 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Unified Multi-Task Learning Architecture for Hate Detection Leveraging User-Based Information
Nov 12, 2024


Hate speech, offensive language, aggression, racism, sexism, and other abusive language are common phenomena in social media. There is a need for Artificial Intelligence(AI)based intervention which can filter hate content at scale. Most existing hate speech detection solutions have utilized the features by treating each post as an isolated input instance for the classification. This paper addresses this issue by introducing a unique model that improves hate speech identification for the English language by utilising intra-user and inter-user-based information. The experiment is conducted over single-task learning (STL) and multi-task learning (MTL) paradigms that use deep neural networks, such as convolutional neural networks (CNN), gated recurrent unit (GRU), bidirectional encoder representations from the transformer (BERT), and A Lite BERT (ALBERT). We use three benchmark datasets and conclude that combining certain user features with textual features gives significant improvements in macro-F1 and weighted-F1.
Leveraging Multi-domain, Heterogeneous Data using Deep Multitask Learning for Hate Speech Detection
Mar 23, 2021

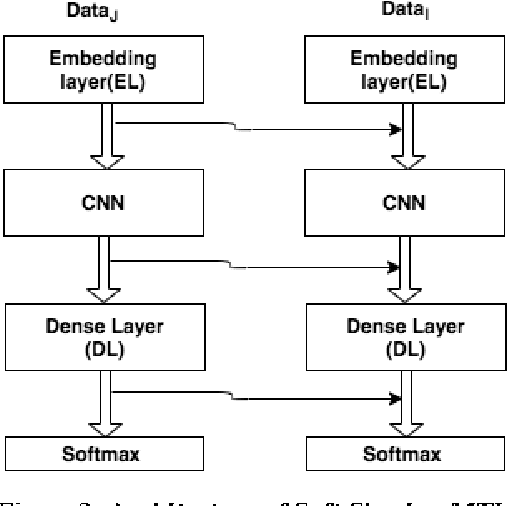
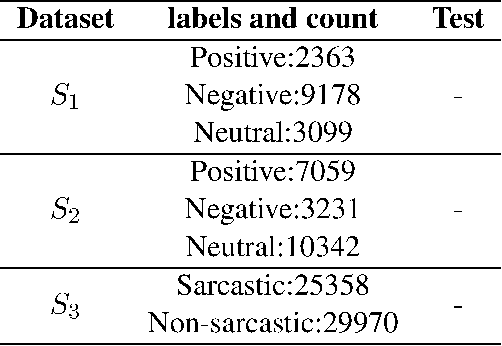
With the exponential rise in user-generated web content on social media, the proliferation of abusive languages towards an individual or a group across the different sections of the internet is also rapidly increasing. It is very challenging for human moderators to identify the offensive contents and filter those out. Deep neural networks have shown promise with reasonable accuracy for hate speech detection and allied applications. However, the classifiers are heavily dependent on the size and quality of the training data. Such a high-quality large data set is not easy to obtain. Moreover, the existing data sets that have emerged in recent times are not created following the same annotation guidelines and are often concerned with different types and sub-types related to hate. To solve this data sparsity problem, and to obtain more global representative features, we propose a Convolution Neural Network (CNN) based multi-task learning models (MTLs)\footnote{code is available at https://github.com/imprasshant/STL-MTL} to leverage information from multiple sources. Empirical analysis performed on three benchmark datasets shows the efficacy of the proposed approach with the significant improvement in accuracy and F-score to obtain state-of-the-art performance with respect to the existing systems.
Investigating Deep Learning Approaches for Hate Speech Detection in Social Media
May 29, 2020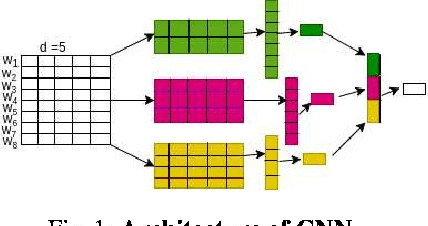



The phenomenal growth on the internet has helped in empowering individual's expressions, but the misuse of freedom of expression has also led to the increase of various cyber crimes and anti-social activities. Hate speech is one such issue that needs to be addressed very seriously as otherwise, this could pose threats to the integrity of the social fabrics. In this paper, we proposed deep learning approaches utilizing various embeddings for detecting various types of hate speeches in social media. Detecting hate speech from a large volume of text, especially tweets which contains limited contextual information also poses several practical challenges. Moreover, the varieties in user-generated data and the presence of various forms of hate speech makes it very challenging to identify the degree and intention of the message. Our experiments on three publicly available datasets of different domains shows a significant improvement in accuracy and F1-score.