 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNormalizing Flow based Feature Synthesis for Outlier-Aware Object Detection
Feb 01, 2023



Real-world deployment of reliable object detectors is crucial for applications such as autonomous driving. However, general-purpose object detectors like Faster R-CNN are prone to providing overconfident predictions for outlier objects. Recent outlier-aware object detection approaches estimate the density of instance-wide features with class-conditional Gaussians and train on synthesized outlier features from their low-likelihood regions. However, this strategy does not guarantee that the synthesized outlier features will have a low likelihood according to the other class-conditional Gaussians. We propose a novel outlier-aware object detection framework that learns to distinguish outliers from inlier objects by learning the joint data distribution of all inlier classes with an invertible normalizing flow. The flow model ensures that the synthesized outliers have a lower likelihood than inliers of all object classes, thereby modeling a better decision boundary between inlier and outlier objects. Our approach significantly outperforms the state-of-the-art for outlier-aware object detection on both image and video datasets.
Enhancing Fairness of Visual Attribute Predictors
Jul 14, 2022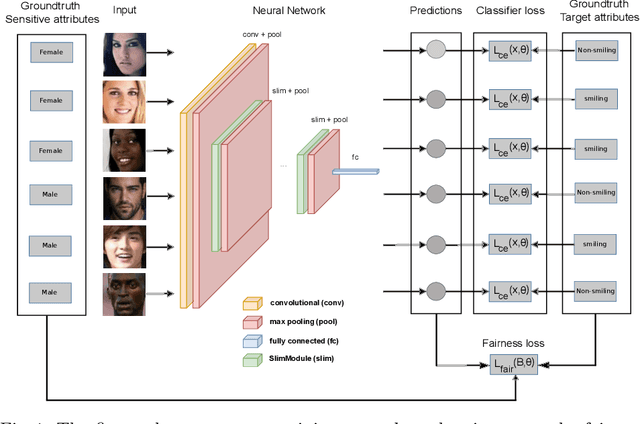
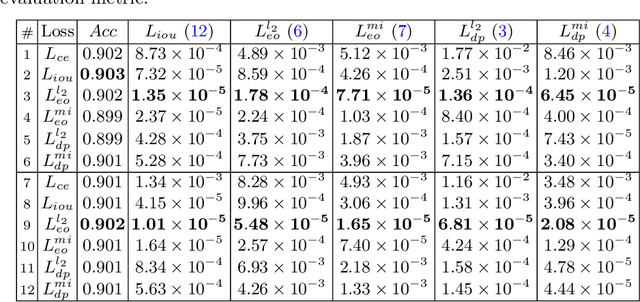
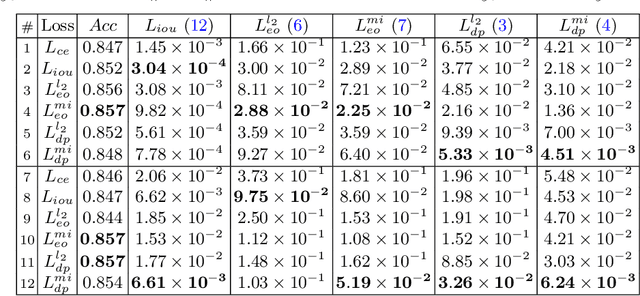
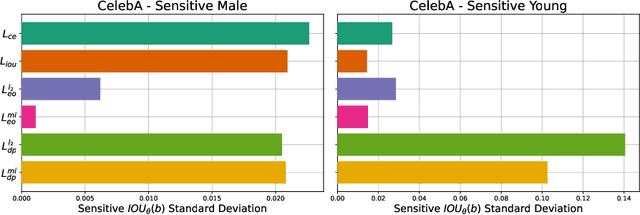
The performance of deep neural networks for image recognition tasks such as predicting a smiling face is known to degrade with under-represented classes of sensitive attributes. We address this problem by introducing fairness-aware regularization losses based on batch estimates of Demographic Parity, Equalized Odds, and a novel Intersection-over-Union measure. The experiments performed on facial and medical images from CelebA, UTKFace, and the SIIM-ISIC melanoma classification challenge show the effectiveness of our proposed fairness losses for bias mitigation as they improve model fairness while maintaining high classification performance. To the best of our knowledge, our work is the first attempt to incorporate these types of losses in an end-to-end training scheme for mitigating biases of visual attribute predictors. Our code is available at https://github.com/nish03/FVAP.
Fairness by Learning Orthogonal Disentangled Representations
Mar 22, 2020



Learning discriminative powerful representations is a crucial step for machine learning systems. Introducing invariance against arbitrary nuisance or sensitive attributes while performing well on specific tasks is an important problem in representation learning. This is mostly approached by purging the sensitive information from learned representations. In this paper, we propose a novel disentanglement approach to invariant representation problem. We disentangle the meaningful and sensitive representations by enforcing orthogonality constraints as a proxy for independence. We explicitly enforce the meaningful representation to be agnostic to sensitive information by entropy maximization. The proposed approach is evaluated on five publicly available datasets and compared with state of the art methods for learning fairness and invariance achieving the state of the art performance on three datasets and comparable performance on the rest. Further, we perform an ablative study to evaluate the effect of each component.
Deep Attention Based Semi-Supervised 2D-Pose Estimation for Surgical Instruments
Dec 10, 2019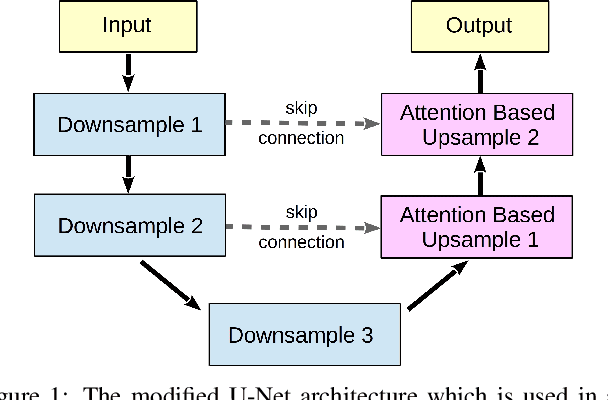
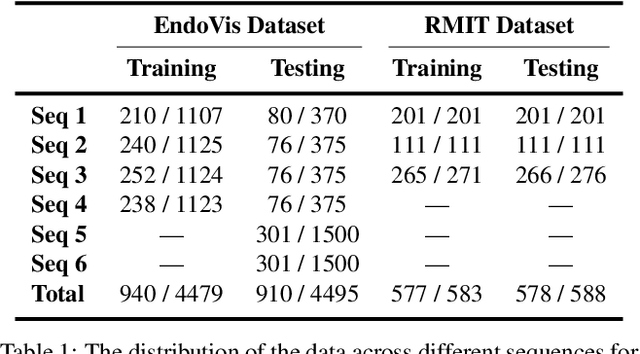
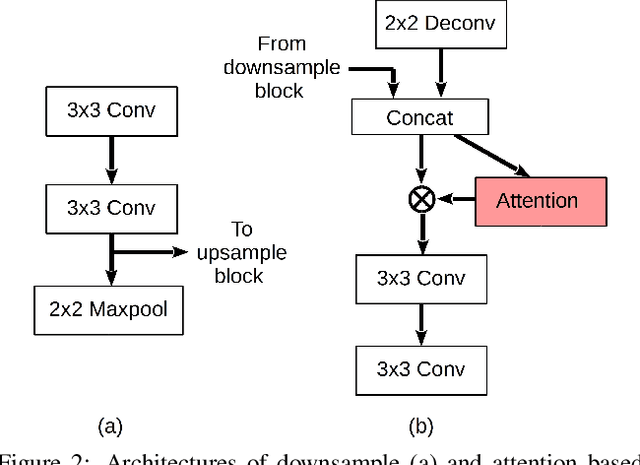
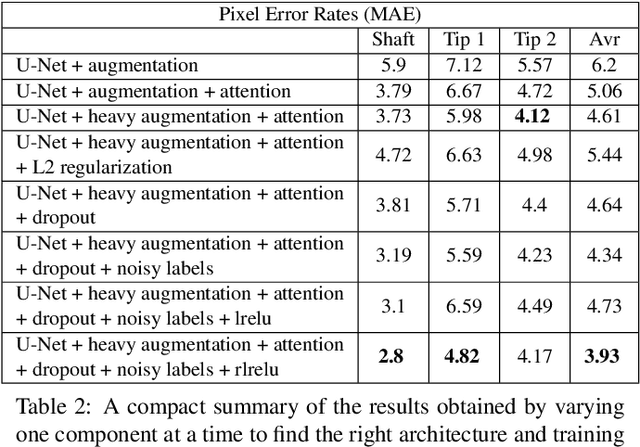
For many practical problems and applications, it is not feasible to create a vast and accurately labeled dataset, which restricts the application of deep learning in many areas. Semi-supervised learning algorithms intend to improve performance by also leveraging unlabeled data. This is very valuable for 2D-pose estimation task where data labeling requires substantial time and is subject to noise. This work aims to investigate if semi-supervised learning techniques can achieve acceptable performance level that makes using these algorithms during training justifiable. To this end, a lightweight network architecture is introduced and mean teacher, virtual adversarial training and pseudo-labeling algorithms are evaluated on 2D-pose estimation for surgical instruments. For the applicability of pseudo-labelling algorithm, we propose a novel confidence measure, total variation. Experimental results show that utilization of semi-supervised learning improves the performance on unseen geometries drastically while maintaining high accuracy for seen geometries. For RMIT benchmark, our lightweight architecture outperforms state-of-the-art with supervised learning. For Endovis benchmark, pseudo-labelling algorithm improves the supervised baseline achieving the new state-of-the-art performance.
Multi-scale Microaneurysms Segmentation Using Embedding Triplet Loss
Apr 18, 2019


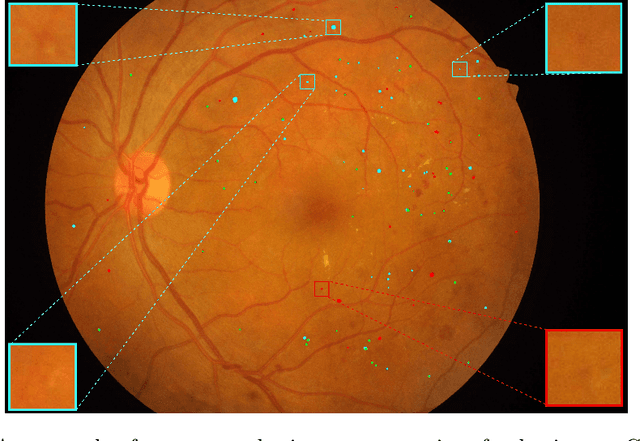
Deep learning techniques are recently being used in fundus image analysis and diabetic retinopathy detection. Microaneurysms are an important indicator of diabetic retinopathy progression. We introduce a two-stage deep learning approach for microaneurysms segmentation using multiple scales of the input with selective sampling and embedding triplet loss. The model first segments on two scales and then the segmentations are refined with a classification model. To enhance the discriminative power of the classification model, we incorporate triplet embedding loss with a selective sampling routine. The model is evaluated quantitatively to assess the segmentation performance and qualitatively to analyze the model predictions. This approach introduces a 30.29% relative improvement over the fully convolutional neural network.
Learning Interpretable Disentangled Representations using Adversarial VAEs
Apr 17, 2019
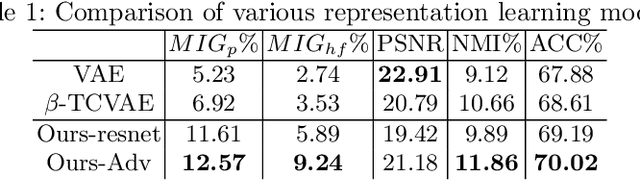
Learning Interpretable representation in medical applications is becoming essential for adopting data-driven models into clinical practice. It has been recently shown that learning a disentangled feature representation is important for a more compact and explainable representation of the data. In this paper, we introduce a novel adversarial variational autoencoder with a total correlation constraint to enforce independence on the latent representation while preserving the reconstruction fidelity. Our proposed method is validated on a publicly available dataset showing that the learned disentangled representation is not only interpretable, but also superior to the state-of-the-art methods. We report a relative improvement of 81.50% in terms of disentanglement, 11.60% in clustering, and 2% in supervised classification with a few amounts of labeled data.
Towards Robotic Eye Surgery: Marker-free, Online Hand-eye Calibration using Optical Coherence Tomography Images
Aug 17, 2018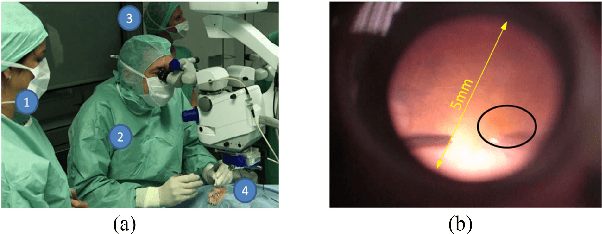
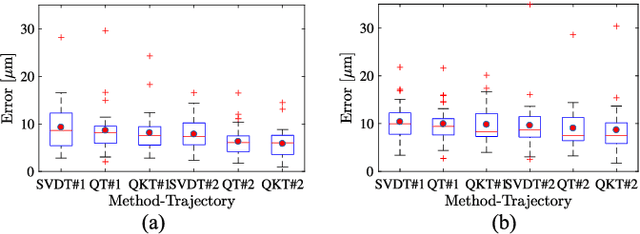
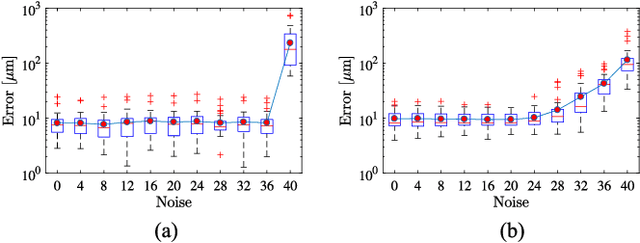
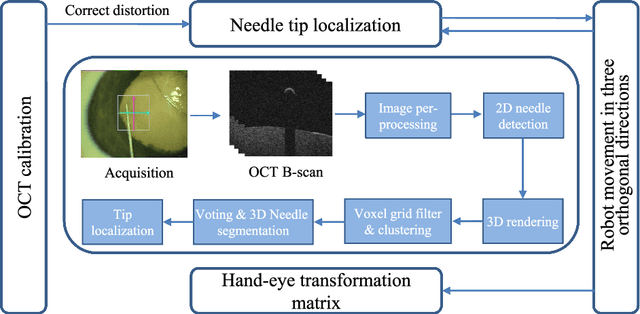
Ophthalmic microsurgery is known to be a challenging operation, which requires very precise and dexterous manipulation. Image guided robot-assisted surgery (RAS) is a promising solution that brings significant improvements in outcomes and reduces the physical limitations of human surgeons. However, this technology must be further developed before it can be routinely used in clinics. One of the problems is the lack of proper calibration between the robotic manipulator and appropriate imaging device. In this work, we developed a flexible framework for hand-eye calibration of an ophthalmic robot with a microscope-integrated Optical Coherence Tomography (MIOCT) without any markers. The proposed method consists of three main steps: a) we estimate the OCT calibration parameters; b) with micro-scale displacements controlled by the robot, we detect and segment the needle tip in 3D-OCT volume; c) we find the transformation between the coordinate system of the OCT camera and the coordinate system of the robot. We verified the capability of our framework in ex-vivo pig eye experiments and compared the results with a reference method (marker-based). In all experiments, our method showed a small difference from the marker based method, with a mean calibration error of 9.2 $\mu$m and 7.0 $\mu$m, respectively. Additionally, the noise test shows the robustness of the proposed method.
Fast 5DOF Needle Tracking in iOCT
Feb 18, 2018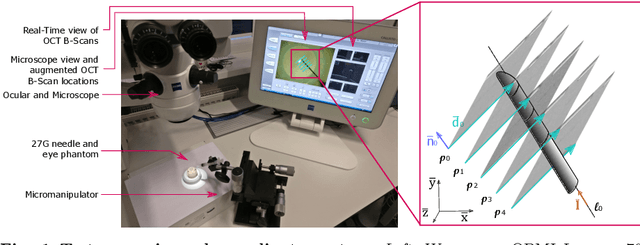
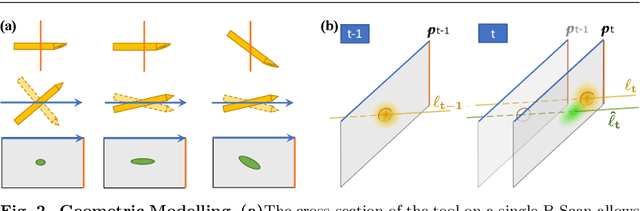
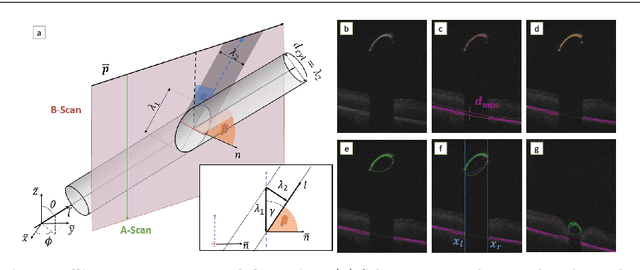
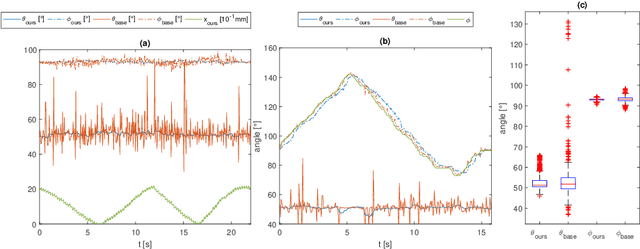
Purpose. Intraoperative Optical Coherence Tomography (iOCT) is an increasingly available imaging technique for ophthalmic microsurgery that provides high-resolution cross-sectional information of the surgical scene. We propose to build on its desirable qualities and present a method for tracking the orientation and location of a surgical needle. Thereby, we enable direct analysis of instrument-tissue interaction directly in OCT space without complex multimodal calibration that would be required with traditional instrument tracking methods. Method. The intersection of the needle with the iOCT scan is detected by a peculiar multi-step ellipse fitting that takes advantage of the directionality of the modality. The geometric modelling allows us to use the ellipse parameters and provide them into a latency aware estimator to infer the 5DOF pose during needle movement. Results. Experiments on phantom data and ex-vivo porcine eyes indicate that the algorithm retains angular precision especially during lateral needle movement and provides a more robust and consistent estimation than baseline methods. Conclusion. Using solely crosssectional iOCT information, we are able to successfully and robustly estimate a 5DOF pose of the instrument in less than 5.5 ms on a CPU.
Concurrent Segmentation and Localization for Tracking of Surgical Instruments
Aug 01, 2017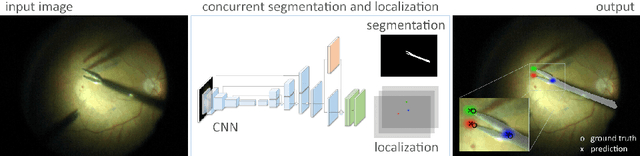
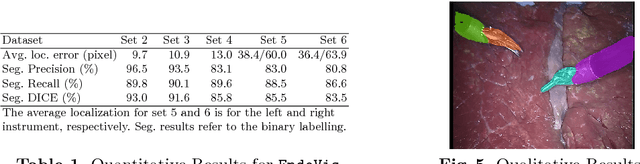
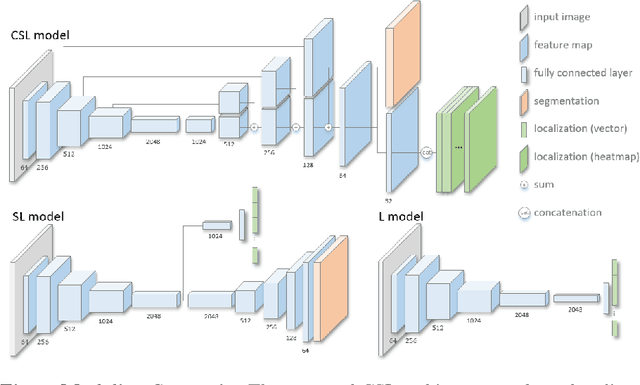
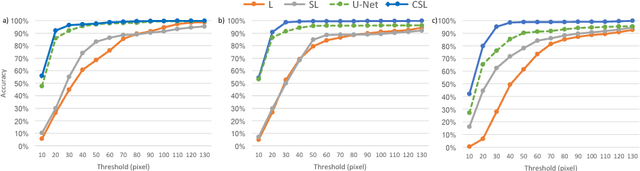
Real-time instrument tracking is a crucial requirement for various computer-assisted interventions. In order to overcome problems such as specular reflections and motion blur, we propose a novel method that takes advantage of the interdependency between localization and segmentation of the surgical tool. In particular, we reformulate the 2D instrument pose estimation as heatmap regression and thereby enable a concurrent, robust and near real-time regression of both tasks via deep learning. As demonstrated by our experimental results, this modeling leads to a significantly improved performance than directly regressing the tool position and allows our method to outperform the state of the art on a Retinal Microsurgery benchmark and the MICCAI EndoVis Challenge 2015.