 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMachine Failure Detection Based on Projected Quantum Models
Jan 22, 2026Detecting machine failures promptly is of utmost importance in industry for maintaining efficiency and minimizing downtime. This paper introduces a failure detection algorithm based on quantum computing and a statistical change-point detection approach. Our method leverages the potential of projected quantum feature maps to enhance the precision of anomaly detection in machine monitoring systems. We empirically validate our approach on benchmark multi-dimensional time series datasets as well as on a real-world dataset comprising IoT sensor readings from operational machines, ensuring the practical relevance of our study. The algorithm was executed on IBM's 133-qubit Heron quantum processor, demonstrating the feasibility of integrating quantum computing into industrial maintenance procedures. The presented results underscore the effectiveness of our quantum-based failure detection system, showcasing its capability to accurately identify anomalies in noisy time series data. This work not only highlights the potential of quantum computing in industrial diagnostics but also paves the way for more sophisticated quantum algorithms in the realm of predictive maintenance.
rECGnition_v2.0: Self-Attentive Canonical Fusion of ECG and Patient Data using deep learning for effective Cardiac Diagnostics
Feb 22, 2025



The variability in ECG readings influenced by individual patient characteristics has posed a considerable challenge to adopting automated ECG analysis in clinical settings. A novel feature fusion technique termed SACC (Self Attentive Canonical Correlation) was proposed to address this. This technique is combined with DPN (Dual Pathway Network) and depth-wise separable convolution to create a robust, interpretable, and fast end-to-end arrhythmia classification model named rECGnition_v2.0 (robust ECG abnormality detection). This study uses MIT-BIH, INCARTDB and EDB dataset to evaluate the efficiency of rECGnition_v2.0 for various classes of arrhythmias. To investigate the influence of constituting model components, various ablation studies were performed, i.e. simple concatenation, CCA and proposed SACC were compared, while the importance of global and local ECG features were tested using DPN rECGnition_v2.0 model and vice versa. It was also benchmarked with state-of-the-art CNN models for overall accuracy vs model parameters, FLOPs, memory requirements, and prediction time. Furthermore, the inner working of the model was interpreted by comparing the activation locations in ECG before and after the SACC layer. rECGnition_v2.0 showed a remarkable accuracy of 98.07% and an F1-score of 98.05% for classifying ten distinct classes of arrhythmia with just 82.7M FLOPs per sample, thereby going beyond the performance metrics of current state-of-the-art (SOTA) models by utilizing MIT-BIH Arrhythmia dataset. Similarly, on INCARTDB and EDB datasets, excellent F1-scores of 98.01% and 96.21% respectively was achieved for AAMI classification. The compact architectural footprint of the rECGnition_v2.0, characterized by its lesser trainable parameters and diminished computational demands, unfurled several advantages including interpretability and scalability.
Synthesizing Scientific Summaries: An Extractive and Abstractive Approach
Jul 29, 2024



The availability of a vast array of research papers in any area of study, necessitates the need of automated summarisation systems that can present the key research conducted and their corresponding findings. Scientific paper summarisation is a challenging task for various reasons including token length limits in modern transformer models and corresponding memory and compute requirements for long text. A significant amount of work has been conducted in this area, with approaches that modify the attention mechanisms of existing transformer models and others that utilise discourse information to capture long range dependencies in research papers. In this paper, we propose a hybrid methodology for research paper summarisation which incorporates an extractive and abstractive approach. We use the extractive approach to capture the key findings of research, and pair it with the introduction of the paper which captures the motivation for research. We use two models based on unsupervised learning for the extraction stage and two transformer language models, resulting in four combinations for our hybrid approach. The performances of the models are evaluated on three metrics and we present our findings in this paper. We find that using certain combinations of hyper parameters, it is possible for automated summarisation systems to exceed the abstractiveness of summaries written by humans. Finally, we state our future scope of research in extending this methodology to summarisation of generalised long documents.
Exploring Answer Information Methods for Question Generation with Transformers
Dec 06, 2023There has been a lot of work in question generation where different methods to provide target answers as input, have been employed. This experimentation has been mostly carried out for RNN based models. We use three different methods and their combinations for incorporating answer information and explore their effect on several automatic evaluation metrics. The methods that are used are answer prompting, using a custom product method using answer embeddings and encoder outputs, choosing sentences from the input paragraph that have answer related information, and using a separate cross-attention attention block in the decoder which attends to the answer. We observe that answer prompting without any additional modes obtains the best scores across rouge, meteor scores. Additionally, we use a custom metric to calculate how many of the generated questions have the same answer, as the answer which is used to generate them.
RECOVER: sequential model optimization platform for combination drug repurposing identifies novel synergistic compounds in vitro
Feb 07, 2022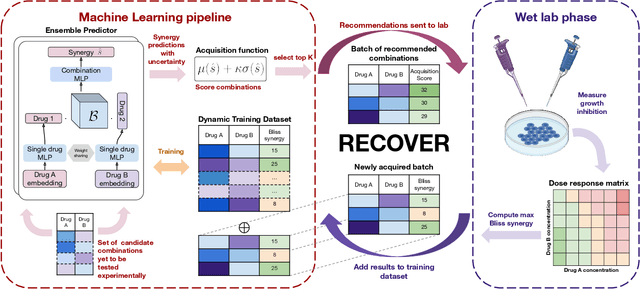

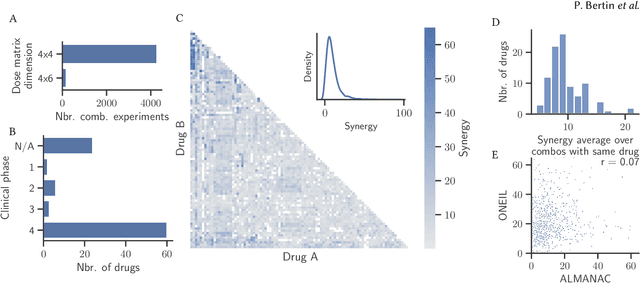

Selecting optimal drug repurposing combinations for further preclinical development is a challenging technical feat. Due to the toxicity of many therapeutic agents (e.g., chemotherapy), practitioners have favoured selection of synergistic compounds whereby lower doses can be used whilst maintaining high efficacy. For a fixed small molecule library, an exhaustive combinatorial chemical screen becomes infeasible to perform for academic and industry laboratories alike. Deep learning models have achieved state-of-the-art results in silico for the prediction of synergy scores. However, databases of drug combinations are highly biased towards synergistic agents and these results do not necessarily generalise out of distribution. We employ a sequential model optimization search applied to a deep learning model to quickly discover highly synergistic drug combinations active against a cancer cell line, while requiring substantially less screening than an exhaustive evaluation. Through iteratively adapting the model to newly acquired data, after only 3 rounds of ML-guided experimentation (including a calibration round), we find that the set of combinations queried by our model is enriched for highly synergistic combinations. Remarkably, we rediscovered a synergistic drug combination that was later confirmed to be under study within clinical trials.
Recommending Researchers in Machine Learning based on Author-Topic Model
Sep 05, 2021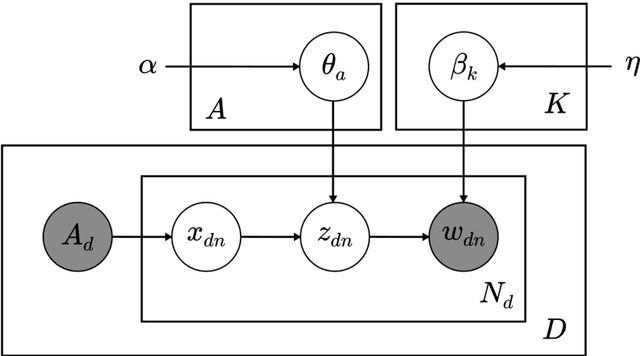
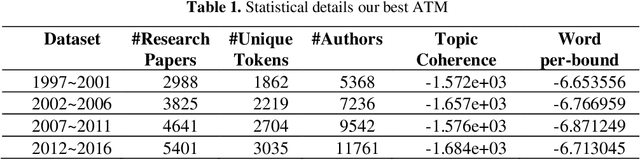
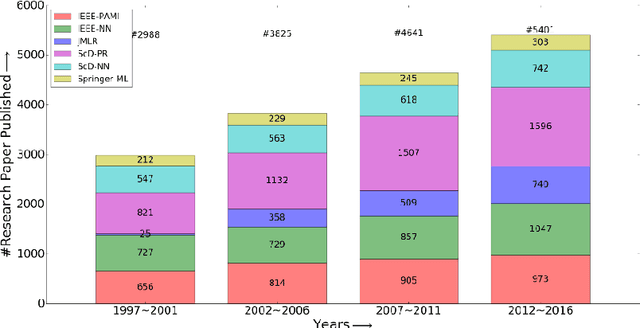
The aim of this paper is to uncover the researchers in machine learning using the author-topic model (ATM). We collect 16,855 scientific papers from six top journals in the field of machine learning published from 1997 to 2016 and analyze them using ATM. The dataset is broken down into 4 intervals to identify the top researchers and find similar researchers using their similarity score. The similarity score is calculated using Hellinger distance. The researchers are plotted using t-SNE, which reduces the dimensionality of the data while keeping the same distance between the points. The analysis of our study helps the upcoming researchers to find the top researchers in their area of interest.
Deep interpretability for GWAS
Jul 03, 2020
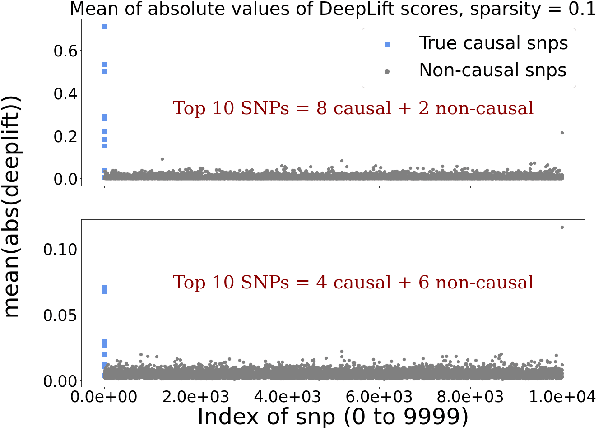
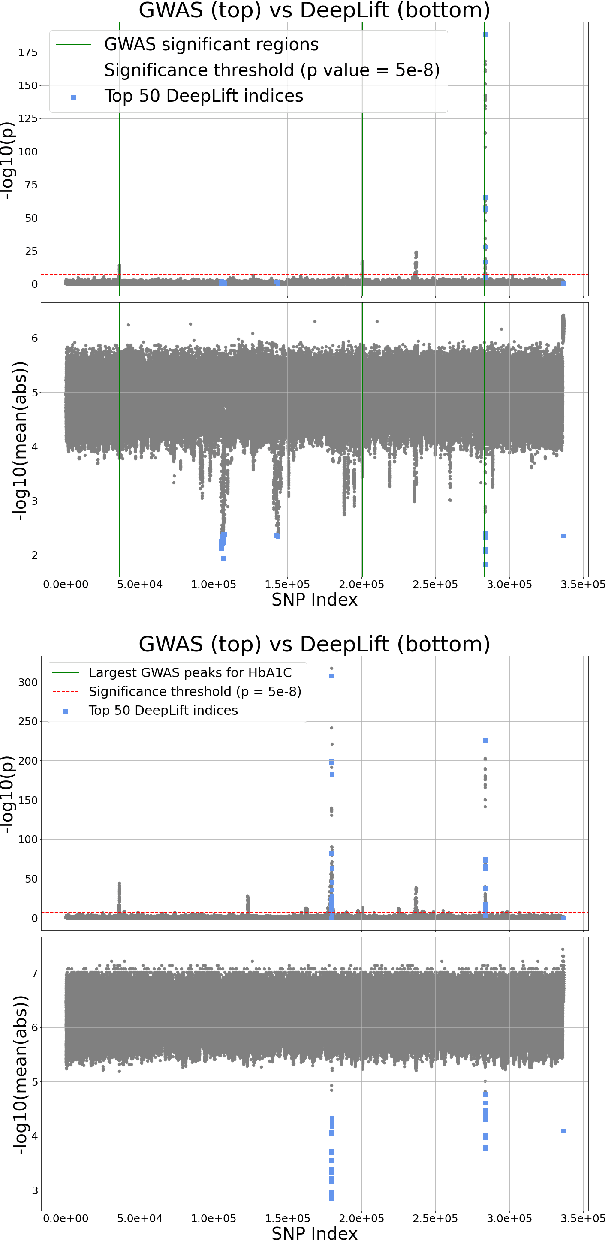
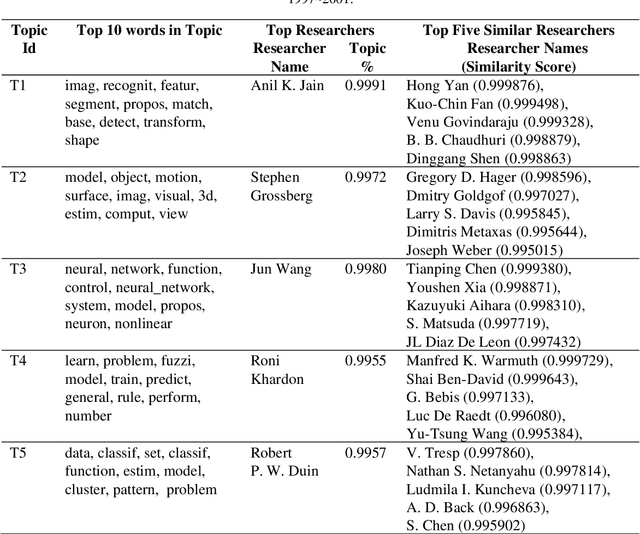
Genome-Wide Association Studies are typically conducted using linear models to find genetic variants associated with common diseases. In these studies, association testing is done on a variant-by-variant basis, possibly missing out on non-linear interaction effects between variants. Deep networks can be used to model these interactions, but they are difficult to train and interpret on large genetic datasets. We propose a method that uses the gradient based deep interpretability technique named DeepLIFT to show that known diabetes genetic risk factors can be identified using deep models along with possibly novel associations.
IterefinE: Iterative KG Refinement Embeddings using Symbolic Knowledge
Jun 03, 2020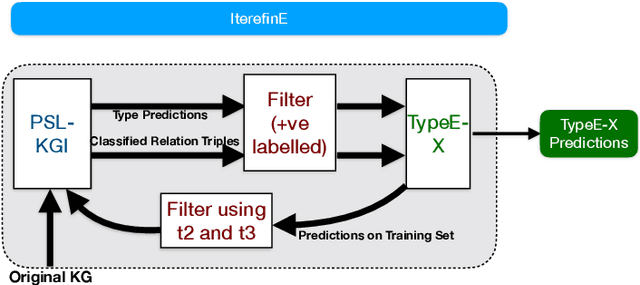
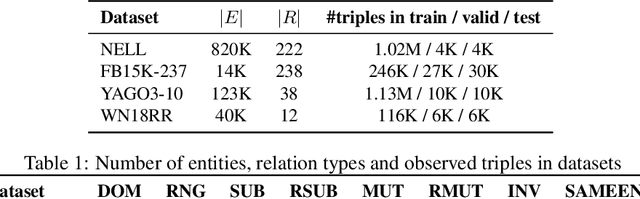
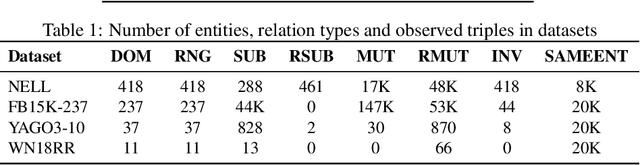
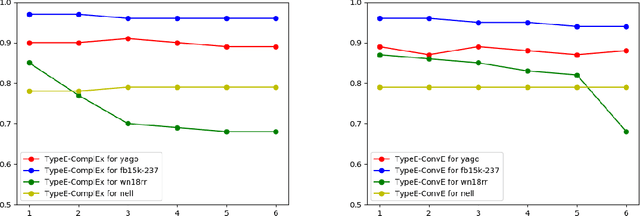
Knowledge Graphs (KGs) extracted from text sources are often noisy and lead to poor performance in downstream application tasks such as KG-based question answering.While much of the recent activity is focused on addressing the sparsity of KGs by using embeddings for inferring new facts, the issue of cleaning up of noise in KGs through KG refinement task is not as actively studied. Most successful techniques for KG refinement make use of inference rules and reasoning over ontologies. Barring a few exceptions, embeddings do not make use of ontological information, and their performance in KG refinement task is not well understood. In this paper, we present a KG refinement framework called IterefinE which iteratively combines the two techniques - one which uses ontological information and inferences rules, PSL-KGI, and the KG embeddings such as ComplEx and ConvE which do not. As a result, IterefinE is able to exploit not only the ontological information to improve the quality of predictions, but also the power of KG embeddings which (implicitly) perform longer chains of reasoning. The IterefinE framework, operates in a co-training mode and results in explicit type-supervised embedding of the refined KG from PSL-KGI which we call as TypeE-X. Our experiments over a range of KG benchmarks show that the embeddings that we produce are able to reject noisy facts from KG and at the same time infer higher quality new facts resulting in up to 9% improvement of overall weighted F1 score
Off-Policy Policy Gradient Algorithms by Constraining the State Distribution Shift
Dec 01, 2019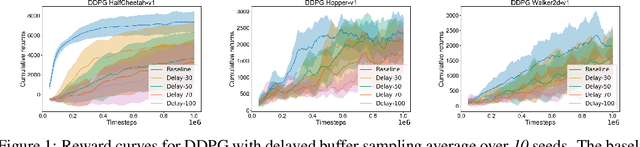
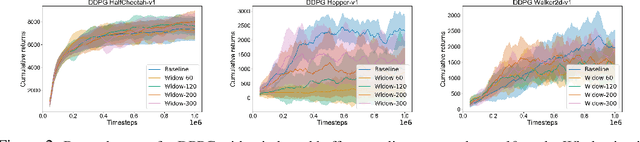
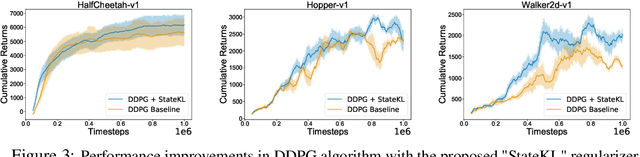
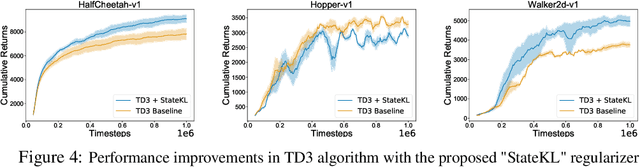
Off-policy deep reinforcement learning (RL) algorithms are incapable of learning solely from batch offline data without online interactions with the environment, due to the phenomenon known as \textit{extrapolation error}. This is often due to past data available in the replay buffer that may be quite different from the data distribution under the current policy. We argue that most off-policy learning methods fundamentally suffer from a \textit{state distribution shift} due to the mismatch between the state visitation distribution of the data collected by the behavior and target policies. This data distribution shift between current and past samples can significantly impact the performance of most modern off-policy based policy optimization algorithms. In this work, we first do a systematic analysis of state distribution mismatch in off-policy learning, and then develop a novel off-policy policy optimization method to constraint the state distribution shift. To do this, we first estimate the state distribution based on features of the state, using a density estimator and then develop a novel constrained off-policy gradient objective that minimizes the state distribution shift. Our experimental results on continuous control tasks show that minimizing this distribution mismatch can significantly improve performance in most popular practical off-policy policy gradient algorithms.
Matching Disparate Image Pairs Using Shape-Aware ConvNets
Nov 24, 2018



An end-to-end trainable ConvNet architecture, that learns to harness the power of shape representation for matching disparate image pairs, is proposed. Disparate image pairs are deemed those that exhibit strong affine variations in scale, viewpoint and projection parameters accompanied by the presence of partial or complete occlusion of objects and extreme variations in ambient illumination. Under these challenging conditions, neither local nor global feature-based image matching methods, when used in isolation, have been observed to be effective. The proposed correspondence determination scheme for matching disparate images exploits high-level shape cues that are derived from low-level local feature descriptors, thus combining the best of both worlds. A graph-based representation for the disparate image pair is generated by constructing an affinity matrix that embeds the distances between feature points in two images, thus modeling the correspondence determination problem as one of graph matching. The eigenspectrum of the affinity matrix, i.e., the learned global shape representation, is then used to further regress the transformation or homography that defines the correspondence between the source image and target image. The proposed scheme is shown to yield state-of-the-art results for both, coarse-level shape matching as well as fine point-wise correspondence determination.