 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Comprehensive Review on Recent Methods and Challenges of Video Description
Nov 30, 2020
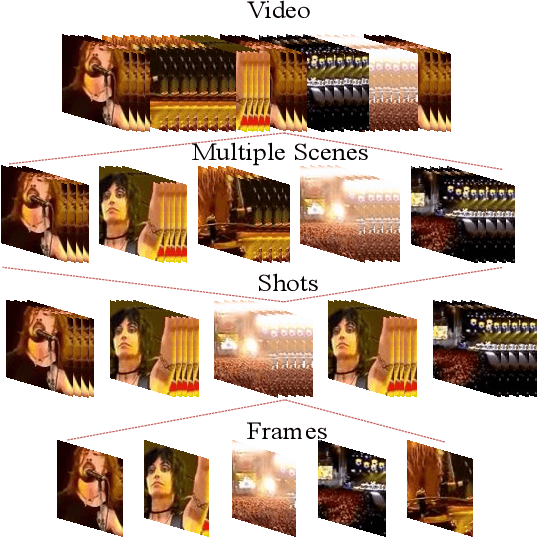
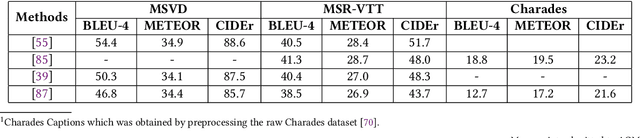
Video description involves the generation of the natural language description of actions, events, and objects in the video. There are various applications of video description by filling the gap between languages and vision for visually impaired people, generating automatic title suggestion based on content, browsing of the video based on the content and video-guided machine translation [86] etc.In the past decade, several works had been done in this field in terms of approaches/methods for video description, evaluation metrics,and datasets. For analyzing the progress in the video description task, a comprehensive survey is needed that covers all the phases of video description approaches with a special focus on recent deep learning approaches. In this work, we report a comprehensive survey on the phases of video description approaches, the dataset for video description, evaluation metrics, open competitions for motivating the research on the video description, open challenges in this field, and future research directions. In this survey, we cover the state-of-the-art approaches proposed for each and every dataset with their pros and cons. For the growth of this research domain,the availability of numerous benchmark dataset is a basic need. Further, we categorize all the dataset into two classes: open domain dataset and domain-specific dataset. From our survey, we observe that the work in this field is in fast-paced development since the task of video description falls in the intersection of computer vision and natural language processing. But still, the work in the video description is far from saturation stage due to various challenges like the redundancy due to similar frames which affect the quality of visual features, the availability of dataset containing more diverse content and availability of an effective evaluation metric.
JUNLP@Dravidian-CodeMix-FIRE2020: Sentiment Classification of Code-Mixed Tweets using Bi-Directional RNN and Language Tags
Oct 20, 2020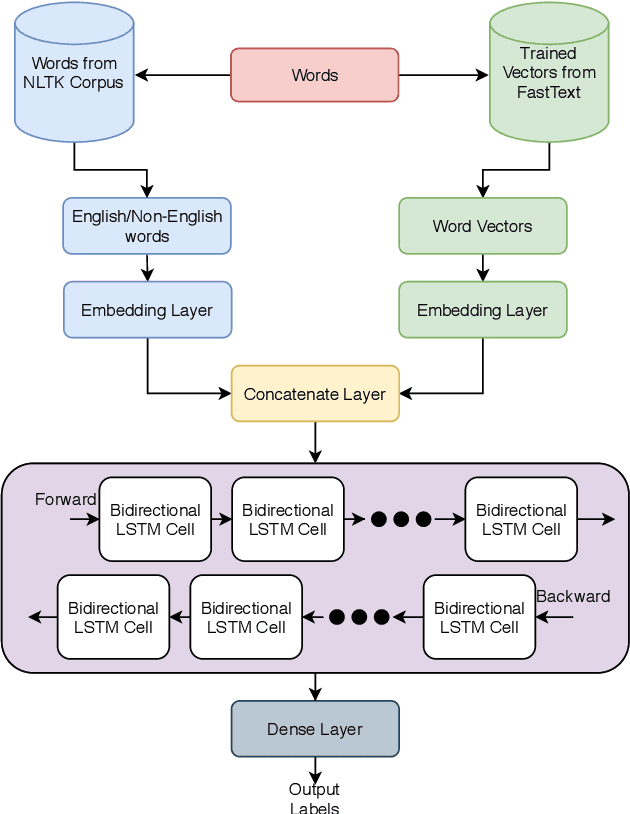


Sentiment analysis has been an active area of research in the past two decades and recently, with the advent of social media, there has been an increasing demand for sentiment analysis on social media texts. Since the social media texts are not in one language and are largely code-mixed in nature, the traditional sentiment classification models fail to produce acceptable results. This paper tries to solve this very research problem and uses bi-directional LSTMs along with language tagging, to facilitate sentiment tagging of code-mixed Tamil texts that have been extracted from social media. The presented algorithm, when evaluated on the test data, garnered precision, recall, and F1 scores of 0.59, 0.66, and 0.58 respectively.
Classifier Combination Approach for Question Classification for Bengali Question Answering System
Sep 06, 2020
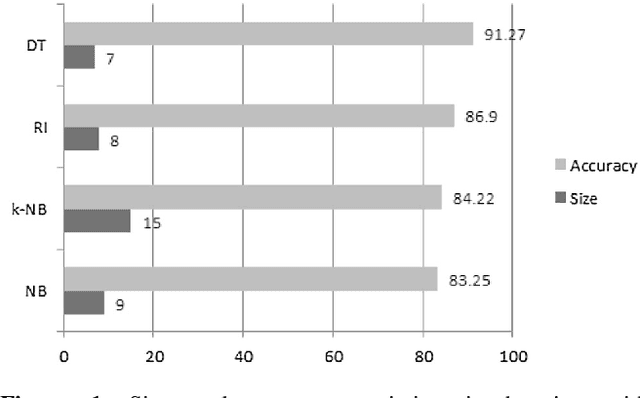

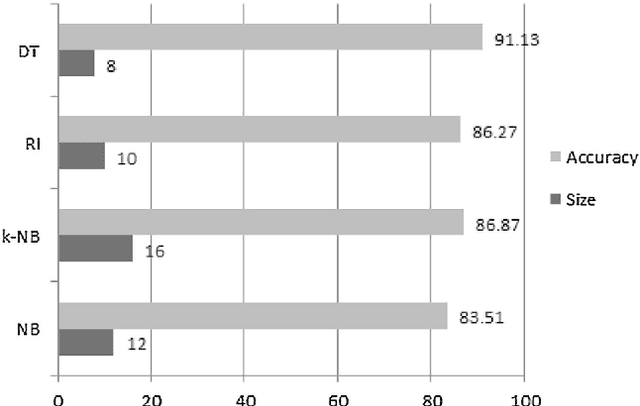
Question classification (QC) is a prime constituent of automated question answering system. The work presented here demonstrates that the combination of multiple models achieve better classification performance than those obtained with existing individual models for the question classification task in Bengali. We have exploited state-of-the-art multiple model combination techniques, i.e., ensemble, stacking and voting, to increase QC accuracy. Lexical, syntactic and semantic features of Bengali questions are used for four well-known classifiers, namely Na\"{\i}ve Bayes, kernel Na\"{\i}ve Bayes, Rule Induction, and Decision Tree, which serve as our base learners. Single-layer question-class taxonomy with 8 coarse-grained classes is extended to two-layer taxonomy by adding 69 fine-grained classes. We carried out the experiments both on single-layer and two-layer taxonomies. Experimental results confirmed that classifier combination approaches outperform single classifier classification approaches by 4.02% for coarse-grained question classes. Overall, the stacking approach produces the best results for fine-grained classification and achieves 87.79% of accuracy. The approach presented here could be used in other Indo-Aryan or Indic languages to develop a question answering system.
* 16 pages, to be published in Sadhana
Development of POS tagger for English-Bengali Code-Mixed data
Jul 29, 2020
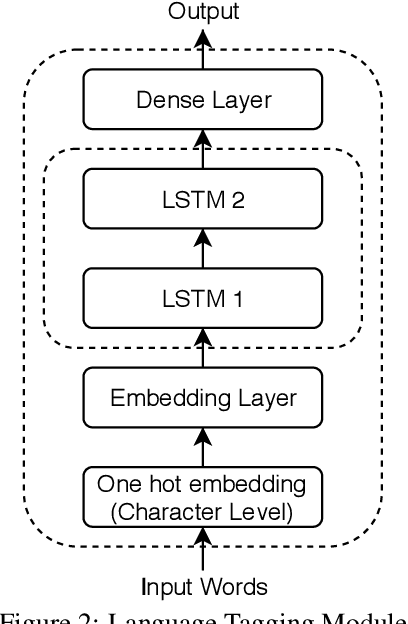
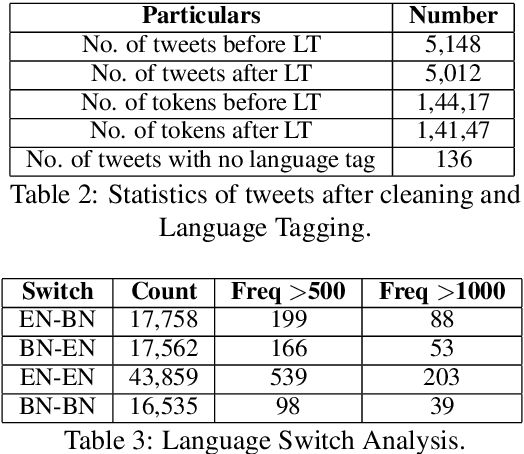
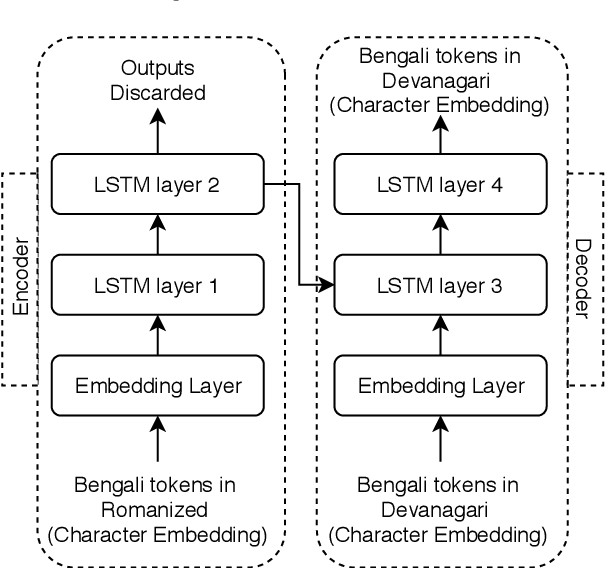
Code-mixed texts are widespread nowadays due to the advent of social media. Since these texts combine two languages to formulate a sentence, it gives rise to various research problems related to Natural Language Processing. In this paper, we try to excavate one such problem, namely, Parts of Speech tagging of code-mixed texts. We have built a system that can POS tag English-Bengali code-mixed data where the Bengali words were written in Roman script. Our approach initially involves the collection and cleaning of English-Bengali code-mixed tweets. These tweets were used as a development dataset for building our system. The proposed system is a modular approach that starts by tagging individual tokens with their respective languages and then passes them to different POS taggers, designed for different languages (English and Bengali, in our case). Tags given by the two systems are later joined together and the final result is then mapped to a universal POS tag set. Our system was checked using 100 manually POS tagged code-mixed sentences and it returned an accuracy of 75.29%
Preparation of Sentiment tagged Parallel Corpus and Testing its effect on Machine Translation
Jul 28, 2020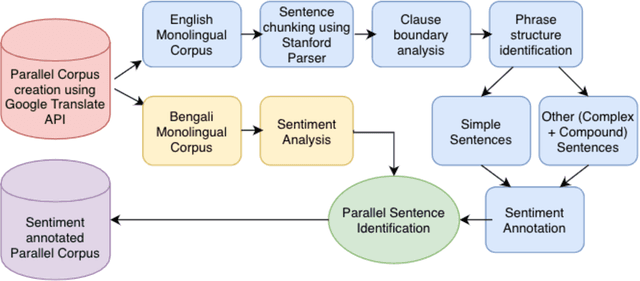
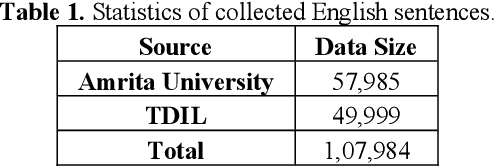

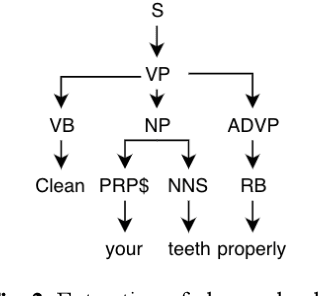
In the current work, we explore the enrichment in the machine translation output when the training parallel corpus is augmented with the introduction of sentiment analysis. The paper discusses the preparation of the same sentiment tagged English-Bengali parallel corpus. The preparation of raw parallel corpus, sentiment analysis of the sentences and the training of a Character Based Neural Machine Translation model using the same has been discussed extensively in this paper. The output of the translation model has been compared with a base-line translation model using automated metrics such as BLEU and TER as well as manually.
Seq2Seq and Joint Learning Based Unix Command Line Prediction System
Jun 20, 2020
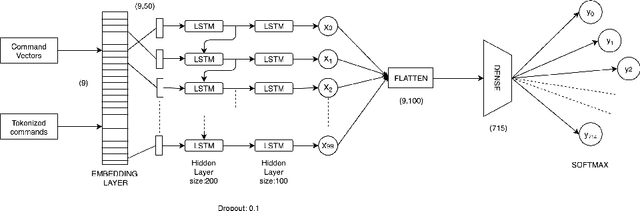
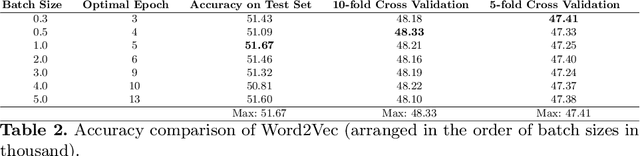

Despite being an open-source operating system pioneered in the early 90s, UNIX based platforms have not been able to garner an overwhelming reception from amateur end users. One of the rationales for under popularity of UNIX based systems is the steep learning curve corresponding to them due to extensive use of command line interface instead of usual interactive graphical user interface. In past years, the majority of insights used to explore the concern are eminently centered around the notion of utilizing chronic log history of the user to make the prediction of successive command. The approaches directed at anatomization of this notion are predominantly in accordance with Probabilistic inference models. The techniques employed in past, however, have not been competent enough to address the predicament as legitimately as anticipated. Instead of deploying usual mechanism of recommendation systems, we have employed a simple yet novel approach of Seq2seq model by leveraging continuous representations of self-curated exhaustive Knowledge Base (KB) to enhance the embedding employed in the model. This work describes an assistive, adaptive and dynamic way of enhancing UNIX command line prediction systems. Experimental methods state that our model has achieved accuracy surpassing mixture of other techniques and adaptive command line interface mechanism as acclaimed in the past.
NITS-VC System for VATEX Video Captioning Challenge 2020
Jun 07, 2020


Video captioning is process of summarising the content, event and action of the video into a short textual form which can be helpful in many research areas such as video guided machine translation, video sentiment analysis and providing aid to needy individual. In this paper, a system description of the framework used for VATEX-2020 video captioning challenge is presented. We employ an encoder-decoder based approach in which the visual features of the video are encoded using 3D convolutional neural network (C3D) and in the decoding phase two Long Short Term Memory (LSTM) recurrent networks are used in which visual features and input captions are fused separately and final output is generated by performing element-wise product between the output of both LSTMs. Our model is able to achieve BLEU scores of 0.20 and 0.22 on public and private test data sets respectively.
Code-Mixed to Monolingual Translation Framework
Nov 22, 2019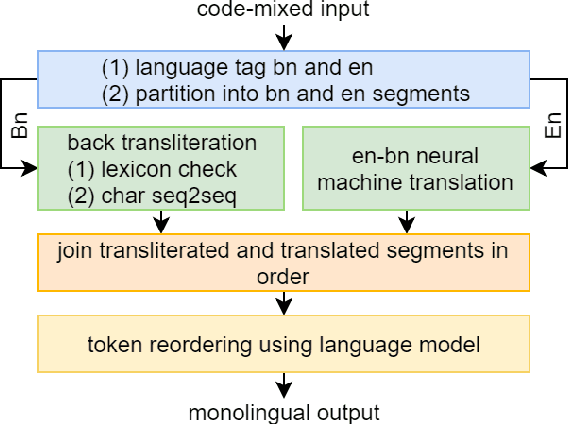
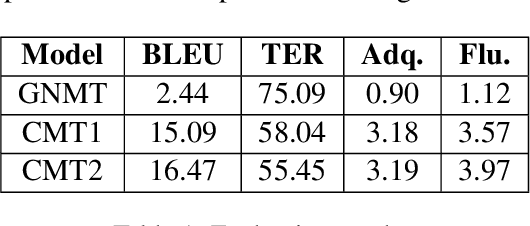
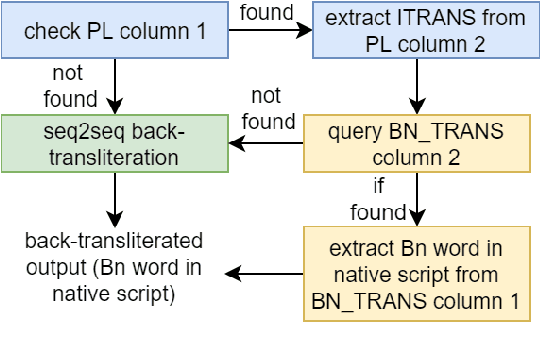
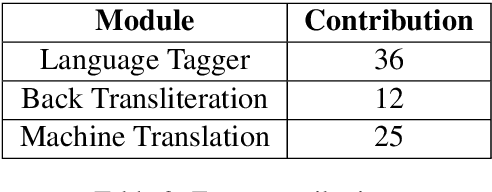
The use of multilingualism in the new generation is widespread in the form of code-mixed data on social media, and therefore a robust translation system is required for catering to the monolingual users, as well as for easier comprehension by language processing models. In this work, we present a translation framework that uses a translation-transliteration strategy for translating code-mixed data into their equivalent monolingual instances. For converting the output to a more fluent form, it is reordered using a target language model. The most important advantage of the proposed framework is that it does not require a code-mixed to monolingual parallel corpus at any point. On testing the framework, it achieved BLEU and TER scores of 16.47 and 55.45, respectively. Since the proposed framework deals with various sub-modules, we dive deeper into the importance of each of them, analyze the errors and finally, discuss some improvement strategies.
JUMT at WMT2019 News Translation Task: A Hybrid approach to Machine Translation for Lithuanian to English
Aug 01, 2019
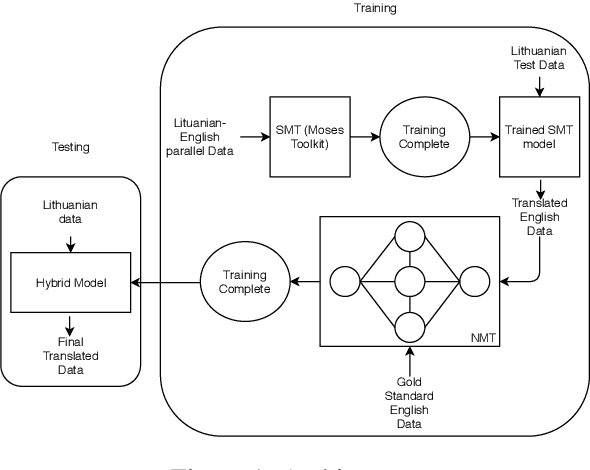
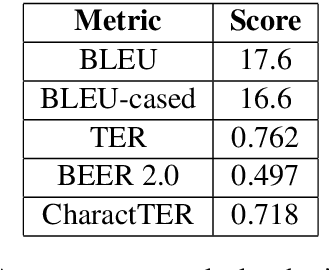
In the current work, we present a description of the system submitted to WMT 2019 News Translation Shared task. The system was created to translate news text from Lithuanian to English. To accomplish the given task, our system used a Word Embedding based Neural Machine Translation model to post edit the outputs generated by a Statistical Machine Translation model. The current paper documents the architecture of our model, descriptions of the various modules and the results produced using the same. Our system garnered a BLEU score of 17.6.
JUCBNMT at WMT2018 News Translation Task: Character Based Neural Machine Translation of Finnish to English
Aug 01, 2019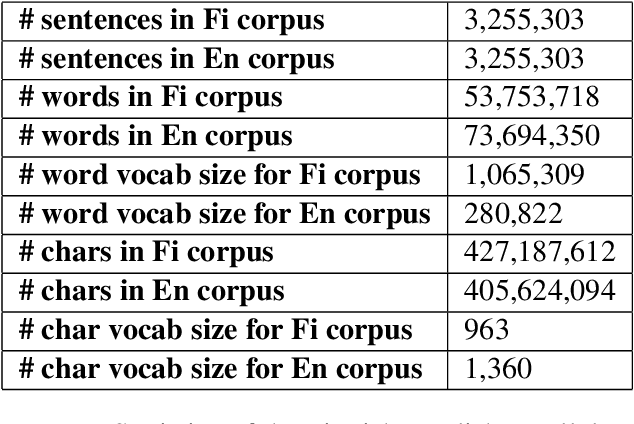


In the current work, we present a description of the system submitted to WMT 2018 News Translation Shared task. The system was created to translate news text from Finnish to English. The system used a Character Based Neural Machine Translation model to accomplish the given task. The current paper documents the preprocessing steps, the description of the submitted system and the results produced using the same. Our system garnered a BLEU score of 12.9.