 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge3D Object Detection on Point Clouds using Local Ground-aware and Adaptive Representation of scenes' surface
Feb 02, 2020



A novel, adaptive ground-aware, and cost-effective 3D Object Detection pipeline is proposed. The ground surface representation introduced in this paper, in comparison to its uni-planar counterparts (methods that model the surface of a whole 3D scene using single plane), is far more accurate while being ~10x faster. The novelty of the ground representation lies both in the way in which the ground surface of the scene is represented in Lidar perception problems, as well as in the (cost-efficient) way in which it is computed. Furthermore, the proposed object detection pipeline builds on the traditional two-stage object detection models by incorporating the ability to dynamically reason the surface of the scene, ultimately achieving a new state-of-the-art 3D object detection performance among the two-stage Lidar Object Detection pipelines.
Matching Disparate Image Pairs Using Shape-Aware ConvNets
Nov 24, 2018



An end-to-end trainable ConvNet architecture, that learns to harness the power of shape representation for matching disparate image pairs, is proposed. Disparate image pairs are deemed those that exhibit strong affine variations in scale, viewpoint and projection parameters accompanied by the presence of partial or complete occlusion of objects and extreme variations in ambient illumination. Under these challenging conditions, neither local nor global feature-based image matching methods, when used in isolation, have been observed to be effective. The proposed correspondence determination scheme for matching disparate images exploits high-level shape cues that are derived from low-level local feature descriptors, thus combining the best of both worlds. A graph-based representation for the disparate image pair is generated by constructing an affinity matrix that embeds the distances between feature points in two images, thus modeling the correspondence determination problem as one of graph matching. The eigenspectrum of the affinity matrix, i.e., the learned global shape representation, is then used to further regress the transformation or homography that defines the correspondence between the source image and target image. The proposed scheme is shown to yield state-of-the-art results for both, coarse-level shape matching as well as fine point-wise correspondence determination.
Deep Spectral Correspondence for Matching Disparate Image Pairs
Sep 12, 2018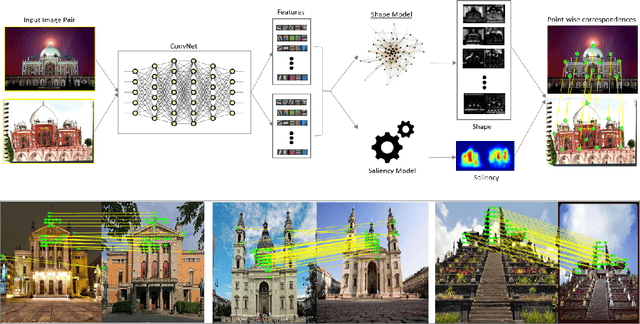
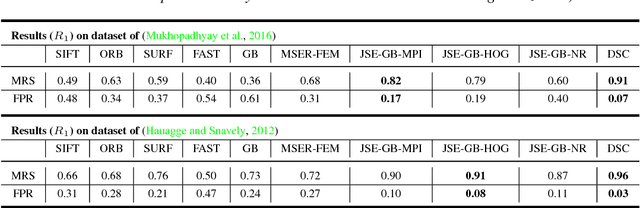

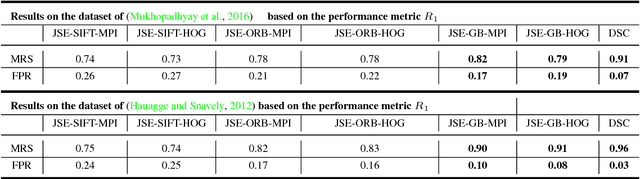
A novel, non-learning-based, saliency-aware, shape-cognizant correspondence determination technique is proposed for matching image pairs that are significantly disparate in nature. Images in the real world often exhibit high degrees of variation in scale, orientation, viewpoint, illumination and affine projection parameters, and are often accompanied by the presence of textureless regions and complete or partial occlusion of scene objects. The above conditions confound most correspondence determination techniques by rendering impractical the use of global contour-based descriptors or local pixel-level features for establishing correspondence. The proposed deep spectral correspondence (DSC) determination scheme harnesses the representational power of local feature descriptors to derive a complex high-level global shape representation for matching disparate images. The proposed scheme reasons about correspondence between disparate images using high-level global shape cues derived from low-level local feature descriptors. Consequently, the proposed scheme enjoys the best of both worlds, i.e., a high degree of invariance to affine parameters such as scale, orientation, viewpoint, illumination afforded by the global shape cues and robustness to occlusion provided by the low-level feature descriptors. While the shape-based component within the proposed scheme infers what to look for, an additional saliency-based component dictates where to look at thereby tackling the noisy correspondences arising from the presence of textureless regions and complex backgrounds. In the proposed scheme, a joint image graph is constructed using distances computed between interest points in the appearance (i.e., image) space. Eigenspectral decomposition of the joint image graph allows for reasoning about shape similarity to be performed jointly, in the appearance space and eigenspace.
Automated Image Captioning for Rapid Prototyping and Resource Constrained Environments
Jun 04, 2016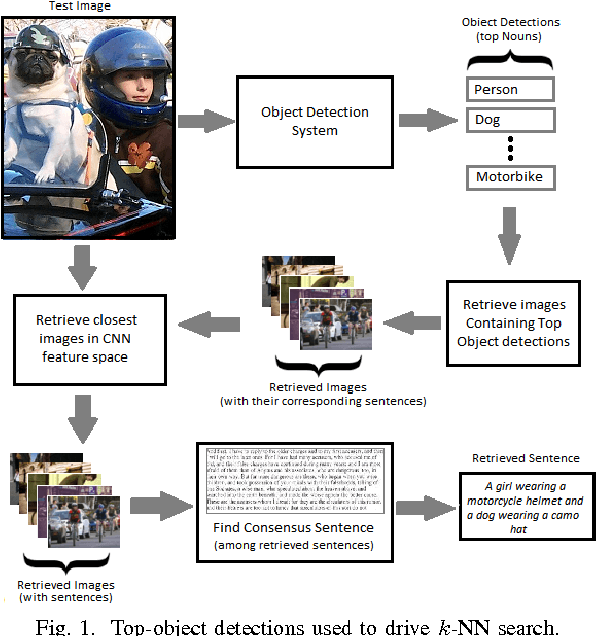

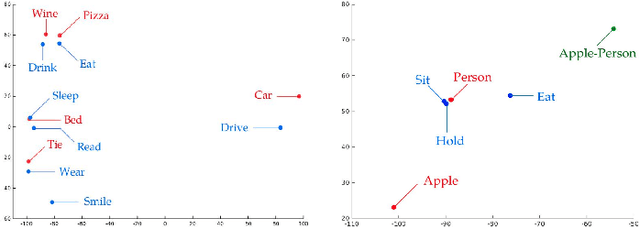

Significant performance gains in deep learning coupled with the exponential growth of image and video data on the Internet have resulted in the recent emergence of automated image captioning systems. Ensuring scalability of automated image captioning systems with respect to the ever increasing volume of image and video data is a significant challenge. This paper provides a valuable insight in that the detection of a few significant (top) objects in an image allows one to extract other relevant information such as actions (verbs) in the image. We expect this insight to be useful in the design of scalable image captioning systems. We address two parameters by which the scalability of image captioning systems could be quantified, i.e., the traditional algorithmic time complexity which is important given the resource limitations of the user device and the system development time since the programmers' time is a critical resource constraint in many real-world scenarios. Additionally, we address the issue of how word embeddings could be used to infer the verb (action) from the nouns (objects) in a given image in a zero-shot manner. Our results show that it is possible to attain reasonably good performance on predicting actions and captioning images using our approaches with the added advantage of simplicity of implementation.