 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGarain at SemEval-2020 Task 12: Sequence based Deep Learning for Categorizing Offensive Language in Social Media
Sep 02, 2020
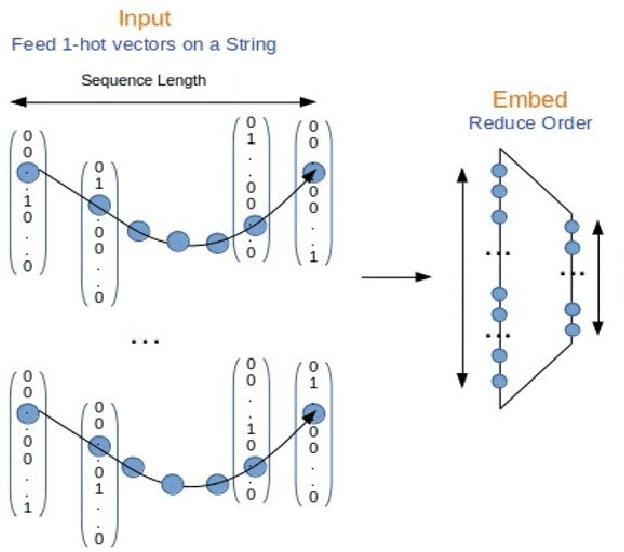
SemEval-2020 Task 12 was OffenseEval: Multilingual Offensive Language Identification in Social Media (Zampieri et al., 2020). The task was subdivided into multiple languages and datasets were provided for each one. The task was further divided into three sub-tasks: offensive language identification, automatic categorization of offense types, and offense target identification. I have participated in the task-C, that is, offense target identification. For preparing the proposed system, I have made use of Deep Learning networks like LSTMs and frameworks like Keras which combine the bag of words model with automatically generated sequence based features and manually extracted features from the given dataset. My system on training on 25% of the whole dataset achieves macro averaged f1 score of 47.763%.
JUNLP@SemEval-2020 Task 9:Sentiment Analysis of Hindi-English code mixed data using Grid Search Cross Validation
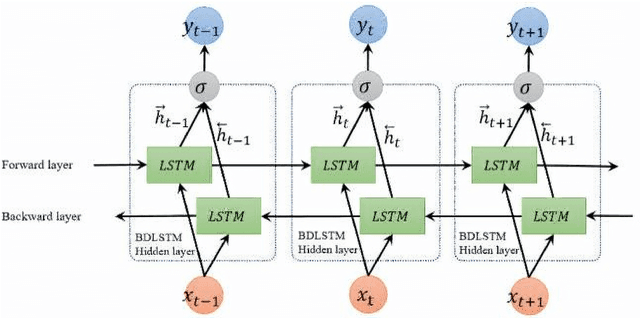
Sep 02, 2020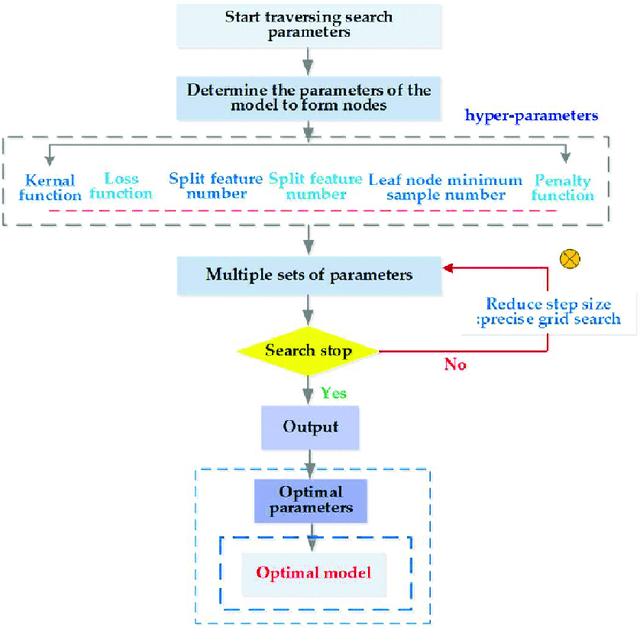
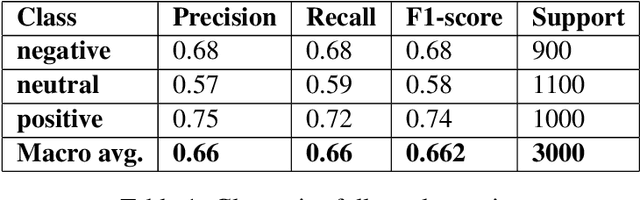
Code-mixing is a phenomenon which arises mainly in multilingual societies. Multilingual people, who are well versed in their native languages and also English speakers, tend to code-mix using English-based phonetic typing and the insertion of anglicisms in their main language. This linguistic phenomenon poses a great challenge to conventional NLP domains such as Sentiment Analysis, Machine Translation, and Text Summarization, to name a few. In this work, we focus on working out a plausible solution to the domain of Code-Mixed Sentiment Analysis. This work was done as participation in the SemEval-2020 Sentimix Task, where we focused on the sentiment analysis of English-Hindi code-mixed sentences. our username for the submission was "sainik.mahata" and team name was "JUNLP". We used feature extraction algorithms in conjunction with traditional machine learning algorithms such as SVR and Grid Search in an attempt to solve the task. Our approach garnered an f1-score of 66.2\% when tested using metrics prepared by the organizers of the task.
JUMT at WMT2019 News Translation Task: A Hybrid approach to Machine Translation for Lithuanian to English
Aug 01, 2019
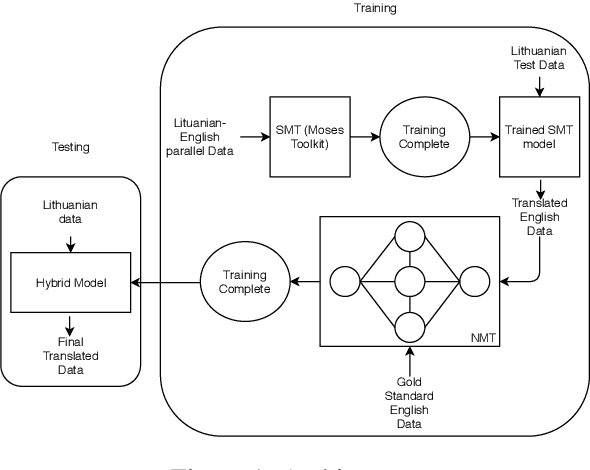
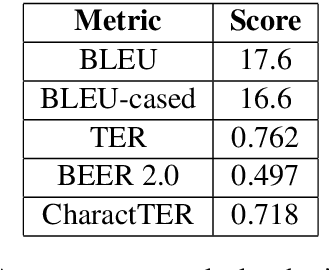
In the current work, we present a description of the system submitted to WMT 2019 News Translation Shared task. The system was created to translate news text from Lithuanian to English. To accomplish the given task, our system used a Word Embedding based Neural Machine Translation model to post edit the outputs generated by a Statistical Machine Translation model. The current paper documents the architecture of our model, descriptions of the various modules and the results produced using the same. Our system garnered a BLEU score of 17.6.
Sentiment Analysis at SEPLN (TASS)-2019: Sentiment Analysis at Tweet level using Deep Learning
Aug 01, 2019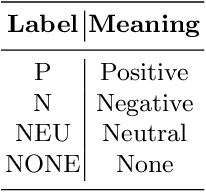
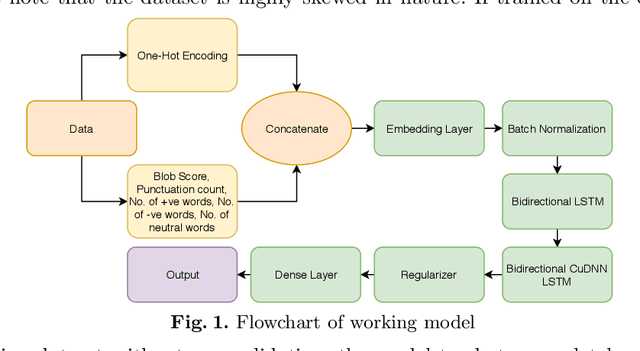


This paper describes the system submitted to "Sentiment Analysis at SEPLN (TASS)-2019" shared task. The task includes sentiment analysis of Spanish tweets, where the tweets are in different dialects spoken in Spain, Peru, Costa Rica, Uruguay and Mexico. The tweets are short (up to 240 characters) and the language is informal, i.e., it contains misspellings, emojis, onomatopeias etc. Sentiment analysis includes classification of the tweets into 4 classes, viz., Positive, Negative, Neutral and None. For preparing the proposed system, we use Deep Learning networks like LSTMs.
Normalyzing Numeronyms -- A NLP approach
Jul 31, 2019

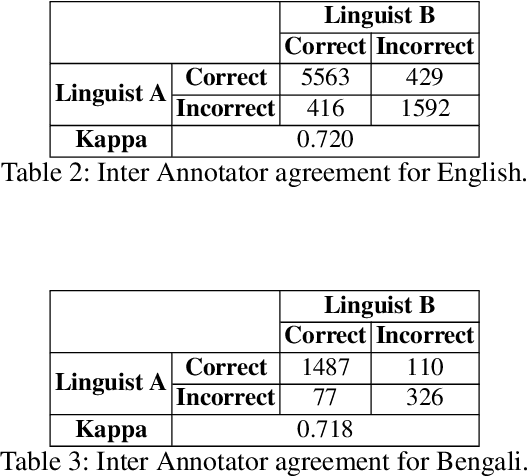
This paper presents a method to apply Natural Language Processing for normalizing numeronyms to make them understandable by humans. We approach the problem through a two-step mechanism. We make use of the state of the art Levenshtein distance of words. We then apply Cosine Similarity for selection of the normalized text and reach greater accuracy in solving the problem. Our approach garners accuracy figures of 71\% and 72\% for Bengali and English language, respectively.