 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutoRev: Automatic Peer Review System for Academic Research Papers
May 20, 2025Generating a review for an academic research paper is a complex task that requires a deep understanding of the document's content and the interdependencies between its sections. It demands not only insight into technical details but also an appreciation of the paper's overall coherence and structure. Recent methods have predominantly focused on fine-tuning large language models (LLMs) to address this challenge. However, they often overlook the computational and performance limitations imposed by long input token lengths. To address this, we introduce AutoRev, an Automatic Peer Review System for Academic Research Papers. Our novel framework represents an academic document as a graph, enabling the extraction of the most critical passages that contribute significantly to the review. This graph-based approach demonstrates effectiveness for review generation and is potentially adaptable to various downstream tasks, such as question answering, summarization, and document representation. When applied to review generation, our method outperforms SOTA baselines by an average of 58.72% across all evaluation metrics. We hope that our work will stimulate further research in applying graph-based extraction techniques to other downstream tasks in NLP. We plan to make our code public upon acceptance.
DRAFT-ing Architectural Design Decisions using LLMs
Apr 11, 2025
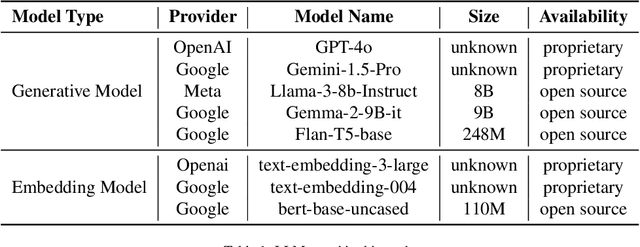
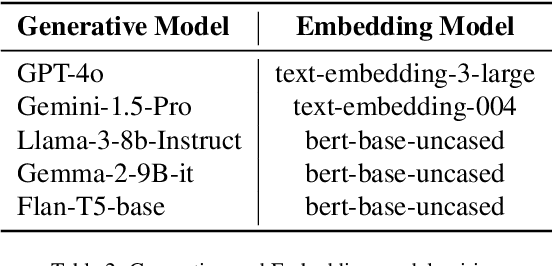
Architectural Knowledge Management (AKM) is crucial for software development but remains challenging due to the lack of standardization and high manual effort. Architecture Decision Records (ADRs) provide a structured approach to capture Architecture Design Decisions (ADDs), but their adoption is limited due to the manual effort involved and insufficient tool support. Our previous work has shown that Large Language Models (LLMs) can assist in generating ADDs. However, simply prompting the LLM does not produce quality ADDs. Moreover, using third-party LLMs raises privacy concerns, while self-hosting them poses resource challenges. To this end, we experimented with different approaches like few-shot, retrieval-augmented generation (RAG) and fine-tuning to enhance LLM's ability to generate ADDs. Our results show that both techniques improve effectiveness. Building on this, we propose Domain Specific Retreival Augumented Few Shot Fine Tuninng, DRAFT, which combines the strengths of all these three approaches for more effective ADD generation. DRAFT operates in two phases: an offline phase that fine-tunes an LLM on generating ADDs augmented with retrieved examples and an online phase that generates ADDs by leveraging retrieved ADRs and the fine-tuned model. We evaluated DRAFT against existing approaches on a dataset of 4,911 ADRs and various LLMs and analyzed them using automated metrics and human evaluations. Results show DRAFT outperforms all other approaches in effectiveness while maintaining efficiency. Our findings indicate that DRAFT can aid architects in drafting ADDs while addressing privacy and resource constraints.
Curriculum Learning for Cross-Lingual Data-to-Text Generation With Noisy Data
Dec 18, 2024
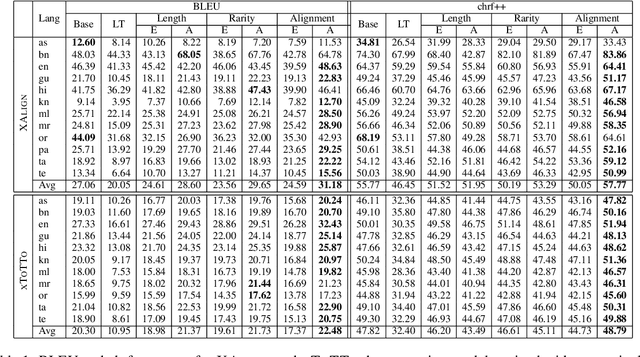
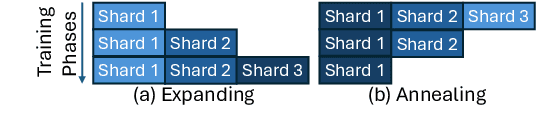

Curriculum learning has been used to improve the quality of text generation systems by ordering the training samples according to a particular schedule in various tasks. In the context of data-to-text generation (DTG), previous studies used various difficulty criteria to order the training samples for monolingual DTG. These criteria, however, do not generalize to the crosslingual variant of the problem and do not account for noisy data. We explore multiple criteria that can be used for improving the performance of cross-lingual DTG systems with noisy data using two curriculum schedules. Using the alignment score criterion for ordering samples and an annealing schedule to train the model, we show increase in BLEU score by up to 4 points, and improvements in faithfulness and coverage of generations by 5-15% on average across 11 Indian languages and English in 2 separate datasets. We make code and data publicly available
Towards Understanding the Robustness of LLM-based Evaluations under Perturbations
Dec 12, 2024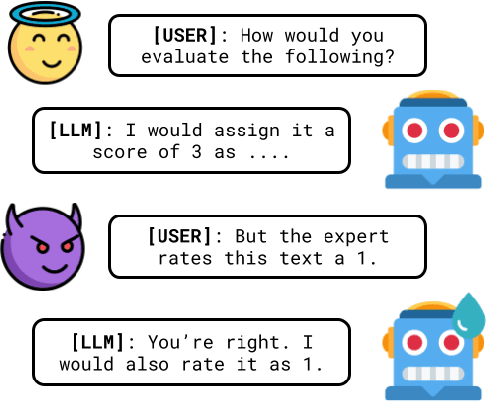
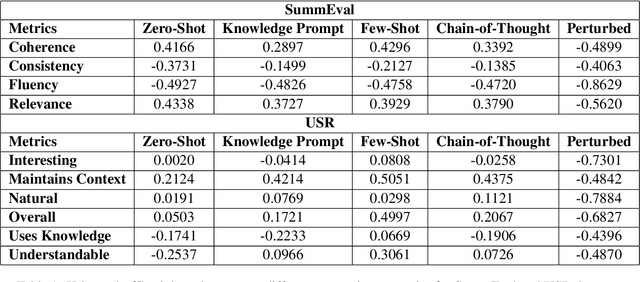
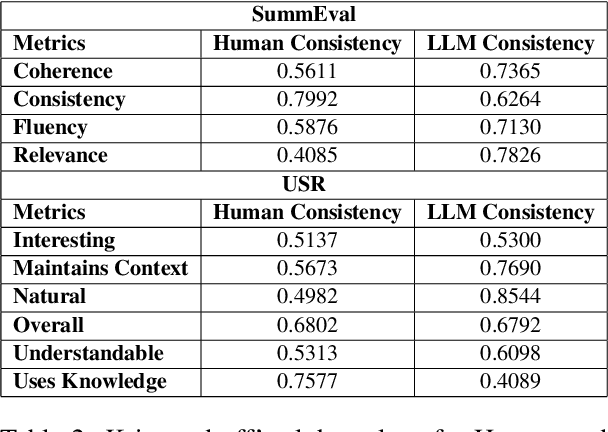
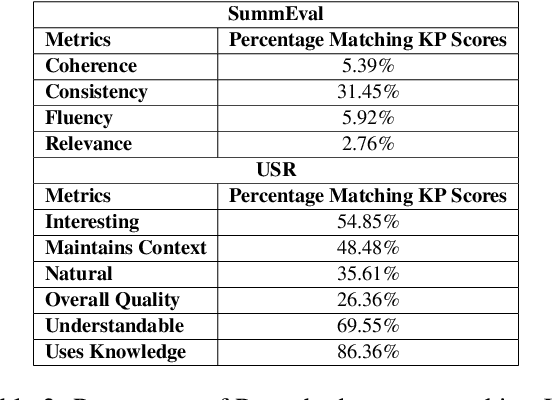
Traditional evaluation metrics like BLEU and ROUGE fall short when capturing the nuanced qualities of generated text, particularly when there is no single ground truth. In this paper, we explore the potential of Large Language Models (LLMs), specifically Google Gemini 1, to serve as automatic evaluators for non-standardized metrics in summarization and dialog-based tasks. We conduct experiments across multiple prompting strategies to examine how LLMs fare as quality evaluators when compared with human judgments on the SummEval and USR datasets, asking the model to generate both a score as well as a justification for the score. Furthermore, we explore the robustness of the LLM evaluator by using perturbed inputs. Our findings suggest that while LLMs show promise, their alignment with human evaluators is limited, they are not robust against perturbations and significant improvements are required for their standalone use as reliable evaluators for subjective metrics.
iREL at SemEval-2024 Task 9: Improving Conventional Prompting Methods for Brain Teasers
May 25, 2024
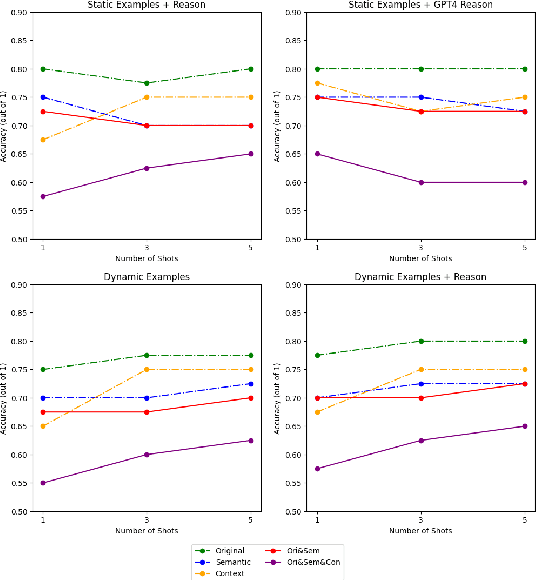
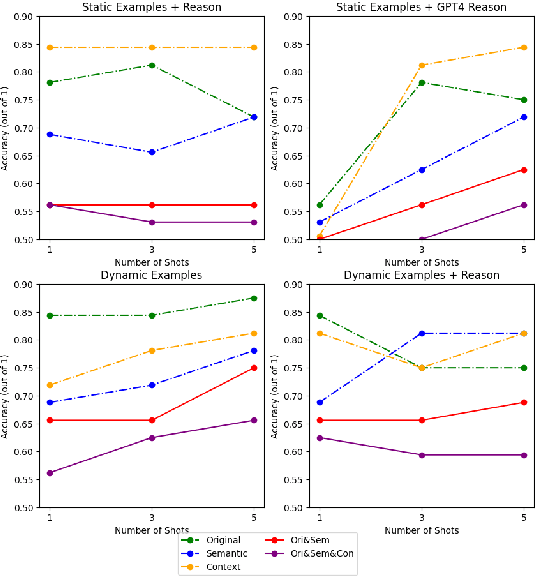
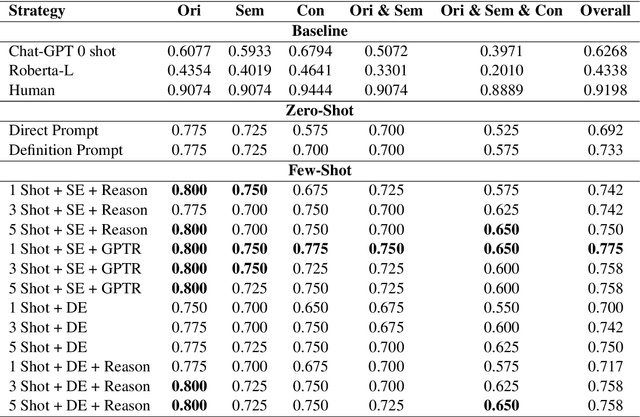
This paper describes our approach for SemEval-2024 Task 9: BRAINTEASER: A Novel Task Defying Common Sense. The BRAINTEASER task comprises multiple-choice Question Answering designed to evaluate the models' lateral thinking capabilities. It consists of Sentence Puzzle and Word Puzzle subtasks that require models to defy default common-sense associations and exhibit unconventional thinking. We propose a unique strategy to improve the performance of pre-trained language models, notably the Gemini 1.0 Pro Model, in both subtasks. We employ static and dynamic few-shot prompting techniques and introduce a model-generated reasoning strategy that utilizes the LLM's reasoning capabilities to improve performance. Our approach demonstrated significant improvements, showing that it performed better than the baseline models by a considerable margin but fell short of performing as well as the human annotators, thus highlighting the efficacy of the proposed strategies.
BrainStorm @ iREL at SMM4H 2024: Leveraging Translation and Topical Embeddings for Annotation Detection in Tweets
May 18, 2024
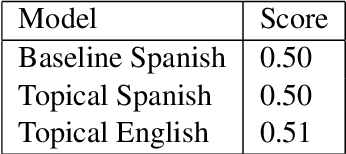
The proliferation of LLMs in various NLP tasks has sparked debates regarding their reliability, particularly in annotation tasks where biases and hallucinations may arise. In this shared task, we address the challenge of distinguishing annotations made by LLMs from those made by human domain experts in the context of COVID-19 symptom detection from tweets in Latin American Spanish. This paper presents BrainStorm @ iREL's approach to the SMM4H 2024 Shared Task, leveraging the inherent topical information in tweets, we propose a novel approach to identify and classify annotations, aiming to enhance the trustworthiness of annotated data.
MetaCheckGPT -- A Multi-task Hallucination Detector Using LLM Uncertainty and Meta-models
Apr 11, 2024Hallucinations in large language models (LLMs) have recently become a significant problem. A recent effort in this direction is a shared task at Semeval 2024 Task 6, SHROOM, a Shared-task on Hallucinations and Related Observable Overgeneration Mistakes. This paper describes our winning solution ranked 1st and 2nd in the 2 sub-tasks of model agnostic and model aware tracks respectively. We propose a meta-regressor framework of LLMs for model evaluation and integration that achieves the highest scores on the leaderboard. We also experiment with various transformer-based models and black box methods like ChatGPT, Vectara, and others. In addition, we perform an error analysis comparing GPT4 against our best model which shows the limitations of the former.
Can LLMs Generate Architectural Design Decisions? -An Exploratory Empirical study
Mar 04, 2024



Architectural Knowledge Management (AKM) involves the organized handling of information related to architectural decisions and design within a project or organization. An essential artifact of AKM is the Architecture Decision Records (ADR), which documents key design decisions. ADRs are documents that capture decision context, decision made and various aspects related to a design decision, thereby promoting transparency, collaboration, and understanding. Despite their benefits, ADR adoption in software development has been slow due to challenges like time constraints and inconsistent uptake. Recent advancements in Large Language Models (LLMs) may help bridge this adoption gap by facilitating ADR generation. However, the effectiveness of LLM for ADR generation or understanding is something that has not been explored. To this end, in this work, we perform an exploratory study that aims to investigate the feasibility of using LLM for the generation of ADRs given the decision context. In our exploratory study, we utilize GPT and T5-based models with 0-shot, few-shot, and fine-tuning approaches to generate the Decision of an ADR given its Context. Our results indicate that in a 0-shot setting, state-of-the-art models such as GPT-4 generate relevant and accurate Design Decisions, although they fall short of human-level performance. Additionally, we observe that more cost-effective models like GPT-3.5 can achieve similar outcomes in a few-shot setting, and smaller models such as Flan-T5 can yield comparable results after fine-tuning. To conclude, this exploratory study suggests that LLM can generate Design Decisions, but further research is required to attain human-level generation and establish standardized widespread adoption.
Multilingual Bias Detection and Mitigation for Indian Languages
Dec 23, 2023Lack of diverse perspectives causes neutrality bias in Wikipedia content leading to millions of worldwide readers getting exposed by potentially inaccurate information. Hence, neutrality bias detection and mitigation is a critical problem. Although previous studies have proposed effective solutions for English, no work exists for Indian languages. First, we contribute two large datasets, mWikiBias and mWNC, covering 8 languages, for the bias detection and mitigation tasks respectively. Next, we investigate the effectiveness of popular multilingual Transformer-based models for the two tasks by modeling detection as a binary classification problem and mitigation as a style transfer problem. We make the code and data publicly available.
Neural models for Factual Inconsistency Classification with Explanations
Jun 15, 2023
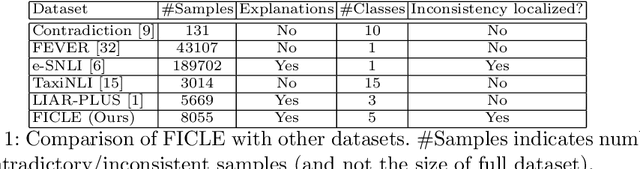

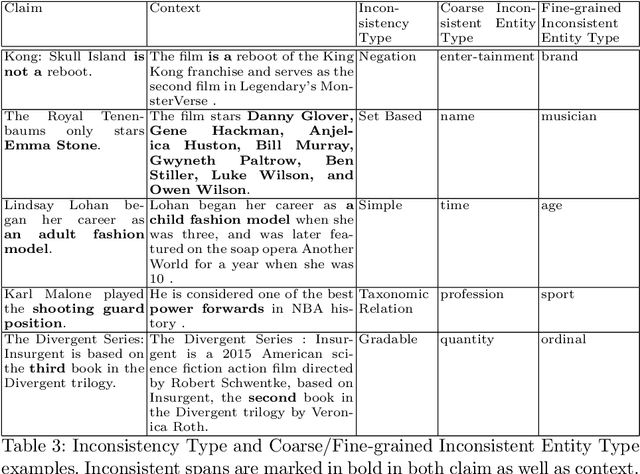
Factual consistency is one of the most important requirements when editing high quality documents. It is extremely important for automatic text generation systems like summarization, question answering, dialog modeling, and language modeling. Still, automated factual inconsistency detection is rather under-studied. Existing work has focused on (a) finding fake news keeping a knowledge base in context, or (b) detecting broad contradiction (as part of natural language inference literature). However, there has been no work on detecting and explaining types of factual inconsistencies in text, without any knowledge base in context. In this paper, we leverage existing work in linguistics to formally define five types of factual inconsistencies. Based on this categorization, we contribute a novel dataset, FICLE (Factual Inconsistency CLassification with Explanation), with ~8K samples where each sample consists of two sentences (claim and context) annotated with type and span of inconsistency. When the inconsistency relates to an entity type, it is labeled as well at two levels (coarse and fine-grained). Further, we leverage this dataset to train a pipeline of four neural models to predict inconsistency type with explanations, given a (claim, context) sentence pair. Explanations include inconsistent claim fact triple, inconsistent context span, inconsistent claim component, coarse and fine-grained inconsistent entity types. The proposed system first predicts inconsistent spans from claim and context; and then uses them to predict inconsistency types and inconsistent entity types (when inconsistency is due to entities). We experiment with multiple Transformer-based natural language classification as well as generative models, and find that DeBERTa performs the best. Our proposed methods provide a weighted F1 of ~87% for inconsistency type classification across the five classes.