 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutomated Image Captioning for Rapid Prototyping and Resource Constrained Environments
Paper and Code
Jun 04, 2016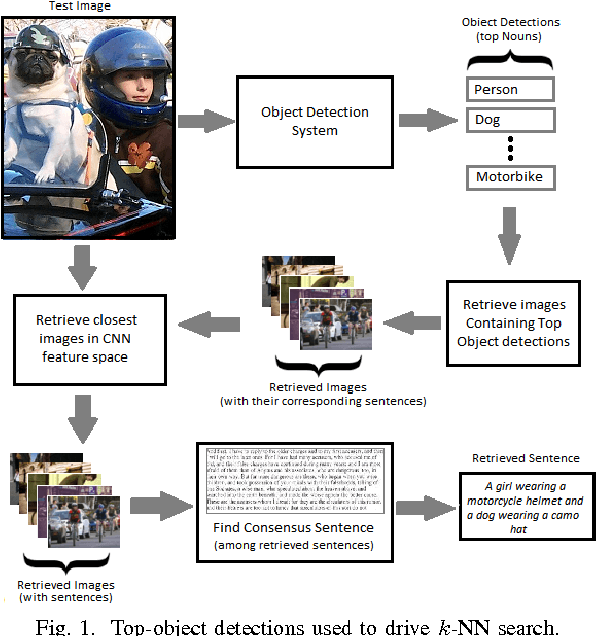

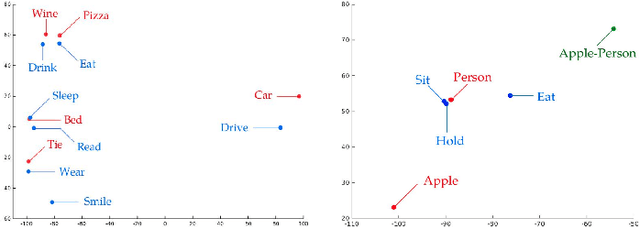

Significant performance gains in deep learning coupled with the exponential growth of image and video data on the Internet have resulted in the recent emergence of automated image captioning systems. Ensuring scalability of automated image captioning systems with respect to the ever increasing volume of image and video data is a significant challenge. This paper provides a valuable insight in that the detection of a few significant (top) objects in an image allows one to extract other relevant information such as actions (verbs) in the image. We expect this insight to be useful in the design of scalable image captioning systems. We address two parameters by which the scalability of image captioning systems could be quantified, i.e., the traditional algorithmic time complexity which is important given the resource limitations of the user device and the system development time since the programmers' time is a critical resource constraint in many real-world scenarios. Additionally, we address the issue of how word embeddings could be used to infer the verb (action) from the nouns (objects) in a given image in a zero-shot manner. Our results show that it is possible to attain reasonably good performance on predicting actions and captioning images using our approaches with the added advantage of simplicity of implementation.