 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeChainLearn: A Blockchain-Based Capacity-Aware Framework for Federated Ensemble Learning
May 23, 2026Federated learning is used in medical imaging where privacy prohibits centralizing data. Standard federated algorithms assume homogeneous hardware, identical architectures, and centralized aggregation, which fails when hospitals have unequal compute resources. We propose capacity-aware coordination: measure each hospital's throughput, assign capacity-appropriate architectures (MobileNetV3-Small, EfficientNet-B0, ResNet-50), and combine predictions via weighted ensemble. Weak and strong hospitals can participate without forcing uniform architectures. We separate on-chain policy from off-chain learning. A Solidity contract stores hospital registration, benchmark hashes, metrics, and weights. Hospitals train locally and submit only hashes and scalars (not parameters). Weighted ensemble inference is computed off-chain. Experiments on PneumoniaMNIST and DermaMNIST (5 seeds, 3 non-IID levels) show our method achieves lower or equal calibration error versus equal-weight ensemble and competitive accuracy versus FedAvg, FedProx, and FedMD. Communication overhead is 224 bytes per round, a reduction of over 912,000x compared to FedAvg.
TacUMI: A Multi-Modal Universal Manipulation Interface for Contact-Rich Tasks
Jan 21, 2026Task decomposition is critical for understanding and learning complex long-horizon manipulation tasks. Especially for tasks involving rich physical interactions, relying solely on visual observations and robot proprioceptive information often fails to reveal the underlying event transitions. This raises the requirement for efficient collection of high-quality multi-modal data as well as robust segmentation method to decompose demonstrations into meaningful modules. Building on the idea of the handheld demonstration device Universal Manipulation Interface (UMI), we introduce TacUMI, a multi-modal data collection system that integrates additionally ViTac sensors, force-torque sensor, and pose tracker into a compact, robot-compatible gripper design, which enables synchronized acquisition of all these modalities during human demonstrations. We then propose a multi-modal segmentation framework that leverages temporal models to detect semantically meaningful event boundaries in sequential manipulations. Evaluation on a challenging cable mounting task shows more than 90 percent segmentation accuracy and highlights a remarkable improvement with more modalities, which validates that TacUMI establishes a practical foundation for both scalable collection and segmentation of multi-modal demonstrations in contact-rich tasks.
OpenAI GPT-5 System Card
Dec 19, 2025This is the system card published alongside the OpenAI GPT-5 launch, August 2025. GPT-5 is a unified system with a smart and fast model that answers most questions, a deeper reasoning model for harder problems, and a real-time router that quickly decides which model to use based on conversation type, complexity, tool needs, and explicit intent (for example, if you say 'think hard about this' in the prompt). The router is continuously trained on real signals, including when users switch models, preference rates for responses, and measured correctness, improving over time. Once usage limits are reached, a mini version of each model handles remaining queries. This system card focuses primarily on gpt-5-thinking and gpt-5-main, while evaluations for other models are available in the appendix. The GPT-5 system not only outperforms previous models on benchmarks and answers questions more quickly, but -- more importantly -- is more useful for real-world queries. We've made significant advances in reducing hallucinations, improving instruction following, and minimizing sycophancy, and have leveled up GPT-5's performance in three of ChatGPT's most common uses: writing, coding, and health. All of the GPT-5 models additionally feature safe-completions, our latest approach to safety training to prevent disallowed content. Similarly to ChatGPT agent, we have decided to treat gpt-5-thinking as High capability in the Biological and Chemical domain under our Preparedness Framework, activating the associated safeguards. While we do not have definitive evidence that this model could meaningfully help a novice to create severe biological harm -- our defined threshold for High capability -- we have chosen to take a precautionary approach.
SpectralKrum: A Spectral-Geometric Defense Against Byzantine Attacks in Federated Learning
Dec 12, 2025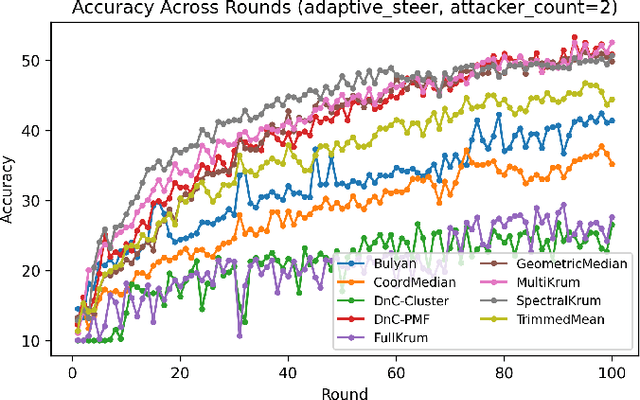



Federated Learning (FL) distributes model training across clients who retain their data locally, but this architecture exposes a fundamental vulnerability: Byzantine clients can inject arbitrarily corrupted updates that degrade or subvert the global model. While robust aggregation methods (including Krum, Bulyan, and coordinate-wise defenses) offer theoretical guarantees under idealized assumptions, their effectiveness erodes substantially when client data distributions are heterogeneous (non-IID) and adversaries can observe or approximate the defense mechanism. This paper introduces SpectralKrum, a defense that fuses spectral subspace estimation with geometric neighbor-based selection. The core insight is that benign optimization trajectories, despite per-client heterogeneity, concentrate near a low-dimensional manifold that can be estimated from historical aggregates. SpectralKrum projects incoming updates into this learned subspace, applies Krum selection in compressed coordinates, and filters candidates whose orthogonal residual energy exceeds a data-driven threshold. The method requires no auxiliary data, operates entirely on model updates, and preserves FL privacy properties. We evaluate SpectralKrum against eight robust baselines across seven attack scenarios on CIFAR-10 with Dirichlet-distributed non-IID partitions (alpha = 0.1). Experiments spanning over 56,000 training rounds show that SpectralKrum is competitive against directional and subspace-aware attacks (adaptive-steer, buffer-drift), but offers limited advantage under label-flip and min-max attacks where malicious updates remain spectrally indistinguishable from benign ones.
Dynamic Grasping of Unknown Objects with a Multi-Fingered Hand
Oct 27, 2023



An important prerequisite for autonomous robots is their ability to reliably grasp a wide variety of objects. Most state-of-the-art systems employ specialized or simple end-effectors, such as two-jaw grippers, which severely limit the range of objects to manipulate. Additionally, they conventionally require a structured and fully predictable environment while the vast majority of our world is complex, unstructured, and dynamic. This paper presents an implementation to overcome both issues. Firstly, the integration of a five-finger hand enhances the variety of possible grasps and manipulable objects. This kinematically complex end-effector is controlled by a deep learning based generative grasping network. The required virtual model of the unknown target object is iteratively completed by processing visual sensor data. Secondly, this visual feedback is employed to realize closed-loop servo control which compensates for external disturbances. Our experiments on real hardware confirm the system's capability to reliably grasp unknown dynamic target objects without a priori knowledge of their trajectories. To the best of our knowledge, this is the first method to achieve dynamic multi-fingered grasping for unknown objects. A video of the experiments is available at https://youtu.be/Ut28yM1gnvI.
A dataset of continuous affect annotations and physiological signals for emotion analysis
Dec 06, 2018
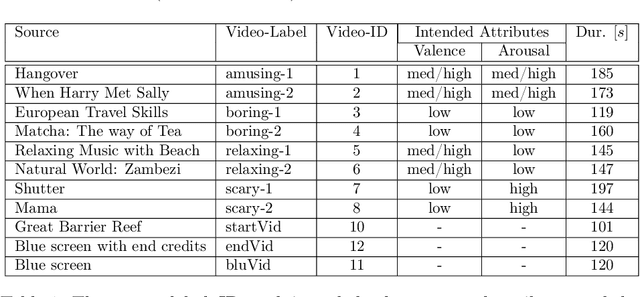
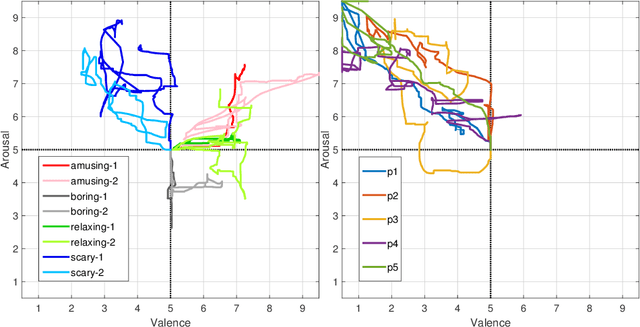
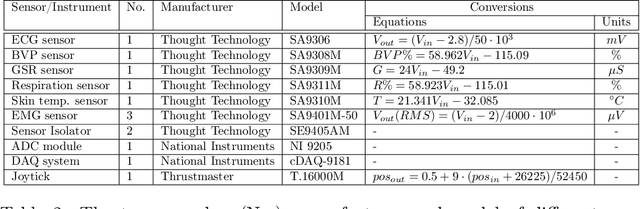
From a computational viewpoint, emotions continue to be intriguingly hard to understand. In research, direct, real-time inspection in realistic settings is not possible. Discrete, indirect, post-hoc recordings are therefore the norm. As a result, proper emotion assessment remains a problematic issue. The Continuously Annotated Signals of Emotion (CASE) dataset provides a solution as it focusses on real-time continuous annotation of emotions, as experienced by the participants, while watching various videos. For this purpose, a novel, intuitive joystick-based annotation interface was developed, that allowed for simultaneous reporting of valence and arousal, that are instead often annotated independently. In parallel, eight high quality, synchronized physiological recordings (1000 Hz, 16-bit ADC) were made of ECG, BVP, EMG (3x), GSR (or EDA), respiration and skin temperature. The dataset consists of the physiological and annotation data from 30 participants, 15 male and 15 female, who watched several validated video-stimuli. The validity of the emotion induction, as exemplified by the annotation and physiological data, is also presented.
Automated Image Captioning for Rapid Prototyping and Resource Constrained Environments
Jun 04, 2016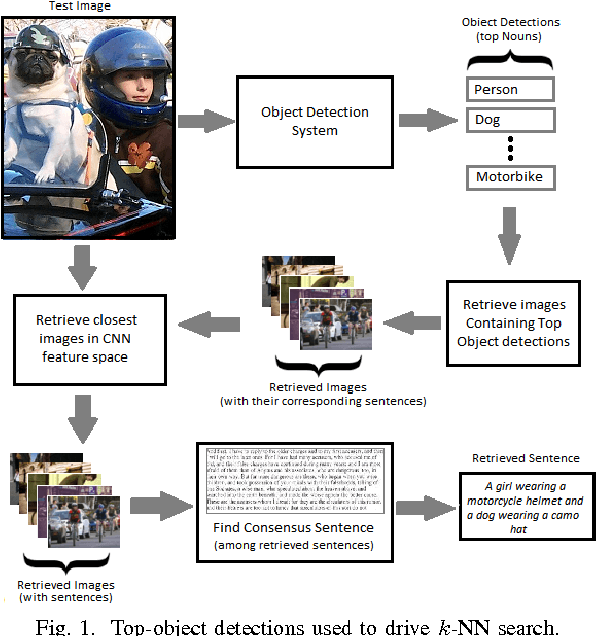

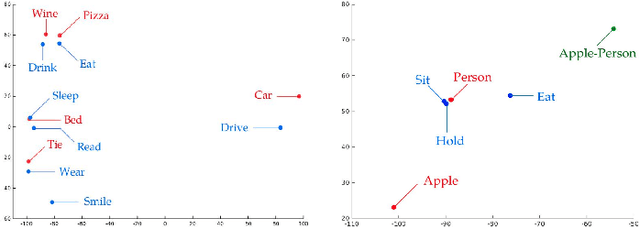

Significant performance gains in deep learning coupled with the exponential growth of image and video data on the Internet have resulted in the recent emergence of automated image captioning systems. Ensuring scalability of automated image captioning systems with respect to the ever increasing volume of image and video data is a significant challenge. This paper provides a valuable insight in that the detection of a few significant (top) objects in an image allows one to extract other relevant information such as actions (verbs) in the image. We expect this insight to be useful in the design of scalable image captioning systems. We address two parameters by which the scalability of image captioning systems could be quantified, i.e., the traditional algorithmic time complexity which is important given the resource limitations of the user device and the system development time since the programmers' time is a critical resource constraint in many real-world scenarios. Additionally, we address the issue of how word embeddings could be used to infer the verb (action) from the nouns (objects) in a given image in a zero-shot manner. Our results show that it is possible to attain reasonably good performance on predicting actions and captioning images using our approaches with the added advantage of simplicity of implementation.