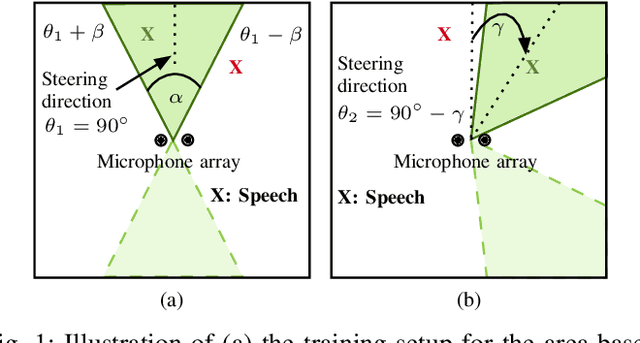
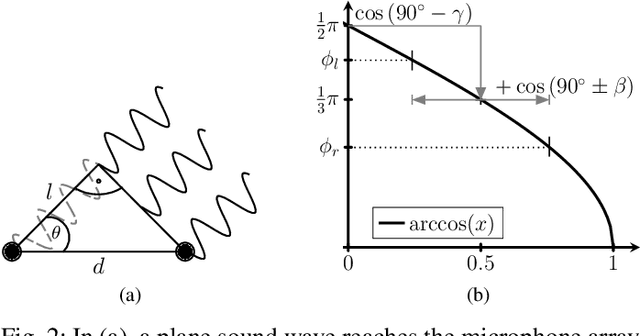
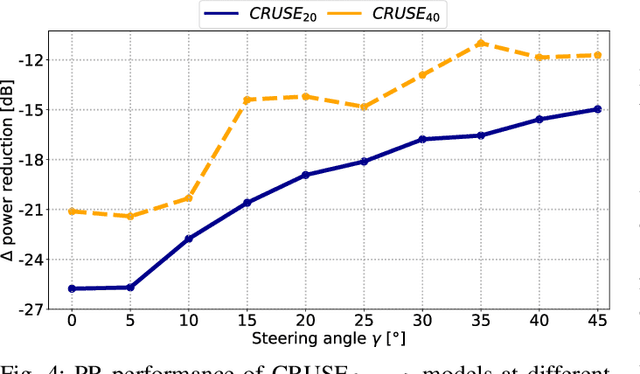
We propose a novel Neural Steering technique that adapts the target area of a spatial-aware multi-microphone sound source separation algorithm during inference without the necessity of retraining the deep neural network (DNN). To achieve this, we first train a DNN aiming to retain speech within a target region, defined by an angular span, while suppressing sound sources stemming from other directions. Afterward, a phase shift is applied to the microphone signals, allowing us to shift the center of the target area during inference at negligible additional cost in computational complexity. Further, we show that the proposed approach performs well in a wide variety of acoustic scenarios, including several speakers inside and outside the target area and additional noise. More precisely, the proposed approach performs on par with DNNs trained explicitly for the steered target area in terms of DNSMOS and SI-SDR.
Efficient Area-based and Speaker-Agnostic Source Separation
Aug 19, 2024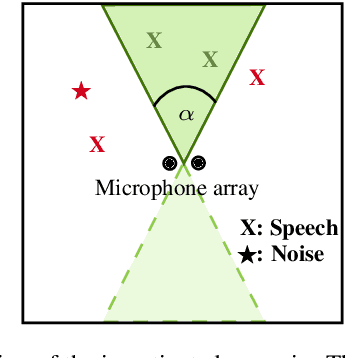
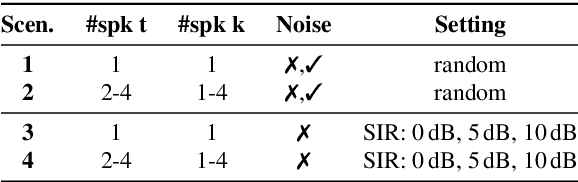
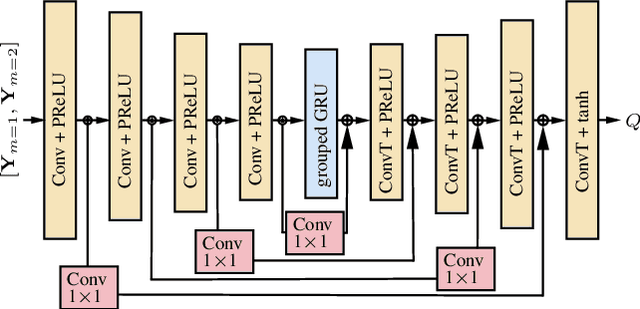
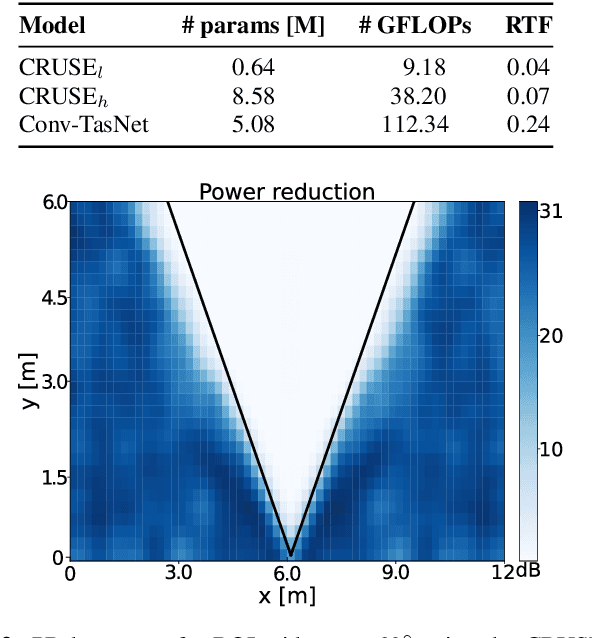
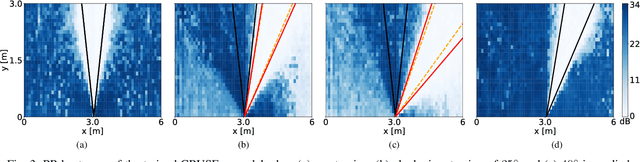
This paper introduces an area-based source separation method designed for virtual meeting scenarios. The aim is to preserve speech signals from an unspecified number of sources within a defined spatial area in front of a linear microphone array, while suppressing all other sounds. Therefore, we employ an efficient neural network architecture adapted for multi-channel input to encompass the predefined target area. To evaluate the approach, training data and specific test scenarios including multiple target and interfering speakers, as well as background noise are simulated. All models are rated according to DNSMOS and scale-invariant signal-to-distortion ratio. Our experiments show that the proposed method separates speech from multiple speakers within the target area well, besides being of very low complexity, intended for real-time processing. In addition, a power reduction heatmap is used to demonstrate the networks' ability to identify sources located within the target area. We put our approach in context with a well-established baseline for speaker-speaker separation and discuss its strengths and challenges.
How to Design a Three-Stage Architecture for Audio-Visual Active Speaker Detection in the Wild
Jun 07, 2021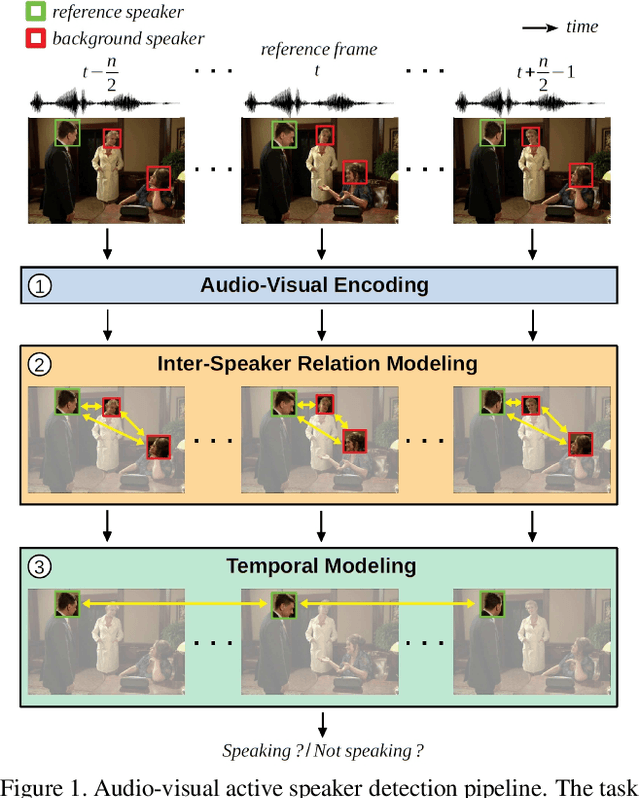

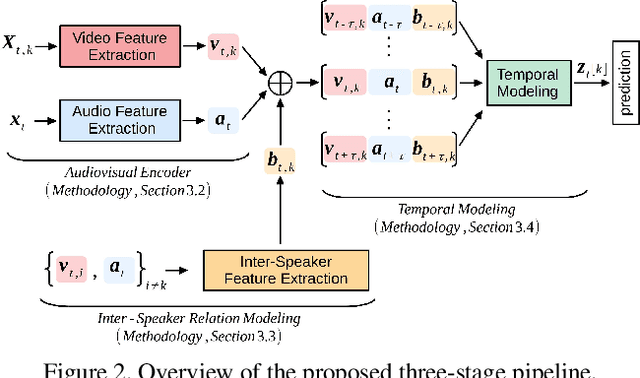
Successful active speaker detection requires a three-stage pipeline: (i) audio-visual encoding for all speakers in the clip, (ii) inter-speaker relation modeling between a reference speaker and the background speakers within each frame, and (iii) temporal modeling for the reference speaker. Each stage of this pipeline plays an important role for the final performance of the created architecture. Based on a series of controlled experiments, this work presents several practical guidelines for audio-visual active speaker detection. Correspondingly, we present a new architecture called ASDNet, which achieves a new state-of-the-art on the AVA-ActiveSpeaker dataset with a mAP of 93.5% outperforming the second best with a large margin of 4.7%. Our code and pretrained models are publicly available.
Deep Compact Polyhedral Conic Classifier for Open and Closed Set Recognition
Feb 24, 2021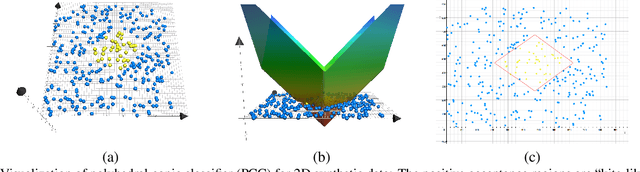



In this paper, we propose a new deep neural network classifier that simultaneously maximizes the inter-class separation and minimizes the intra-class variation by using the polyhedral conic classification function. The proposed method has one loss term that allows the margin maximization to maximize the inter-class separation and another loss term that controls the compactness of the class acceptance regions. Our proposed method has a nice geometric interpretation using polyhedral conic function geometry. We tested the proposed method on various visual classification problems including closed/open set recognition and anomaly detection. The experimental results show that the proposed method typically outperforms other state-of-the art methods, and becomes a better choice compared to other tested methods especially for open set recognition type problems.
TRAT: Tracking by Attention Using Spatio-Temporal Features
Nov 18, 2020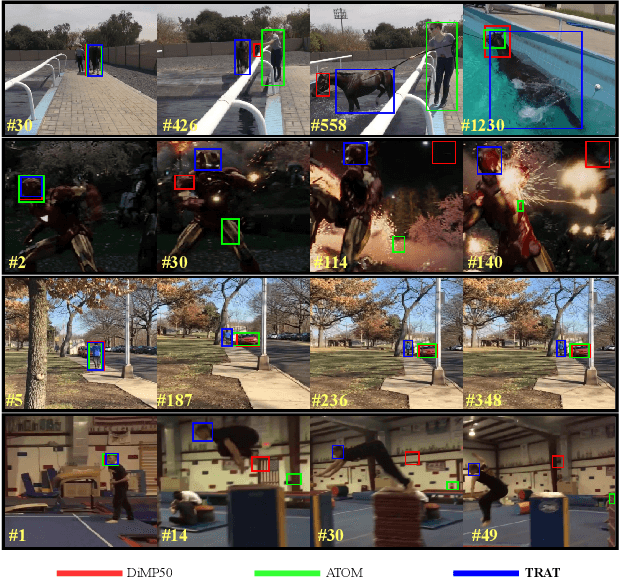

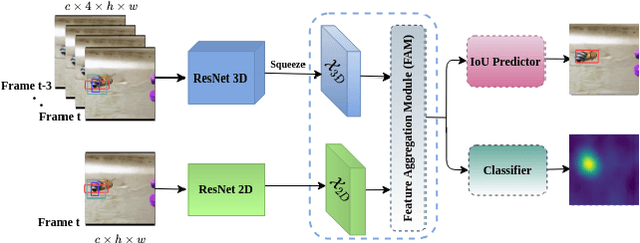
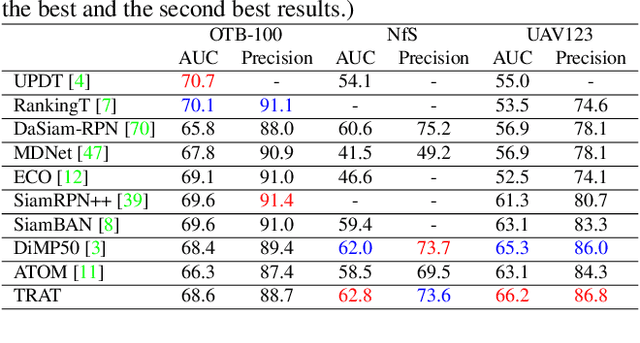
Robust object tracking requires knowledge of tracked objects' appearance, motion and their evolution over time. Although motion provides distinctive and complementary information especially for fast moving objects, most of the recent tracking architectures primarily focus on the objects' appearance information. In this paper, we propose a two-stream deep neural network tracker that uses both spatial and temporal features. Our architecture is developed over ATOM tracker and contains two backbones: (i) 2D-CNN network to capture appearance features and (ii) 3D-CNN network to capture motion features. The features returned by the two networks are then fused with attention based Feature Aggregation Module (FAM). Since the whole architecture is unified, it can be trained end-to-end. The experimental results show that the proposed tracker TRAT (TRacking by ATtention) achieves state-of-the-art performance on most of the benchmarks and it significantly outperforms the baseline ATOM tracker.
Driver Anomaly Detection: A Dataset and Contrastive Learning Approach
Sep 30, 2020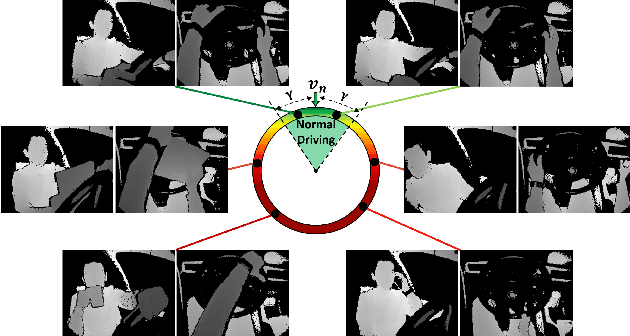



Distracted drivers are more likely to fail to anticipate hazards, which result in car accidents. Therefore, detecting anomalies in drivers' actions (i.e., any action deviating from normal driving) contains the utmost importance to reduce driver-related accidents. However, there are unbounded many anomalous actions that a driver can do while driving, which leads to an 'open set recognition' problem. Accordingly, instead of recognizing a set of anomalous actions that are commonly defined by previous dataset providers, in this work, we propose a contrastive learning approach to learn a metric to differentiate normal driving from anomalous driving. For this task, we introduce a new video-based benchmark, the Driver Anomaly Detection (DAD) dataset, which contains normal driving videos together with a set of anomalous actions in its training set. In the test set of the DAD dataset, there are unseen anomalous actions that still need to be winnowed out from normal driving. Our method reaches 0.9673 AUC on the test set, demonstrating the effectiveness of the contrastive learning approach on the anomaly detection task. Our dataset, codes and pre-trained models are publicly available.
Dissected 3D CNNs: Temporal Skip Connections for Efficient Online Video Processing
Sep 30, 2020
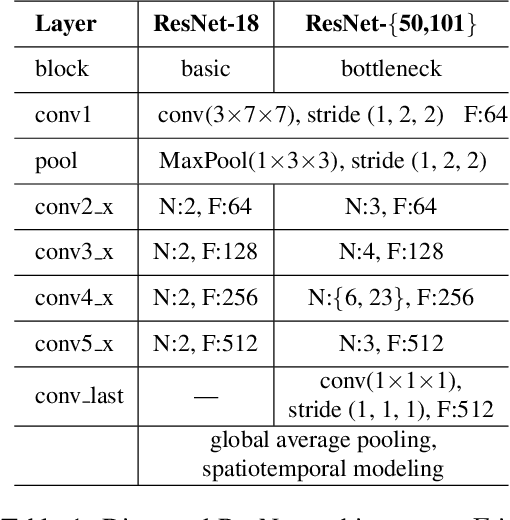
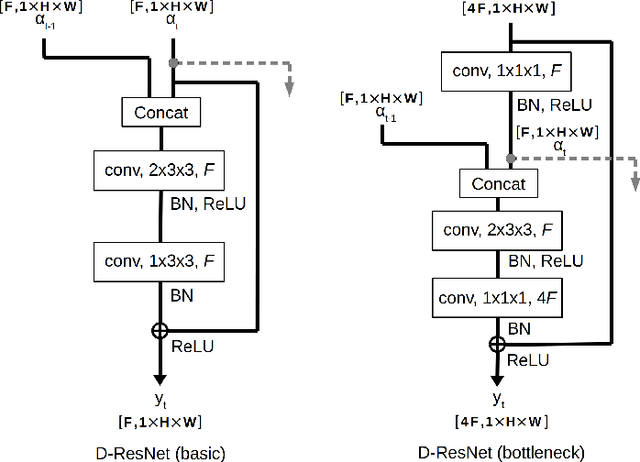

Convolutional Neural Networks with 3D kernels (3D CNNs) currently achieve state-of-the-art results in video recognition tasks due to their supremacy in extracting spatiotemporal features within video frames. There have been many successful 3D CNN architectures surpassing the state-of-the-art results successively. However, nearly all of them are designed to operate offline creating several serious handicaps during online operation. Firstly, conventional 3D CNNs are not dynamic since their output features represent the complete input clip instead of the most recent frame in the clip. Secondly, they are not temporal resolution-preserving due to their inherent temporal downsampling. Lastly, 3D CNNs are constrained to be used with fixed temporal input size limiting their flexibility. In order to address these drawbacks, we propose dissected 3D CNNs, where the intermediate volumes of the network are dissected and propagated over depth (time) dimension for future calculations, substantially reducing the number of computations at online operation. For action classification, the dissected version of ResNet models performs 74-90% fewer computations at online operation while achieving $\sim$5% better classification accuracy on the Kinetics-600 dataset than conventional 3D ResNet models. Moreover, the advantages of dissected 3D CNNs are demonstrated by deploying our approach onto several vision tasks, which consistently improved the performance.
DriverMHG: A Multi-Modal Dataset for Dynamic Recognition of Driver Micro Hand Gestures and a Real-Time Recognition Framework
Mar 02, 2020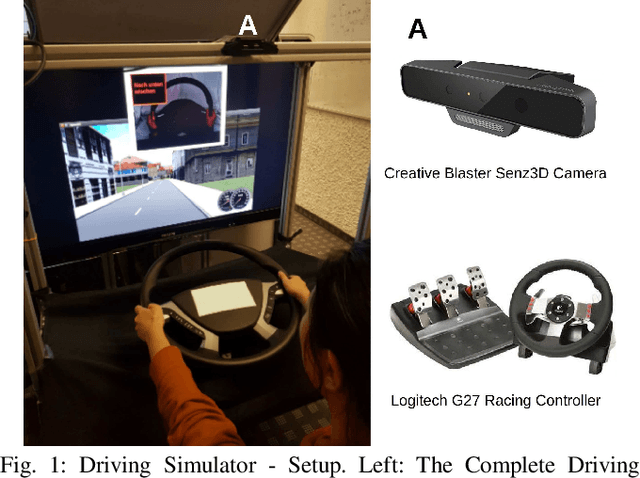



The use of hand gestures provides a natural alternative to cumbersome interface devices for Human-Computer Interaction (HCI) systems. However, real-time recognition of dynamic micro hand gestures from video streams is challenging for in-vehicle scenarios since (i) the gestures should be performed naturally without distracting the driver, (ii) micro hand gestures occur within very short time intervals at spatially constrained areas, (iii) the performed gesture should be recognized only once, and (iv) the entire architecture should be designed lightweight as it will be deployed to an embedded system. In this work, we propose an HCI system for dynamic recognition of driver micro hand gestures, which can have a crucial impact in automotive sector especially for safety related issues. For this purpose, we initially collected a dataset named Driver Micro Hand Gestures (DriverMHG), which consists of RGB, depth and infrared modalities. The challenges for dynamic recognition of micro hand gestures have been addressed by proposing a lightweight convolutional neural network (CNN) based architecture which operates online efficiently with a sliding window approach. For the CNN model, several 3-dimensional resource efficient networks are applied and their performances are analyzed. Online recognition of gestures has been performed with 3D-MobileNetV2, which provided the best offline accuracy among the applied networks with similar computational complexities. The final architecture is deployed on a driver simulator operating in real-time. We make DriverMHG dataset and our source code publicly available.
Deep Attention Based Semi-Supervised 2D-Pose Estimation for Surgical Instruments
Dec 10, 2019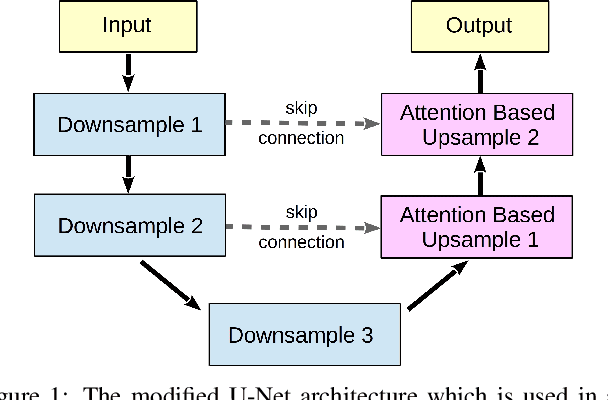
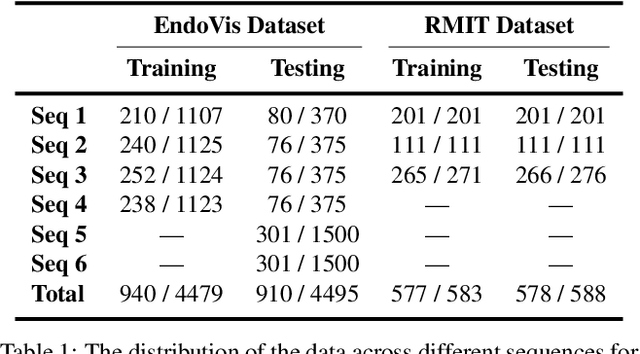
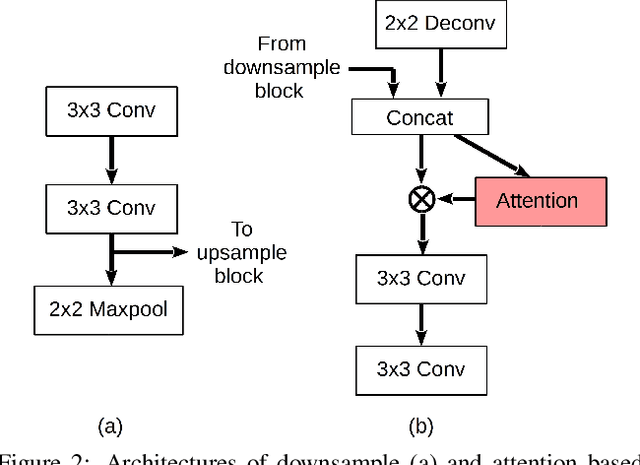
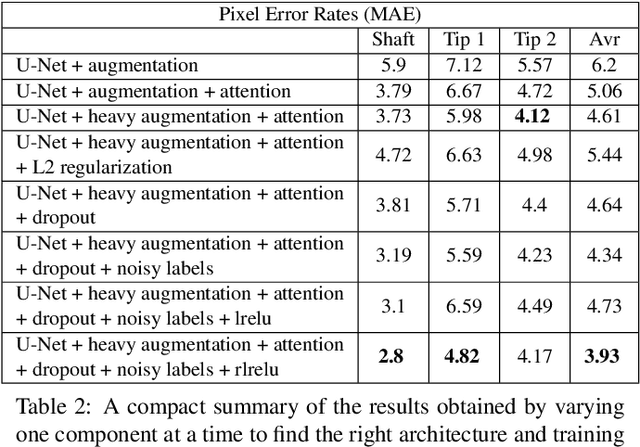
For many practical problems and applications, it is not feasible to create a vast and accurately labeled dataset, which restricts the application of deep learning in many areas. Semi-supervised learning algorithms intend to improve performance by also leveraging unlabeled data. This is very valuable for 2D-pose estimation task where data labeling requires substantial time and is subject to noise. This work aims to investigate if semi-supervised learning techniques can achieve acceptable performance level that makes using these algorithms during training justifiable. To this end, a lightweight network architecture is introduced and mean teacher, virtual adversarial training and pseudo-labeling algorithms are evaluated on 2D-pose estimation for surgical instruments. For the applicability of pseudo-labelling algorithm, we propose a novel confidence measure, total variation. Experimental results show that utilization of semi-supervised learning improves the performance on unseen geometries drastically while maintaining high accuracy for seen geometries. For RMIT benchmark, our lightweight architecture outperforms state-of-the-art with supervised learning. For Endovis benchmark, pseudo-labelling algorithm improves the supervised baseline achieving the new state-of-the-art performance.
Unsupervised Monocular Depth Prediction for Indoor Continuous Video Streams
Nov 20, 2019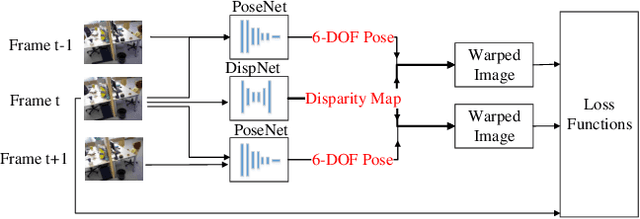

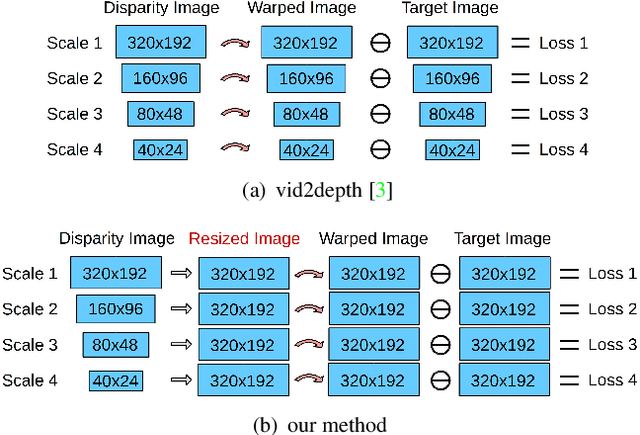

This paper studies unsupervised monocular depth prediction problem. Most of existing unsupervised depth prediction algorithms are developed for outdoor scenarios, while the depth prediction work in the indoor environment is still very scarce to our knowledge. Therefore, this work focuses on narrowing the gap by firstly evaluating existing approaches in the indoor environments and then improving the state-of-the-art design of architecture. Unlike typical outdoor training dataset, such as KITTI with motion constraints, data for indoor environment contains more arbitrary camera movement and short baseline between two consecutive images, which deteriorates the network training for the pose estimation. To address this issue, we propose two methods: Firstly, we propose a novel reconstruction loss function to constraint pose estimation, resulting in accuracy improvement of the predicted disparity map; secondly, we use an ensemble learning with a flipping strategy along with a median filter, directly taking operation on the output disparity map. We evaluate our approaches on the TUM RGB-D and self-collected datasets. The results have shown that both approaches outperform the previous state-of-the-art unsupervised learning approaches.