 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDRAFT-ing Architectural Design Decisions using LLMs
Apr 11, 2025
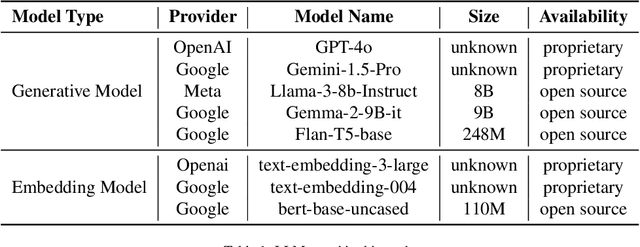
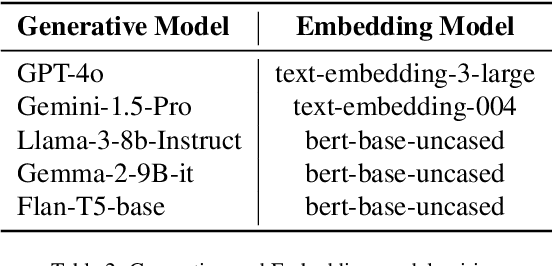
Architectural Knowledge Management (AKM) is crucial for software development but remains challenging due to the lack of standardization and high manual effort. Architecture Decision Records (ADRs) provide a structured approach to capture Architecture Design Decisions (ADDs), but their adoption is limited due to the manual effort involved and insufficient tool support. Our previous work has shown that Large Language Models (LLMs) can assist in generating ADDs. However, simply prompting the LLM does not produce quality ADDs. Moreover, using third-party LLMs raises privacy concerns, while self-hosting them poses resource challenges. To this end, we experimented with different approaches like few-shot, retrieval-augmented generation (RAG) and fine-tuning to enhance LLM's ability to generate ADDs. Our results show that both techniques improve effectiveness. Building on this, we propose Domain Specific Retreival Augumented Few Shot Fine Tuninng, DRAFT, which combines the strengths of all these three approaches for more effective ADD generation. DRAFT operates in two phases: an offline phase that fine-tunes an LLM on generating ADDs augmented with retrieved examples and an online phase that generates ADDs by leveraging retrieved ADRs and the fine-tuned model. We evaluated DRAFT against existing approaches on a dataset of 4,911 ADRs and various LLMs and analyzed them using automated metrics and human evaluations. Results show DRAFT outperforms all other approaches in effectiveness while maintaining efficiency. Our findings indicate that DRAFT can aid architects in drafting ADDs while addressing privacy and resource constraints.
Engineering LLM Powered Multi-agent Framework for Autonomous CloudOps
Jan 14, 2025Cloud Operations (CloudOps) is a rapidly growing field focused on the automated management and optimization of cloud infrastructure which is essential for organizations navigating increasingly complex cloud environments. MontyCloud Inc. is one of the major companies in the CloudOps domain that leverages autonomous bots to manage cloud compliance, security, and continuous operations. To make the platform more accessible and effective to the customers, we leveraged the use of GenAI. Developing a GenAI-based solution for autonomous CloudOps for the existing MontyCloud system presented us with various challenges such as i) diverse data sources; ii) orchestration of multiple processes; and iii) handling complex workflows to automate routine tasks. To this end, we developed MOYA, a multi-agent framework that leverages GenAI and balances autonomy with the necessary human control. This framework integrates various internal and external systems and is optimized for factors like task orchestration, security, and error mitigation while producing accurate, reliable, and relevant insights by utilizing Retrieval Augmented Generation (RAG). Evaluations of our multi-agent system with the help of practitioners as well as using automated checks demonstrate enhanced accuracy, responsiveness, and effectiveness over non-agentic approaches across complex workflows.
Can LLMs Generate Architectural Design Decisions? -An Exploratory Empirical study
Mar 04, 2024



Architectural Knowledge Management (AKM) involves the organized handling of information related to architectural decisions and design within a project or organization. An essential artifact of AKM is the Architecture Decision Records (ADR), which documents key design decisions. ADRs are documents that capture decision context, decision made and various aspects related to a design decision, thereby promoting transparency, collaboration, and understanding. Despite their benefits, ADR adoption in software development has been slow due to challenges like time constraints and inconsistent uptake. Recent advancements in Large Language Models (LLMs) may help bridge this adoption gap by facilitating ADR generation. However, the effectiveness of LLM for ADR generation or understanding is something that has not been explored. To this end, in this work, we perform an exploratory study that aims to investigate the feasibility of using LLM for the generation of ADRs given the decision context. In our exploratory study, we utilize GPT and T5-based models with 0-shot, few-shot, and fine-tuning approaches to generate the Decision of an ADR given its Context. Our results indicate that in a 0-shot setting, state-of-the-art models such as GPT-4 generate relevant and accurate Design Decisions, although they fall short of human-level performance. Additionally, we observe that more cost-effective models like GPT-3.5 can achieve similar outcomes in a few-shot setting, and smaller models such as Flan-T5 can yield comparable results after fine-tuning. To conclude, this exploratory study suggests that LLM can generate Design Decisions, but further research is required to attain human-level generation and establish standardized widespread adoption.
Multilingual Bias Detection and Mitigation for Indian Languages
Dec 23, 2023Lack of diverse perspectives causes neutrality bias in Wikipedia content leading to millions of worldwide readers getting exposed by potentially inaccurate information. Hence, neutrality bias detection and mitigation is a critical problem. Although previous studies have proposed effective solutions for English, no work exists for Indian languages. First, we contribute two large datasets, mWikiBias and mWNC, covering 8 languages, for the bias detection and mitigation tasks respectively. Next, we investigate the effectiveness of popular multilingual Transformer-based models for the two tasks by modeling detection as a binary classification problem and mitigation as a style transfer problem. We make the code and data publicly available.
JU_NLP at HinglishEval: Quality Evaluation of the Low-Resource Code-Mixed Hinglish Text
Jun 16, 2022

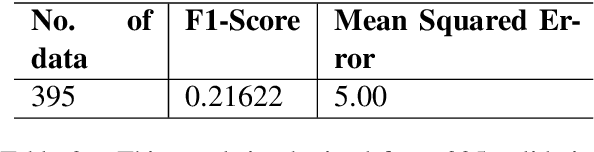
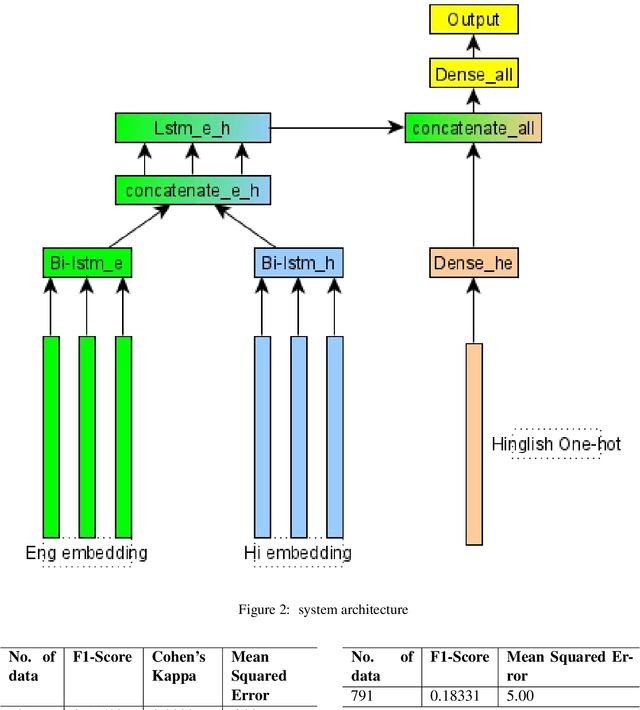
In this paper we describe a system submitted to the INLG 2022 Generation Challenge (GenChal) on Quality Evaluation of the Low-Resource Synthetically Generated Code-Mixed Hinglish Text. We implement a Bi-LSTM-based neural network model to predict the Average rating score and Disagreement score of the synthetic Hinglish dataset. In our models, we used word embeddings for English and Hindi data, and one hot encodings for Hinglish data. We achieved a F1 score of 0.11, and mean squared error of 6.0 in the average rating score prediction task. In the task of Disagreement score prediction, we achieve a F1 score of 0.18, and mean squared error of 5.0.