 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTotalVibeSegmentator: Full Torso Segmentation for the NAKO and UK Biobank in Volumetric Interpolated Breath-hold Examination Body Images
May 31, 2024



Objectives: To present a publicly available torso segmentation network for large epidemiology datasets on volumetric interpolated breath-hold examination (VIBE) images. Materials & Methods: We extracted preliminary segmentations from TotalSegmentator, spine, and body composition networks for VIBE images, then improved them iteratively and retrained a nnUNet network. Using subsets of NAKO (85 subjects) and UK Biobank (16 subjects), we evaluated with Dice-score on a holdout set (12 subjects) and existing organ segmentation approach (1000 subjects), generating 71 semantic segmentation types for VIBE images. We provide an additional network for the vertebra segments 22 individual vertebra types. Results: We achieved an average Dice score of 0.89 +- 0.07 overall 71 segmentation labels. We scored > 0.90 Dice-score on the abdominal organs except for the pancreas with a Dice of 0.70. Conclusion: Our work offers a detailed and refined publicly available full torso segmentation on VIBE images.
Deep Direct Volume Rendering: Learning Visual Feature Mappings From Exemplary Images
Jun 09, 2021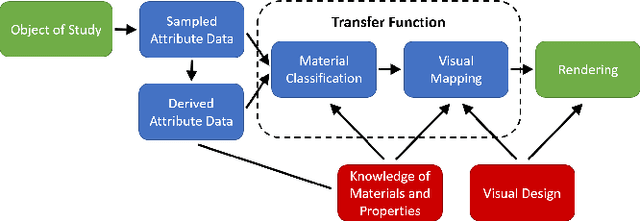
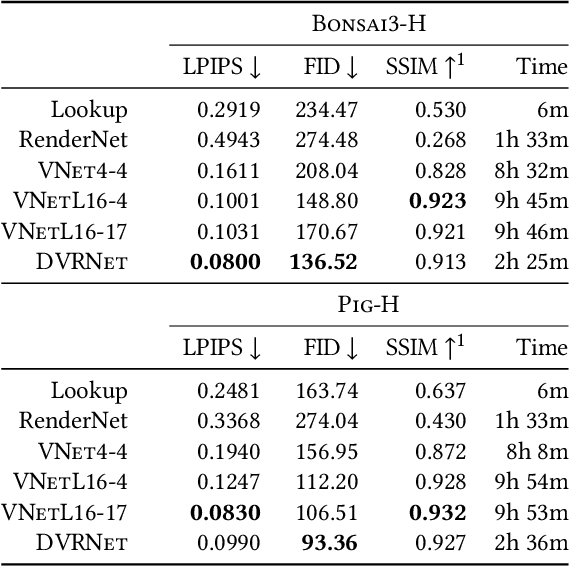
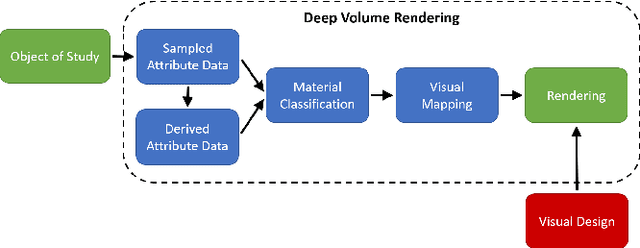
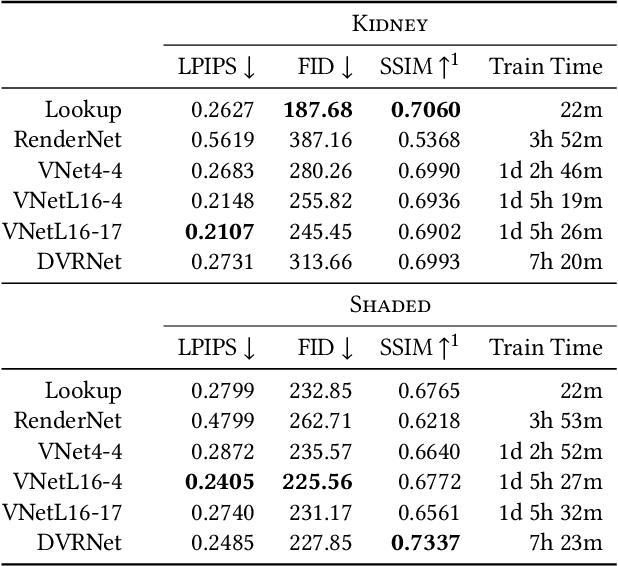
Volume Rendering is an important technique for visualizing three-dimensional scalar data grids and is commonly employed for scientific and medical image data. Direct Volume Rendering (DVR) is a well established and efficient rendering algorithm for volumetric data. Neural rendering uses deep neural networks to solve inverse rendering tasks and applies techniques similar to DVR. However, it has not been demonstrated successfully for the rendering of scientific volume data. In this work, we introduce Deep Direct Volume Rendering (DeepDVR), a generalization of DVR that allows for the integration of deep neural networks into the DVR algorithm. We conceptualize the rendering in a latent color space, thus enabling the use of deep architectures to learn implicit mappings for feature extraction and classification, replacing explicit feature design and hand-crafted transfer functions. Our generalization serves to derive novel volume rendering architectures that can be trained end-to-end directly from examples in image space, obviating the need to manually define and fine-tune multidimensional transfer functions while providing superior classification strength. We further introduce a novel stepsize annealing scheme to accelerate the training of DeepDVR models and validate its effectiveness in a set of experiments. We validate our architectures on two example use cases: (1) learning an optimized rendering from manually adjusted reference images for a single volume and (2) learning advanced visualization concepts like shading and semantic colorization that generalize to unseen volume data. We find that deep volume rendering architectures with explicit modeling of the DVR pipeline effectively enable end-to-end learning of scientific volume rendering tasks from target images.
Towards Robotic Eye Surgery: Marker-free, Online Hand-eye Calibration using Optical Coherence Tomography Images
Aug 17, 2018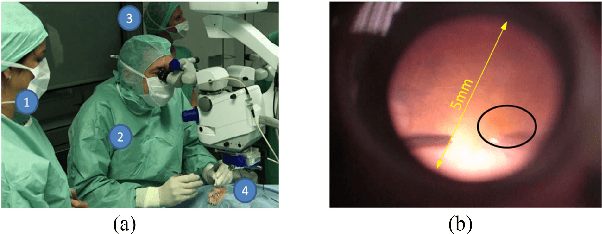
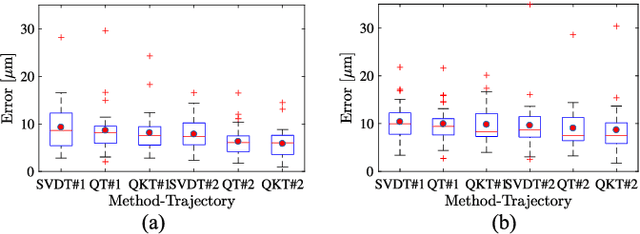
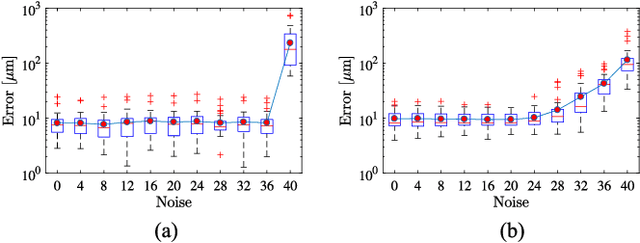
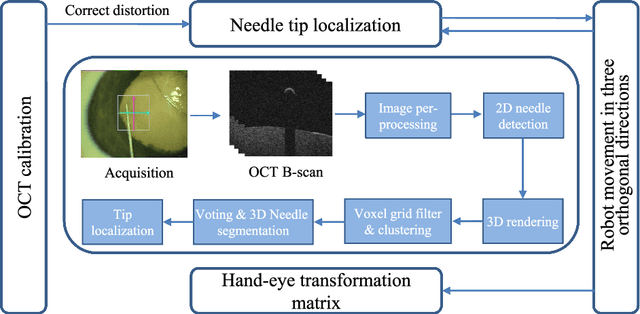
Ophthalmic microsurgery is known to be a challenging operation, which requires very precise and dexterous manipulation. Image guided robot-assisted surgery (RAS) is a promising solution that brings significant improvements in outcomes and reduces the physical limitations of human surgeons. However, this technology must be further developed before it can be routinely used in clinics. One of the problems is the lack of proper calibration between the robotic manipulator and appropriate imaging device. In this work, we developed a flexible framework for hand-eye calibration of an ophthalmic robot with a microscope-integrated Optical Coherence Tomography (MIOCT) without any markers. The proposed method consists of three main steps: a) we estimate the OCT calibration parameters; b) with micro-scale displacements controlled by the robot, we detect and segment the needle tip in 3D-OCT volume; c) we find the transformation between the coordinate system of the OCT camera and the coordinate system of the robot. We verified the capability of our framework in ex-vivo pig eye experiments and compared the results with a reference method (marker-based). In all experiments, our method showed a small difference from the marker based method, with a mean calibration error of 9.2 $\mu$m and 7.0 $\mu$m, respectively. Additionally, the noise test shows the robustness of the proposed method.
Fast 5DOF Needle Tracking in iOCT
Feb 18, 2018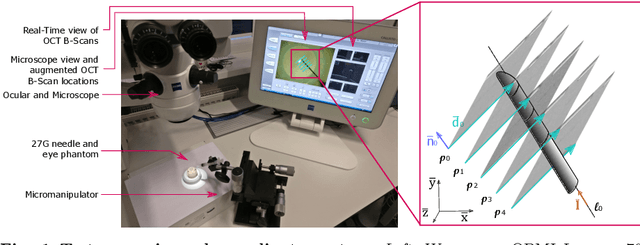
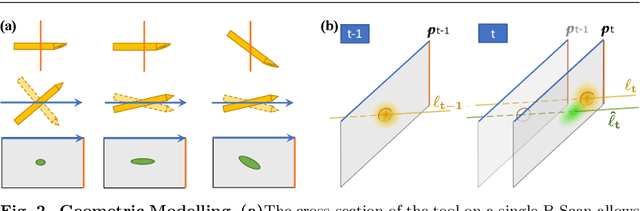
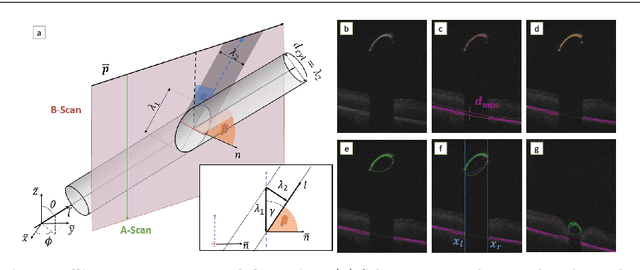
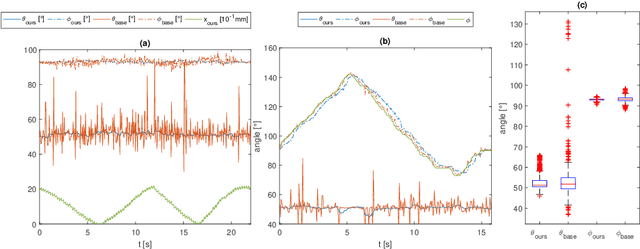
Purpose. Intraoperative Optical Coherence Tomography (iOCT) is an increasingly available imaging technique for ophthalmic microsurgery that provides high-resolution cross-sectional information of the surgical scene. We propose to build on its desirable qualities and present a method for tracking the orientation and location of a surgical needle. Thereby, we enable direct analysis of instrument-tissue interaction directly in OCT space without complex multimodal calibration that would be required with traditional instrument tracking methods. Method. The intersection of the needle with the iOCT scan is detected by a peculiar multi-step ellipse fitting that takes advantage of the directionality of the modality. The geometric modelling allows us to use the ellipse parameters and provide them into a latency aware estimator to infer the 5DOF pose during needle movement. Results. Experiments on phantom data and ex-vivo porcine eyes indicate that the algorithm retains angular precision especially during lateral needle movement and provides a more robust and consistent estimation than baseline methods. Conclusion. Using solely crosssectional iOCT information, we are able to successfully and robustly estimate a 5DOF pose of the instrument in less than 5.5 ms on a CPU.