 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeJUNLP@Dravidian-CodeMix-FIRE2020: Sentiment Classification of Code-Mixed Tweets using Bi-Directional RNN and Language Tags
Oct 20, 2020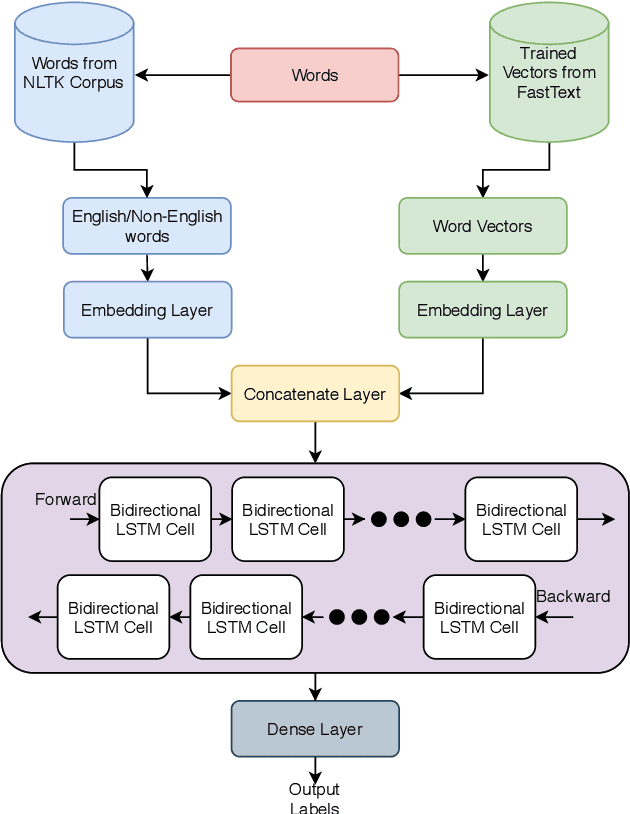


Sentiment analysis has been an active area of research in the past two decades and recently, with the advent of social media, there has been an increasing demand for sentiment analysis on social media texts. Since the social media texts are not in one language and are largely code-mixed in nature, the traditional sentiment classification models fail to produce acceptable results. This paper tries to solve this very research problem and uses bi-directional LSTMs along with language tagging, to facilitate sentiment tagging of code-mixed Tamil texts that have been extracted from social media. The presented algorithm, when evaluated on the test data, garnered precision, recall, and F1 scores of 0.59, 0.66, and 0.58 respectively.
JUNLP@SemEval-2020 Task 9:Sentiment Analysis of Hindi-English code mixed data using Grid Search Cross Validation
Sep 02, 2020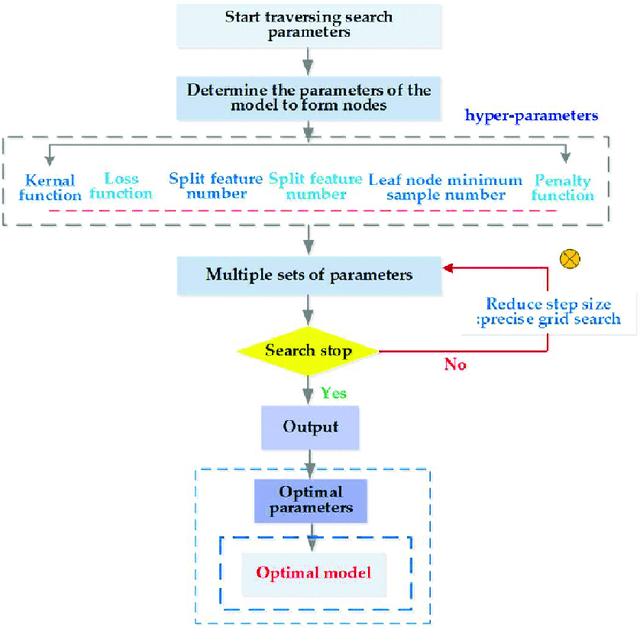
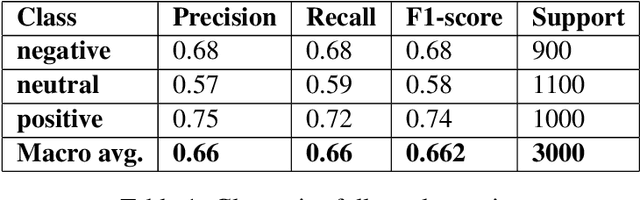
Code-mixing is a phenomenon which arises mainly in multilingual societies. Multilingual people, who are well versed in their native languages and also English speakers, tend to code-mix using English-based phonetic typing and the insertion of anglicisms in their main language. This linguistic phenomenon poses a great challenge to conventional NLP domains such as Sentiment Analysis, Machine Translation, and Text Summarization, to name a few. In this work, we focus on working out a plausible solution to the domain of Code-Mixed Sentiment Analysis. This work was done as participation in the SemEval-2020 Sentimix Task, where we focused on the sentiment analysis of English-Hindi code-mixed sentences. our username for the submission was "sainik.mahata" and team name was "JUNLP". We used feature extraction algorithms in conjunction with traditional machine learning algorithms such as SVR and Grid Search in an attempt to solve the task. Our approach garnered an f1-score of 66.2\% when tested using metrics prepared by the organizers of the task.
Development of POS tagger for English-Bengali Code-Mixed data
Jul 29, 2020
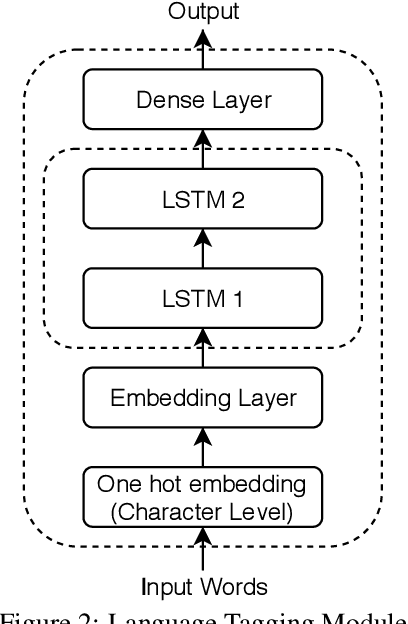
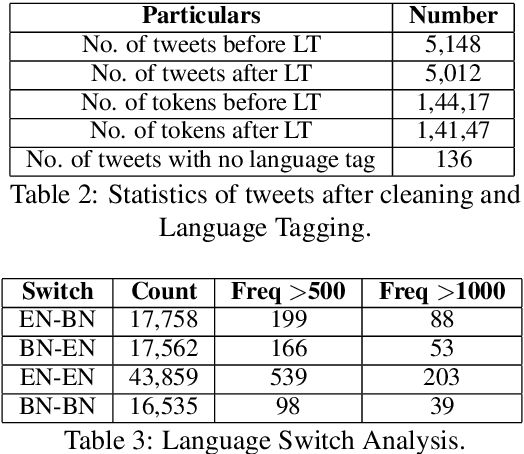
Code-mixed texts are widespread nowadays due to the advent of social media. Since these texts combine two languages to formulate a sentence, it gives rise to various research problems related to Natural Language Processing. In this paper, we try to excavate one such problem, namely, Parts of Speech tagging of code-mixed texts. We have built a system that can POS tag English-Bengali code-mixed data where the Bengali words were written in Roman script. Our approach initially involves the collection and cleaning of English-Bengali code-mixed tweets. These tweets were used as a development dataset for building our system. The proposed system is a modular approach that starts by tagging individual tokens with their respective languages and then passes them to different POS taggers, designed for different languages (English and Bengali, in our case). Tags given by the two systems are later joined together and the final result is then mapped to a universal POS tag set. Our system was checked using 100 manually POS tagged code-mixed sentences and it returned an accuracy of 75.29%
Preparation of Sentiment tagged Parallel Corpus and Testing its effect on Machine Translation
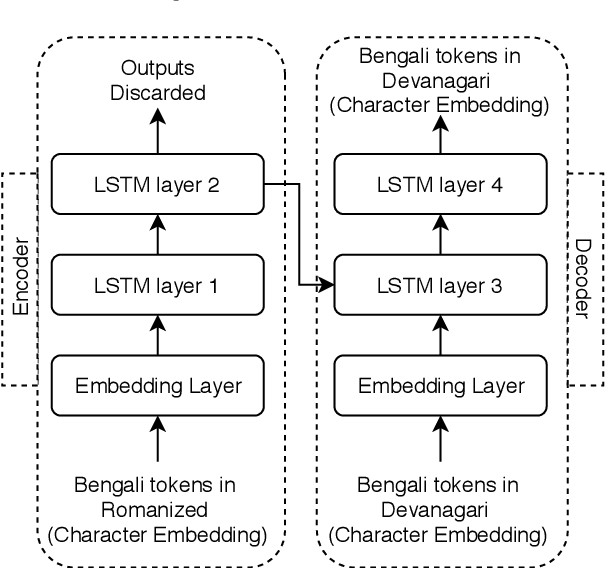
Jul 28, 2020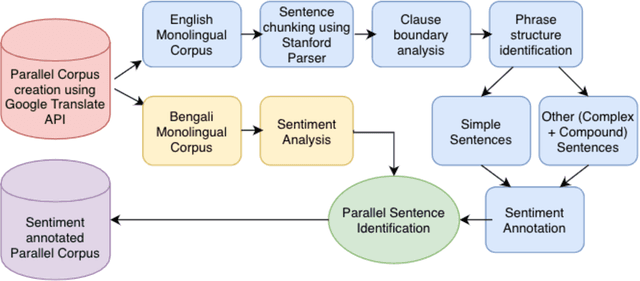
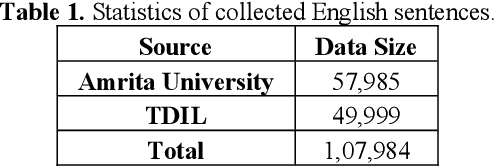

In the current work, we explore the enrichment in the machine translation output when the training parallel corpus is augmented with the introduction of sentiment analysis. The paper discusses the preparation of the same sentiment tagged English-Bengali parallel corpus. The preparation of raw parallel corpus, sentiment analysis of the sentences and the training of a Character Based Neural Machine Translation model using the same has been discussed extensively in this paper. The output of the translation model has been compared with a base-line translation model using automated metrics such as BLEU and TER as well as manually.
Code-Mixed to Monolingual Translation Framework
Nov 22, 2019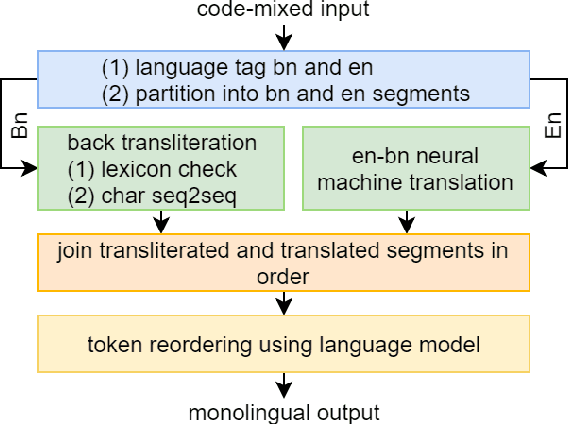
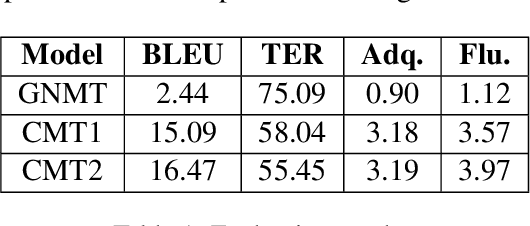
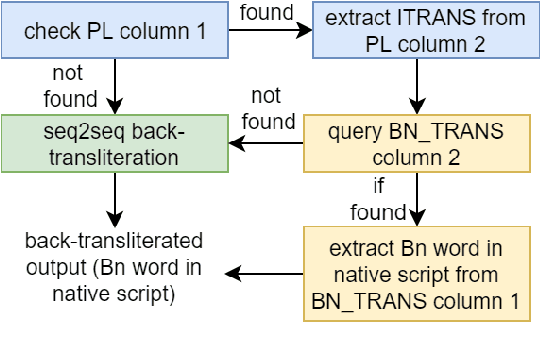
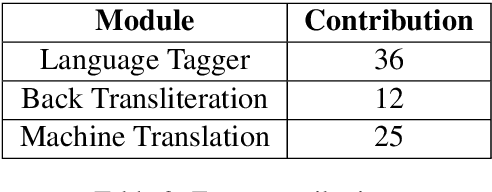
The use of multilingualism in the new generation is widespread in the form of code-mixed data on social media, and therefore a robust translation system is required for catering to the monolingual users, as well as for easier comprehension by language processing models. In this work, we present a translation framework that uses a translation-transliteration strategy for translating code-mixed data into their equivalent monolingual instances. For converting the output to a more fluent form, it is reordered using a target language model. The most important advantage of the proposed framework is that it does not require a code-mixed to monolingual parallel corpus at any point. On testing the framework, it achieved BLEU and TER scores of 16.47 and 55.45, respectively. Since the proposed framework deals with various sub-modules, we dive deeper into the importance of each of them, analyze the errors and finally, discuss some improvement strategies.
JUMT at WMT2019 News Translation Task: A Hybrid approach to Machine Translation for Lithuanian to English
Aug 01, 2019
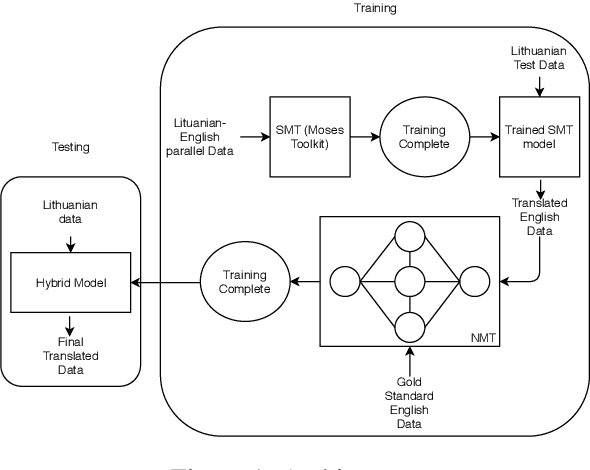
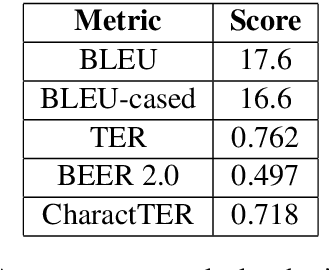
In the current work, we present a description of the system submitted to WMT 2019 News Translation Shared task. The system was created to translate news text from Lithuanian to English. To accomplish the given task, our system used a Word Embedding based Neural Machine Translation model to post edit the outputs generated by a Statistical Machine Translation model. The current paper documents the architecture of our model, descriptions of the various modules and the results produced using the same. Our system garnered a BLEU score of 17.6.
JUCBNMT at WMT2018 News Translation Task: Character Based Neural Machine Translation of Finnish to English
Aug 01, 2019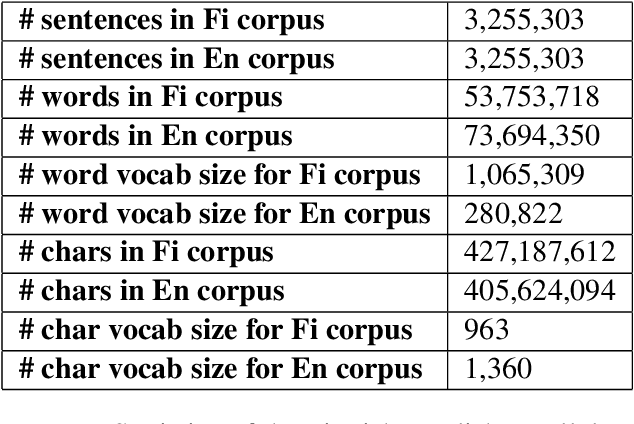


In the current work, we present a description of the system submitted to WMT 2018 News Translation Shared task. The system was created to translate news text from Finnish to English. The system used a Character Based Neural Machine Translation model to accomplish the given task. The current paper documents the preprocessing steps, the description of the submitted system and the results produced using the same. Our system garnered a BLEU score of 12.9.
Sentiment Analysis at SEPLN (TASS)-2019: Sentiment Analysis at Tweet level using Deep Learning
Aug 01, 2019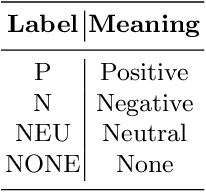


This paper describes the system submitted to "Sentiment Analysis at SEPLN (TASS)-2019" shared task. The task includes sentiment analysis of Spanish tweets, where the tweets are in different dialects spoken in Spain, Peru, Costa Rica, Uruguay and Mexico. The tweets are short (up to 240 characters) and the language is informal, i.e., it contains misspellings, emojis, onomatopeias etc. Sentiment analysis includes classification of the tweets into 4 classes, viz., Positive, Negative, Neutral and None. For preparing the proposed system, we use Deep Learning networks like LSTMs.
Normalyzing Numeronyms -- A NLP approach
Jul 31, 2019

This paper presents a method to apply Natural Language Processing for normalizing numeronyms to make them understandable by humans. We approach the problem through a two-step mechanism. We make use of the state of the art Levenshtein distance of words. We then apply Cosine Similarity for selection of the normalized text and reach greater accuracy in solving the problem. Our approach garners accuracy figures of 71\% and 72\% for Bengali and English language, respectively.
SMT vs NMT: A Comparison over Hindi & Bengali Simple Sentences
Dec 12, 2018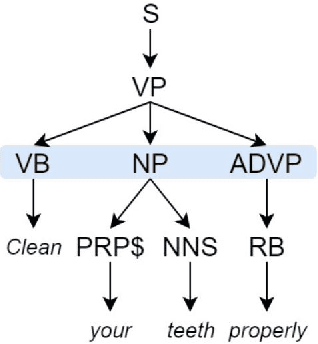
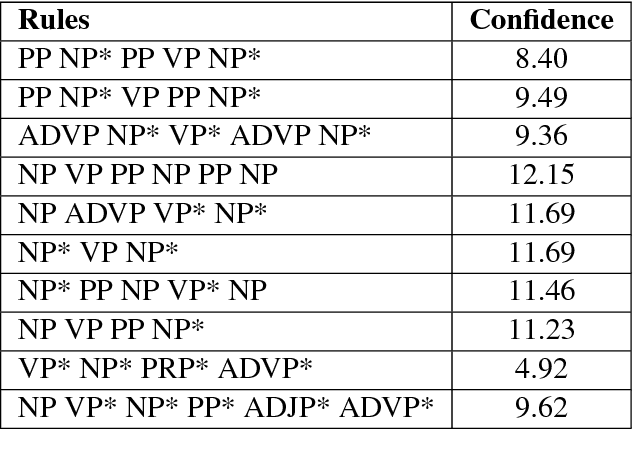
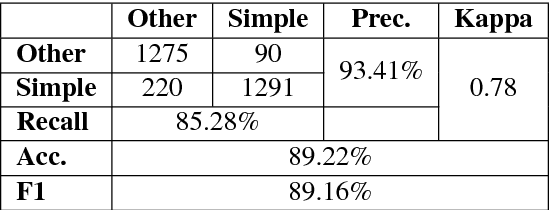
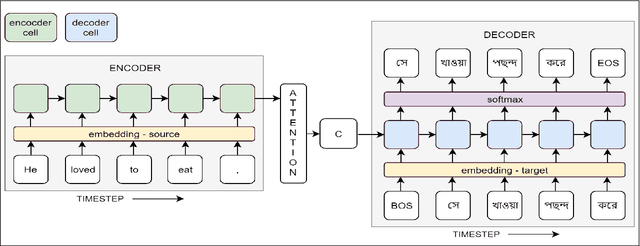
In the present article, we identified the qualitative differences between Statistical Machine Translation (SMT) and Neural Machine Translation (NMT) outputs. We have tried to answer two important questions: 1. Does NMT perform equivalently well with respect to SMT and 2. Does it add extra flavor in improving the quality of MT output by employing simple sentences as training units. In order to obtain insights, we have developed three core models viz., SMT model based on Moses toolkit, followed by character and word level NMT models. All of the systems use English-Hindi and English-Bengali language pairs containing simple sentences as well as sentences of other complexity. In order to preserve the translations semantics with respect to the target words of a sentence, we have employed soft-attention into our word level NMT model. We have further evaluated all the systems with respect to the scenarios where they succeed and fail. Finally, the quality of translation has been validated using BLEU and TER metrics along with manual parameters like fluency, adequacy etc. We observed that NMT outperforms SMT in case of simple sentences whereas SMT outperforms in case of all types of sentence.