 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFairness by Learning Orthogonal Disentangled Representations
Mar 22, 2020



Learning discriminative powerful representations is a crucial step for machine learning systems. Introducing invariance against arbitrary nuisance or sensitive attributes while performing well on specific tasks is an important problem in representation learning. This is mostly approached by purging the sensitive information from learned representations. In this paper, we propose a novel disentanglement approach to invariant representation problem. We disentangle the meaningful and sensitive representations by enforcing orthogonality constraints as a proxy for independence. We explicitly enforce the meaningful representation to be agnostic to sensitive information by entropy maximization. The proposed approach is evaluated on five publicly available datasets and compared with state of the art methods for learning fairness and invariance achieving the state of the art performance on three datasets and comparable performance on the rest. Further, we perform an ablative study to evaluate the effect of each component.
Deep Attention Based Semi-Supervised 2D-Pose Estimation for Surgical Instruments
Dec 10, 2019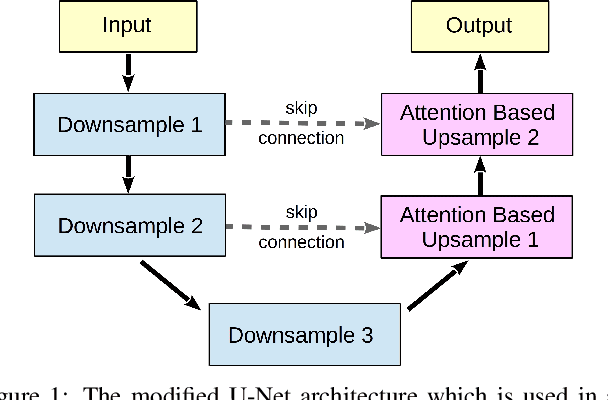
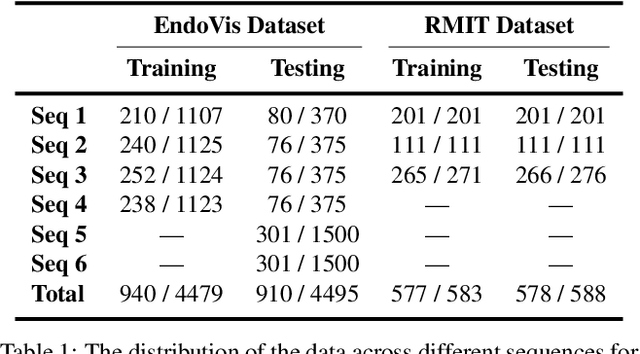
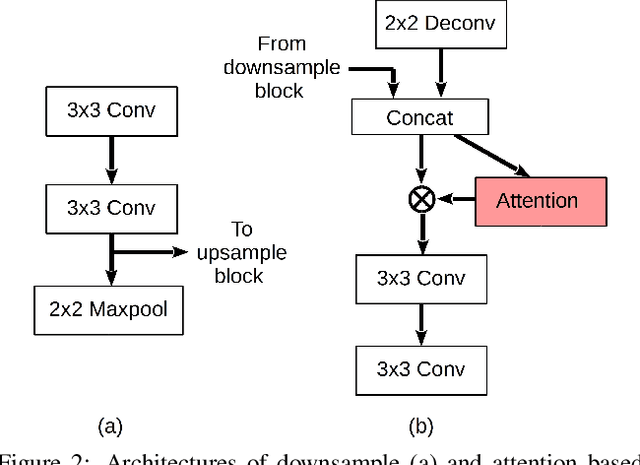
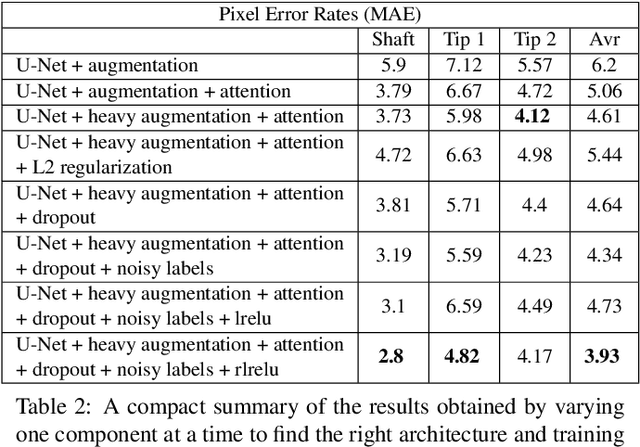
For many practical problems and applications, it is not feasible to create a vast and accurately labeled dataset, which restricts the application of deep learning in many areas. Semi-supervised learning algorithms intend to improve performance by also leveraging unlabeled data. This is very valuable for 2D-pose estimation task where data labeling requires substantial time and is subject to noise. This work aims to investigate if semi-supervised learning techniques can achieve acceptable performance level that makes using these algorithms during training justifiable. To this end, a lightweight network architecture is introduced and mean teacher, virtual adversarial training and pseudo-labeling algorithms are evaluated on 2D-pose estimation for surgical instruments. For the applicability of pseudo-labelling algorithm, we propose a novel confidence measure, total variation. Experimental results show that utilization of semi-supervised learning improves the performance on unseen geometries drastically while maintaining high accuracy for seen geometries. For RMIT benchmark, our lightweight architecture outperforms state-of-the-art with supervised learning. For Endovis benchmark, pseudo-labelling algorithm improves the supervised baseline achieving the new state-of-the-art performance.
Multi-scale Microaneurysms Segmentation Using Embedding Triplet Loss
Apr 18, 2019


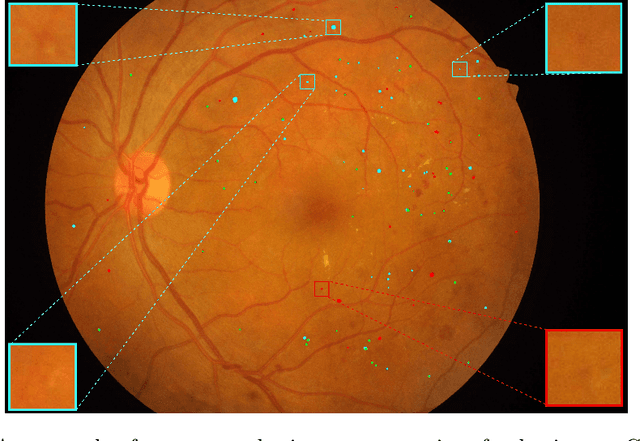
Deep learning techniques are recently being used in fundus image analysis and diabetic retinopathy detection. Microaneurysms are an important indicator of diabetic retinopathy progression. We introduce a two-stage deep learning approach for microaneurysms segmentation using multiple scales of the input with selective sampling and embedding triplet loss. The model first segments on two scales and then the segmentations are refined with a classification model. To enhance the discriminative power of the classification model, we incorporate triplet embedding loss with a selective sampling routine. The model is evaluated quantitatively to assess the segmentation performance and qualitatively to analyze the model predictions. This approach introduces a 30.29% relative improvement over the fully convolutional neural network.
Learning Interpretable Disentangled Representations using Adversarial VAEs
Apr 17, 2019
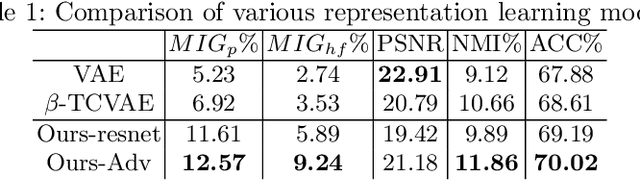
Learning Interpretable representation in medical applications is becoming essential for adopting data-driven models into clinical practice. It has been recently shown that learning a disentangled feature representation is important for a more compact and explainable representation of the data. In this paper, we introduce a novel adversarial variational autoencoder with a total correlation constraint to enforce independence on the latent representation while preserving the reconstruction fidelity. Our proposed method is validated on a publicly available dataset showing that the learned disentangled representation is not only interpretable, but also superior to the state-of-the-art methods. We report a relative improvement of 81.50% in terms of disentanglement, 11.60% in clustering, and 2% in supervised classification with a few amounts of labeled data.