 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTacUMI: A Multi-Modal Universal Manipulation Interface for Contact-Rich Tasks
Jan 21, 2026Task decomposition is critical for understanding and learning complex long-horizon manipulation tasks. Especially for tasks involving rich physical interactions, relying solely on visual observations and robot proprioceptive information often fails to reveal the underlying event transitions. This raises the requirement for efficient collection of high-quality multi-modal data as well as robust segmentation method to decompose demonstrations into meaningful modules. Building on the idea of the handheld demonstration device Universal Manipulation Interface (UMI), we introduce TacUMI, a multi-modal data collection system that integrates additionally ViTac sensors, force-torque sensor, and pose tracker into a compact, robot-compatible gripper design, which enables synchronized acquisition of all these modalities during human demonstrations. We then propose a multi-modal segmentation framework that leverages temporal models to detect semantically meaningful event boundaries in sequential manipulations. Evaluation on a challenging cable mounting task shows more than 90 percent segmentation accuracy and highlights a remarkable improvement with more modalities, which validates that TacUMI establishes a practical foundation for both scalable collection and segmentation of multi-modal demonstrations in contact-rich tasks.
Towards Robotic Eye Surgery: Marker-free, Online Hand-eye Calibration using Optical Coherence Tomography Images
Aug 17, 2018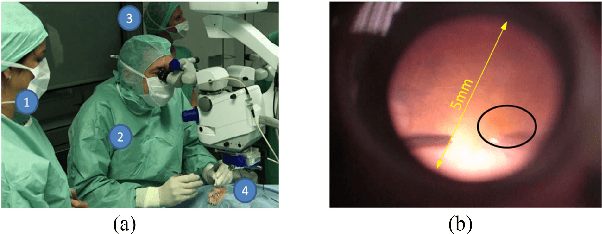
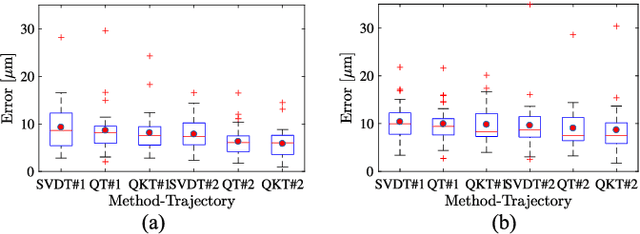
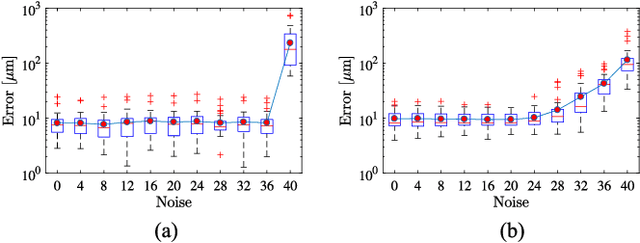
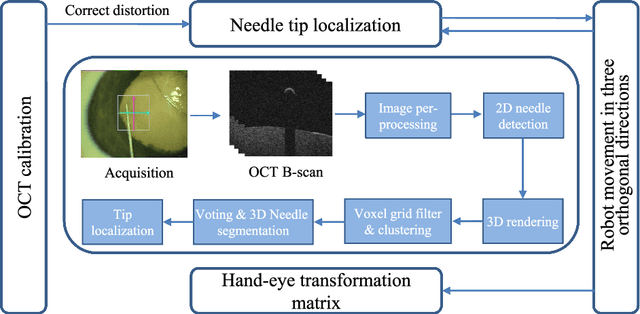
Ophthalmic microsurgery is known to be a challenging operation, which requires very precise and dexterous manipulation. Image guided robot-assisted surgery (RAS) is a promising solution that brings significant improvements in outcomes and reduces the physical limitations of human surgeons. However, this technology must be further developed before it can be routinely used in clinics. One of the problems is the lack of proper calibration between the robotic manipulator and appropriate imaging device. In this work, we developed a flexible framework for hand-eye calibration of an ophthalmic robot with a microscope-integrated Optical Coherence Tomography (MIOCT) without any markers. The proposed method consists of three main steps: a) we estimate the OCT calibration parameters; b) with micro-scale displacements controlled by the robot, we detect and segment the needle tip in 3D-OCT volume; c) we find the transformation between the coordinate system of the OCT camera and the coordinate system of the robot. We verified the capability of our framework in ex-vivo pig eye experiments and compared the results with a reference method (marker-based). In all experiments, our method showed a small difference from the marker based method, with a mean calibration error of 9.2 $\mu$m and 7.0 $\mu$m, respectively. Additionally, the noise test shows the robustness of the proposed method.