 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMultilingual Bias Detection and Mitigation for Indian Languages
Dec 23, 2023Lack of diverse perspectives causes neutrality bias in Wikipedia content leading to millions of worldwide readers getting exposed by potentially inaccurate information. Hence, neutrality bias detection and mitigation is a critical problem. Although previous studies have proposed effective solutions for English, no work exists for Indian languages. First, we contribute two large datasets, mWikiBias and mWNC, covering 8 languages, for the bias detection and mitigation tasks respectively. Next, we investigate the effectiveness of popular multilingual Transformer-based models for the two tasks by modeling detection as a binary classification problem and mitigation as a style transfer problem. We make the code and data publicly available.
Massively Multilingual Language Models for Cross Lingual Fact Extraction from Low Resource Indian Languages
Feb 09, 2023Massive knowledge graphs like Wikidata attempt to capture world knowledge about multiple entities. Recent approaches concentrate on automatically enriching these KGs from text. However a lot of information present in the form of natural text in low resource languages is often missed out. Cross Lingual Information Extraction aims at extracting factual information in the form of English triples from low resource Indian Language text. Despite its massive potential, progress made on this task is lagging when compared to Monolingual Information Extraction. In this paper, we propose the task of Cross Lingual Fact Extraction(CLFE) from text and devise an end-to-end generative approach for the same which achieves an overall F1 score of 77.46.
XF2T: Cross-lingual Fact-to-Text Generation for Low-Resource Languages
Sep 22, 2022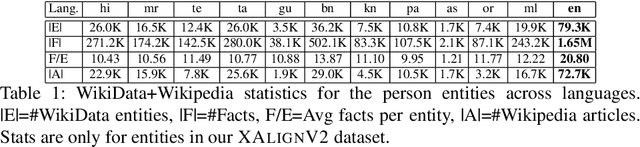
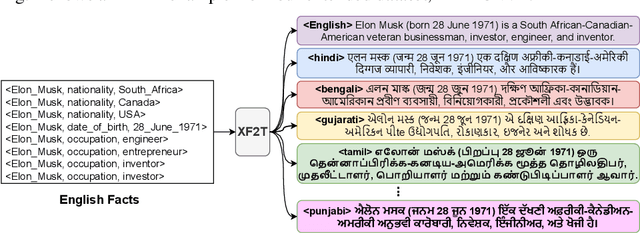
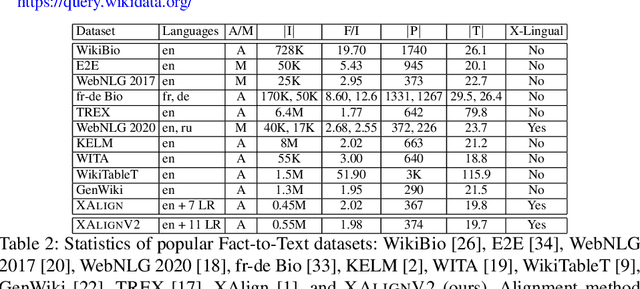
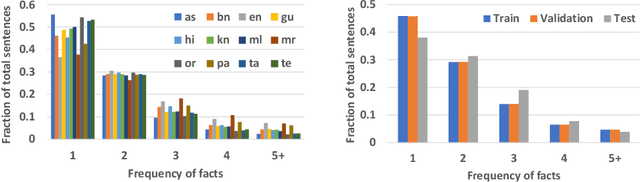
Multiple business scenarios require an automated generation of descriptive human-readable text from structured input data. Hence, fact-to-text generation systems have been developed for various downstream tasks like generating soccer reports, weather and financial reports, medical reports, person biographies, etc. Unfortunately, previous work on fact-to-text (F2T) generation has focused primarily on English mainly due to the high availability of relevant datasets. Only recently, the problem of cross-lingual fact-to-text (XF2T) was proposed for generation across multiple languages alongwith a dataset, XALIGN for eight languages. However, there has been no rigorous work on the actual XF2T generation problem. We extend XALIGN dataset with annotated data for four more languages: Punjabi, Malayalam, Assamese and Oriya. We conduct an extensive study using popular Transformer-based text generation models on our extended multi-lingual dataset, which we call XALIGNV2. Further, we investigate the performance of different text generation strategies: multiple variations of pretraining, fact-aware embeddings and structure-aware input encoding. Our extensive experiments show that a multi-lingual mT5 model which uses fact-aware embeddings with structure-aware input encoding leads to best results on average across the twelve languages. We make our code, dataset and model publicly available, and hope that this will help advance further research in this critical area.
Adaptation of domain-specific transformer models with text oversampling for sentiment analysis of social media posts on Covid-19 vaccines
Sep 22, 2022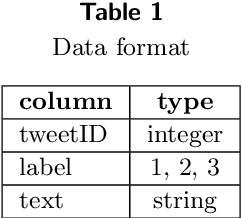
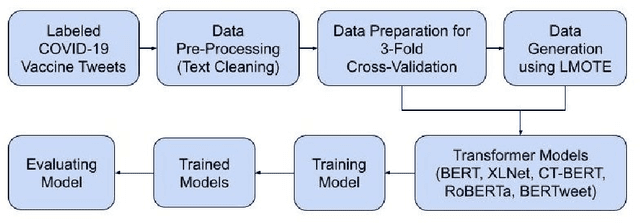


Covid-19 has spread across the world and several vaccines have been developed to counter its surge. To identify the correct sentiments associated with the vaccines from social media posts, we fine-tune various state-of-the-art pre-trained transformer models on tweets associated with Covid-19 vaccines. Specifically, we use the recently introduced state-of-the-art pre-trained transformer models RoBERTa, XLNet and BERT, and the domain-specific transformer models CT-BERT and BERTweet that are pre-trained on Covid-19 tweets. We further explore the option of text augmentation by oversampling using Language Model based Oversampling Technique (LMOTE) to improve the accuracies of these models, specifically, for small sample datasets where there is an imbalanced class distribution among the positive, negative and neutral sentiment classes. Our results summarize our findings on the suitability of text oversampling for imbalanced small sample datasets that are used to fine-tune state-of-the-art pre-trained transformer models, and the utility of domain-specific transformer models for the classification task.
Survey on Wireless Information Energy Transfer (WIET) and Related Applications in 6G Internet of NanoThings (IoNT)
Jul 01, 2022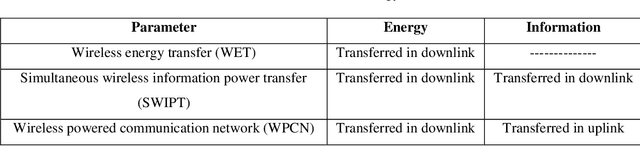
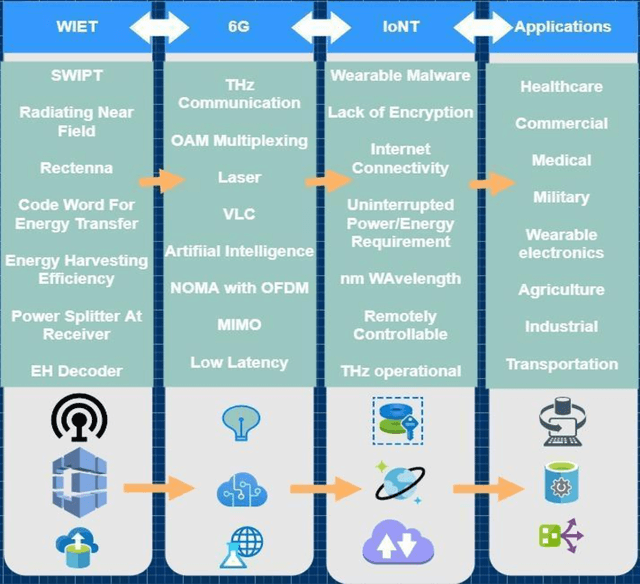


This article contains an overview of WIET and the related applications in 6G IoNT. Specifically, to explore the following, we: (i) introduce the 6G network along with the implementation challenges, possible techniques, THz communication and related research challenges, (ii) focus on the WIET architecture, and different energy carrying code words for efficient charging through WIET, (iii) discuss IoNT with techniques proposed for communication of nano-devices, and (iv) conduct a detailed literature review to explore the implicational aspects of the WIET in the 6G nano-network. In addition, we also investigate the expected applications of WIET in the 6G IoNT based devices and discuss the WIET implementation challenges in 6G IoNT for the optimal use of the technology. Lastly, we overview the expected design challenges which may occur during the implementation process, and identify the key research challenges which require timely solutions and which are significant to spur further research in this challenging area. Overall, through this survey, we discuss the possibility to maximize the applications of WIET in 6G IoNT.
XAlign: Cross-lingual Fact-to-Text Alignment and Generation for Low-Resource Languages
Feb 01, 2022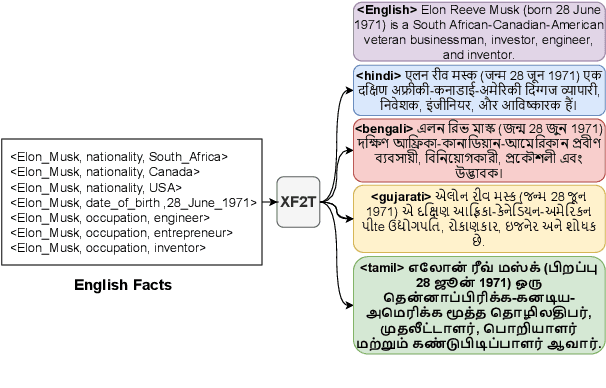
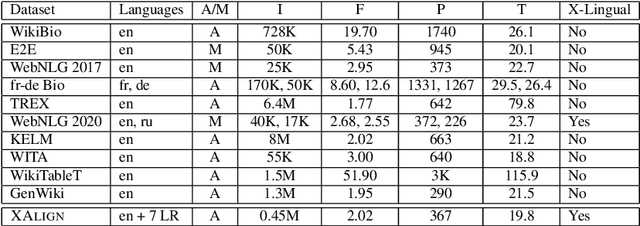
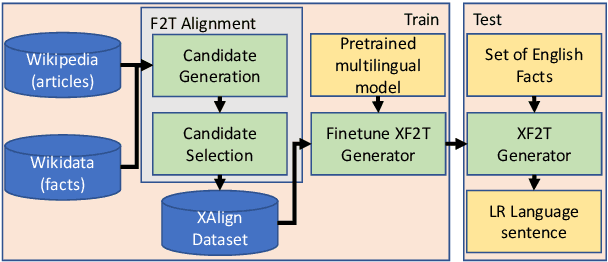
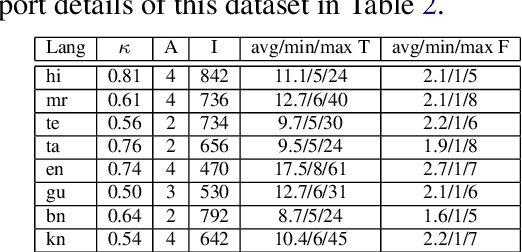
Multiple critical scenarios (like Wikipedia text generation given English Infoboxes) need automated generation of descriptive text in low resource (LR) languages from English fact triples. Previous work has focused on English fact-to-text (F2T) generation. To the best of our knowledge, there has been no previous attempt on cross-lingual alignment or generation for LR languages. Building an effective cross-lingual F2T (XF2T) system requires alignment between English structured facts and LR sentences. We propose two unsupervised methods for cross-lingual alignment. We contribute XALIGN, an XF2T dataset with 0.45M pairs across 8 languages, of which 5402 pairs have been manually annotated. We also train strong baseline XF2T generation models on the XAlign dataset.
A Neuro-Fuzzy Technique for Implementing the Half-Adder Circuit Using the CANFIS Model
Sep 20, 2012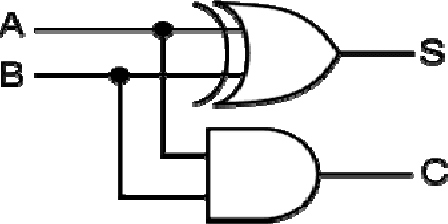

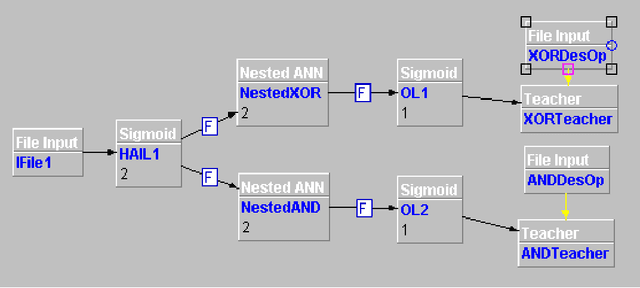
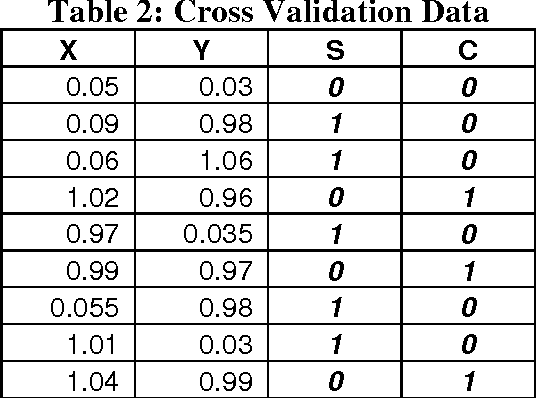
A Neural Network, in general, is not considered to be a good solver of mathematical and binary arithmetic problems. However, networks have been developed for such problems as the XOR circuit. This paper presents a technique for the implementation of the Half-adder circuit using the CoActive Neuro-Fuzzy Inference System (CANFIS) Model and attempts to solve the problem using the NeuroSolutions 5 Simulator. The paper gives the experimental results along with the interpretations and possible applications of the technique.
* 7 pages, 9 figures, 7 tables