 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEmpirical Evidence of Complexity-Induced Limits in Large Language Models on Finite Discrete State-Space Problems with Explicit Validity Constraints
Apr 15, 2026Large Language Models (LLMs) are increasingly described as possessing strong reasoning capabilities, supported by high performance on mathematical, logical, and planning benchmarks. However, most existing evaluations rely on aggregate accuracy over fixed datasets, obscuring how reasoning behavior evolves as task complexity increases. In this work, we introduce a controlled benchmarking framework to systematically evaluate the robustness of reasoning in Large Reasoning Models (LRMs) under progressively increasing problem complexity. We construct a suite of nine classical reasoning tasks: Boolean Satisfiability, Cryptarithmetic, Graph Coloring, River Crossing, Tower of Hanoi, Water Jug, Checker Jumping, Sudoku, and Rubik's Cube, each parameterized to precisely control complexity while preserving underlying semantics. Using deterministic validators, we evaluate multiple open and proprietary LRMs across low, intermediate, and high complexity regimes, ensuring that only fully valid solutions are accepted. Our results reveal a consistent phase transition like behavior: models achieve high accuracy at low complexity but degrade sharply beyond task specific complexity thresholds. We formalize this phenomenon as reasoning collapse. Across tasks, we observe substantial accuracy declines, often exceeding 50%, accompanied by inconsistent reasoning traces, constraint violations, loss of state tracking, and confidently incorrect outputs. Increased reasoning length does not reliably improve correctness, and gains in one problem family do not generalize to others. These findings highlight the need for evaluation methodologies that move beyond static benchmarks and explicitly measure reasoning robustness under controlled complexity.
Scalable Pretraining of Large Mixture of Experts Language Models on Aurora Super Computer
Apr 01, 2026Pretraining Large Language Models (LLMs) from scratch requires massive amount of compute. Aurora super computer is an ExaScale machine with 127,488 Intel PVC (Ponte Vechio) GPU tiles. In this work, we showcase LLM pretraining on Aurora at the scale of 1000s of GPU tiles. Towards this effort, we developed Optimus, an inhouse training library with support for standard large model training techniques. Using Optimus, we first pretrained Mula-1B, a 1 Billion dense model and Mula-7B-A1B, a 7 Billion Mixture of Experts (MoE) model from scratch on 3072 GPU tiles for the full 4 trillion tokens of the OLMoE-mix-0924 dataset. We then demonstrated model scaling by pretraining three large MoE models Mula-20B-A2B, Mula-100B-A7B, and Mula-220B-A10B till 100 Billion tokens on the same dataset. On our largest model Mula-220B-A10B, we pushed the compute scaling from 384 to 12288 GPU tiles and observed scaling efficiency of around 90% at 12288 GPU tiles. We significantly improved the runtime performance of MoE models using custom GPU kernels for expert computation, and a novel EP-Aware sharded optimizer resulting in training speedups up to 1.71x. As part of the Optimus library, we also developed a robust set of reliability and fault tolerant features to improve training stability and continuity at scale.
GS-Net: Global Self-Attention Guided CNN for Multi-Stage Glaucoma Classification
Sep 24, 2024



Glaucoma is a common eye disease that leads to irreversible blindness unless timely detected. Hence, glaucoma detection at an early stage is of utmost importance for a better treatment plan and ultimately saving the vision. The recent literature has shown the prominence of CNN-based methods to detect glaucoma from retinal fundus images. However, such methods mainly focus on solving binary classification tasks and have not been thoroughly explored for the detection of different glaucoma stages, which is relatively challenging due to minute lesion size variations and high inter-class similarities. This paper proposes a global self-attention based network called GS-Net for efficient multi-stage glaucoma classification. We introduce a global self-attention module (GSAM) consisting of two parallel attention modules, a channel attention module (CAM) and a spatial attention module (SAM), to learn global feature dependencies across channel and spatial dimensions. The GSAM encourages extracting more discriminative and class-specific features from the fundus images. The experimental results on a publicly available dataset demonstrate that our GS-Net outperforms state-of-the-art methods. Also, the GSAM achieves competitive performance against popular attention modules.
* 5 pages, 3 figures
JU_NLP at HinglishEval: Quality Evaluation of the Low-Resource Code-Mixed Hinglish Text
Jun 16, 2022

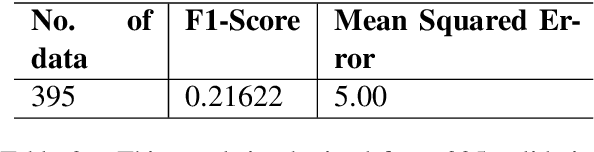
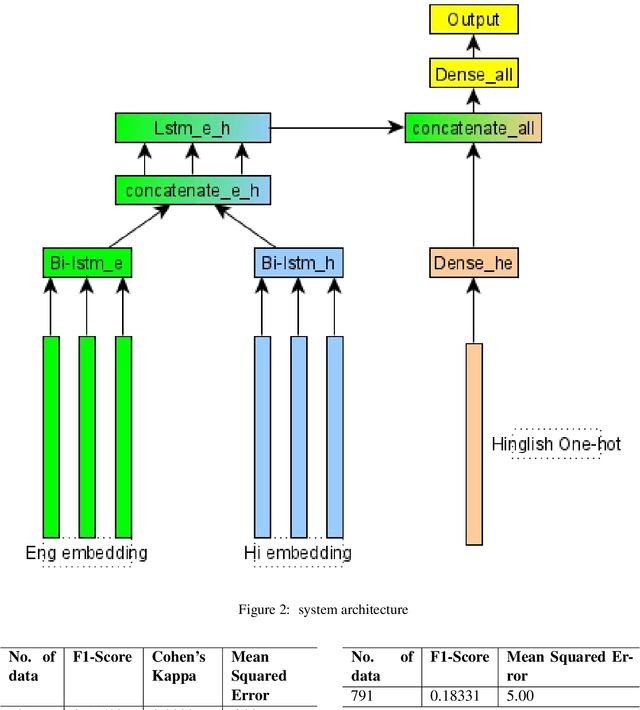
In this paper we describe a system submitted to the INLG 2022 Generation Challenge (GenChal) on Quality Evaluation of the Low-Resource Synthetically Generated Code-Mixed Hinglish Text. We implement a Bi-LSTM-based neural network model to predict the Average rating score and Disagreement score of the synthetic Hinglish dataset. In our models, we used word embeddings for English and Hindi data, and one hot encodings for Hinglish data. We achieved a F1 score of 0.11, and mean squared error of 6.0 in the average rating score prediction task. In the task of Disagreement score prediction, we achieve a F1 score of 0.18, and mean squared error of 5.0.
Can Unsupervised Knowledge Transfer from Social Discussions Help Argument Mining?
Mar 24, 2022
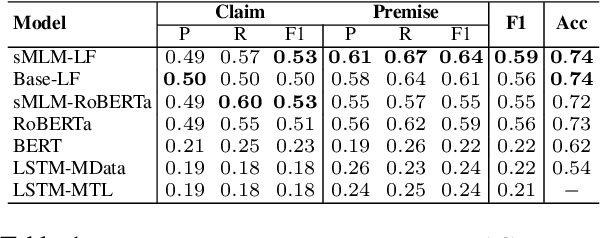

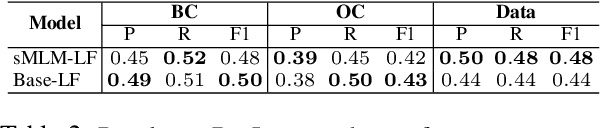
Identifying argument components from unstructured texts and predicting the relationships expressed among them are two primary steps of argument mining. The intrinsic complexity of these tasks demands powerful learning models. While pretrained Transformer-based Language Models (LM) have been shown to provide state-of-the-art results over different NLP tasks, the scarcity of manually annotated data and the highly domain-dependent nature of argumentation restrict the capabilities of such models. In this work, we propose a novel transfer learning strategy to overcome these challenges. We utilize argumentation-rich social discussions from the ChangeMyView subreddit as a source of unsupervised, argumentative discourse-aware knowledge by finetuning pretrained LMs on a selectively masked language modeling task. Furthermore, we introduce a novel prompt-based strategy for inter-component relation prediction that compliments our proposed finetuning method while leveraging on the discourse context. Exhaustive experiments show the generalization capability of our method on these two tasks over within-domain as well as out-of-domain datasets, outperforming several existing and employed strong baselines.
AdvCodeMix: Adversarial Attack on Code-Mixed Data
Oct 30, 2021


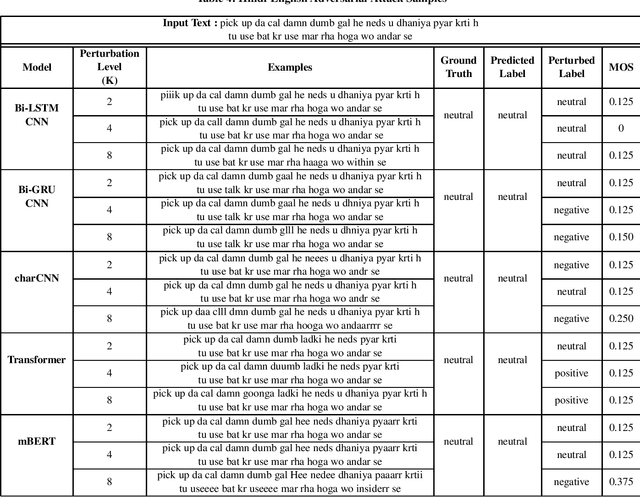
Research on adversarial attacks are becoming widely popular in the recent years. One of the unexplored areas where prior research is lacking is the effect of adversarial attacks on code-mixed data. Therefore, in the present work, we have explained the first generalized framework on text perturbation to attack code-mixed classification models in a black-box setting. We rely on various perturbation techniques that preserve the semantic structures of the sentences and also obscure the attacks from the perception of a human user. The present methodology leverages the importance of a token to decide where to attack by employing various perturbation strategies. We test our strategies on various sentiment classification models trained on Bengali-English and Hindi-English code-mixed datasets, and reduce their F1-scores by nearly 51 % and 53 % respectively, which can be further reduced if a larger number of tokens are perturbed in a given sentence.
Incomplete Gamma Integrals for Deep Cascade Prediction using Content, Network, and Exogenous Signals
Jun 13, 2021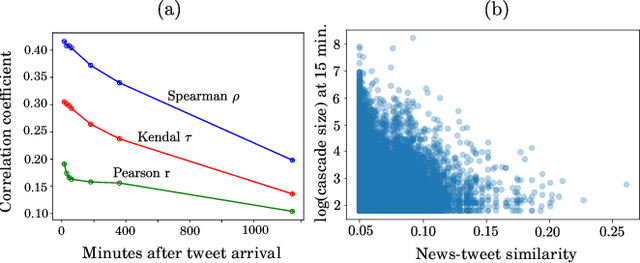

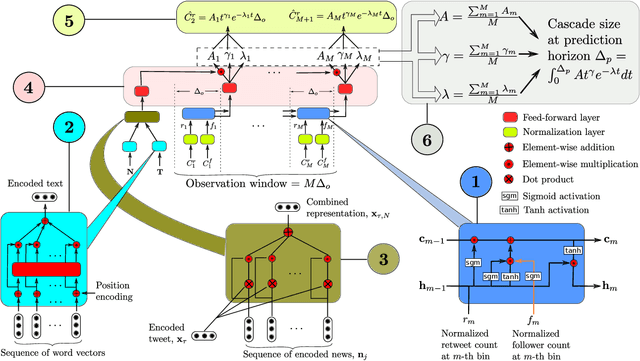
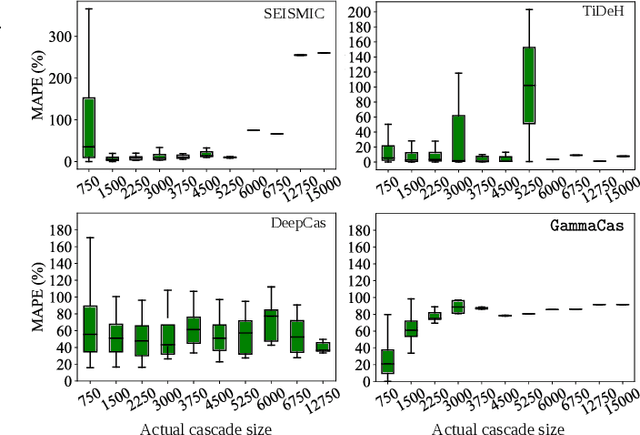
The behaviour of information cascades (such as retweets) has been modelled extensively. While point process-based generative models have long been in use for estimating cascade growths, deep learning has greatly enhanced diverse feature integration. We observe two significant temporal signals in cascade data that have not been emphasized or reported to our knowledge. First, the popularity of the cascade root is known to influence cascade size strongly; but the effect falls off rapidly with time. Second, there is a measurable positive correlation between the novelty of the root content (with respect to a streaming external corpus) and the relative size of the resulting cascade. Responding to these observations, we propose GammaCas, a new cascade growth model as a parametric function of time, which combines deep influence signals from content (e.g., tweet text), network features (e.g., followers of the root user), and exogenous event sources (e.g., online news). Specifically, our model processes these signals through a customized recurrent network, whose states then provide the parameters of the cascade rate function, which is integrated over time to predict the cascade size. The network parameters are trained end-to-end using observed cascades. GammaCas outperforms seven recent and diverse baselines significantly on a large-scale dataset of retweet cascades coupled with time-aligned online news -- it beats the best baseline with an 18.98% increase in terms of Kendall's $\tau$ correlation and $35.63$ reduction in Mean Absolute Percentage Error. Extensive ablation and case studies unearth interesting insights regarding retweet cascade dynamics.
JUNLP@Dravidian-CodeMix-FIRE2020: Sentiment Classification of Code-Mixed Tweets using Bi-Directional RNN and Language Tags
Oct 20, 2020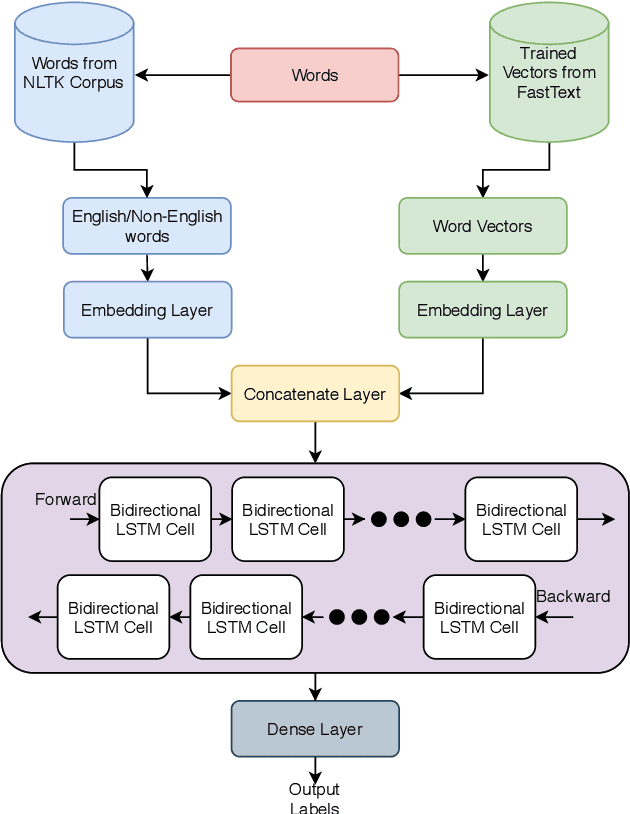


Sentiment analysis has been an active area of research in the past two decades and recently, with the advent of social media, there has been an increasing demand for sentiment analysis on social media texts. Since the social media texts are not in one language and are largely code-mixed in nature, the traditional sentiment classification models fail to produce acceptable results. This paper tries to solve this very research problem and uses bi-directional LSTMs along with language tagging, to facilitate sentiment tagging of code-mixed Tamil texts that have been extracted from social media. The presented algorithm, when evaluated on the test data, garnered precision, recall, and F1 scores of 0.59, 0.66, and 0.58 respectively.
JUNLP@SemEval-2020 Task 9:Sentiment Analysis of Hindi-English code mixed data using Grid Search Cross Validation
Sep 02, 2020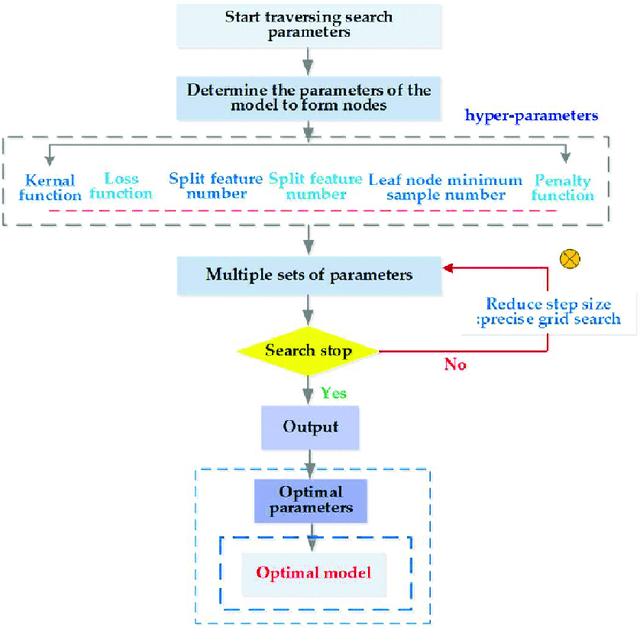
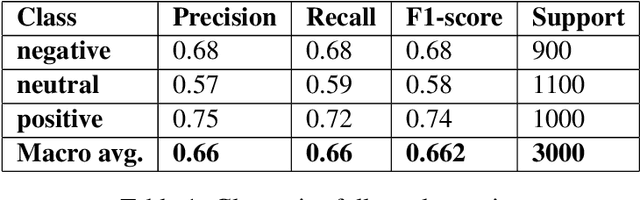
Code-mixing is a phenomenon which arises mainly in multilingual societies. Multilingual people, who are well versed in their native languages and also English speakers, tend to code-mix using English-based phonetic typing and the insertion of anglicisms in their main language. This linguistic phenomenon poses a great challenge to conventional NLP domains such as Sentiment Analysis, Machine Translation, and Text Summarization, to name a few. In this work, we focus on working out a plausible solution to the domain of Code-Mixed Sentiment Analysis. This work was done as participation in the SemEval-2020 Sentimix Task, where we focused on the sentiment analysis of English-Hindi code-mixed sentences. our username for the submission was "sainik.mahata" and team name was "JUNLP". We used feature extraction algorithms in conjunction with traditional machine learning algorithms such as SVR and Grid Search in an attempt to solve the task. Our approach garnered an f1-score of 66.2\% when tested using metrics prepared by the organizers of the task.
Development of POS tagger for English-Bengali Code-Mixed data
Jul 29, 2020
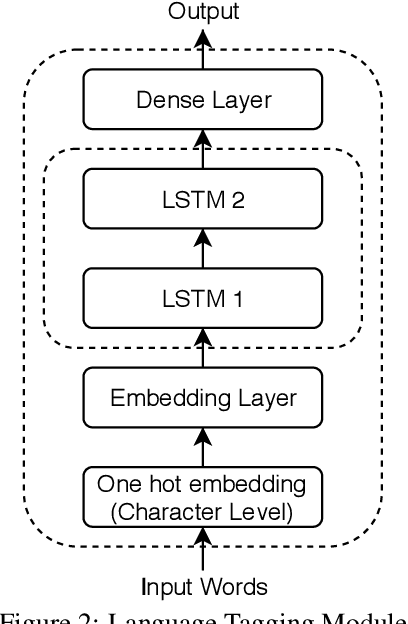
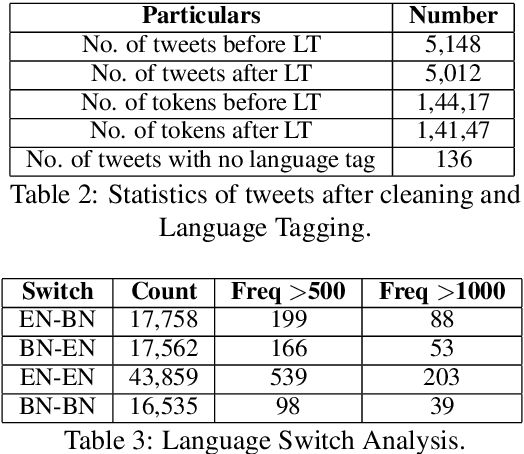
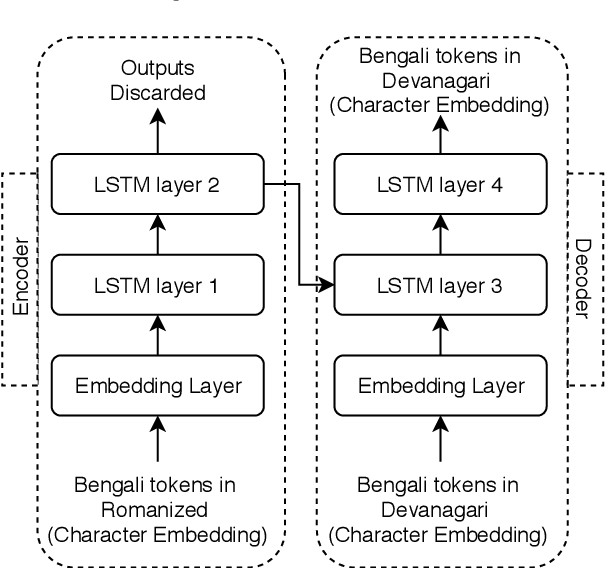
Code-mixed texts are widespread nowadays due to the advent of social media. Since these texts combine two languages to formulate a sentence, it gives rise to various research problems related to Natural Language Processing. In this paper, we try to excavate one such problem, namely, Parts of Speech tagging of code-mixed texts. We have built a system that can POS tag English-Bengali code-mixed data where the Bengali words were written in Roman script. Our approach initially involves the collection and cleaning of English-Bengali code-mixed tweets. These tweets were used as a development dataset for building our system. The proposed system is a modular approach that starts by tagging individual tokens with their respective languages and then passes them to different POS taggers, designed for different languages (English and Bengali, in our case). Tags given by the two systems are later joined together and the final result is then mapped to a universal POS tag set. Our system was checked using 100 manually POS tagged code-mixed sentences and it returned an accuracy of 75.29%