 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSketching without Worrying: Noise-Tolerant Sketch-Based Image Retrieval
Mar 28, 2022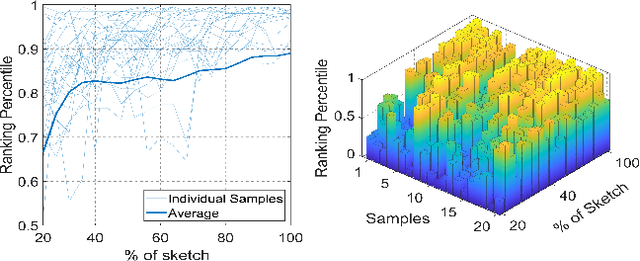
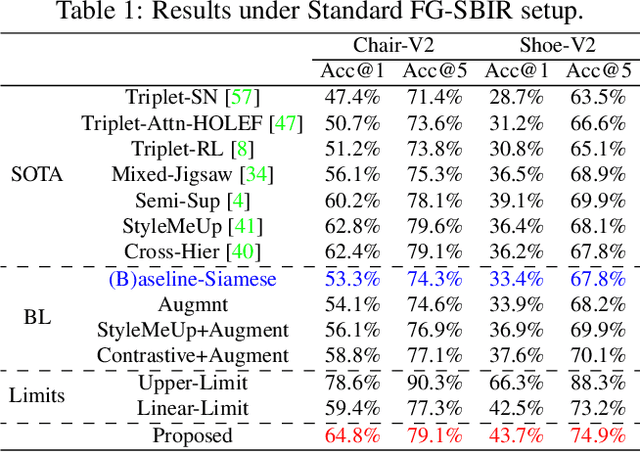

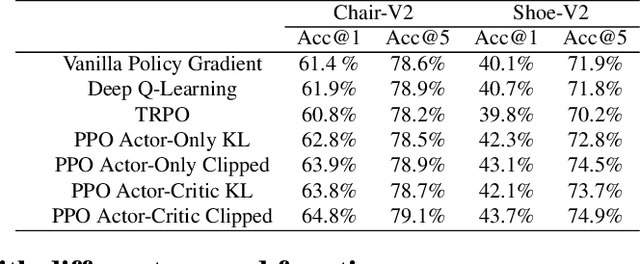
Sketching enables many exciting applications, notably, image retrieval. The fear-to-sketch problem (i.e., "I can't sketch") has however proven to be fatal for its widespread adoption. This paper tackles this "fear" head on, and for the first time, proposes an auxiliary module for existing retrieval models that predominantly lets the users sketch without having to worry. We first conducted a pilot study that revealed the secret lies in the existence of noisy strokes, but not so much of the "I can't sketch". We consequently design a stroke subset selector that {detects noisy strokes, leaving only those} which make a positive contribution towards successful retrieval. Our Reinforcement Learning based formulation quantifies the importance of each stroke present in a given subset, based on the extent to which that stroke contributes to retrieval. When combined with pre-trained retrieval models as a pre-processing module, we achieve a significant gain of 8%-10% over standard baselines and in turn report new state-of-the-art performance. Last but not least, we demonstrate the selector once trained, can also be used in a plug-and-play manner to empower various sketch applications in ways that were not previously possible.
Deep Neural Network for Musical Instrument Recognition using MFCCs
May 05, 2021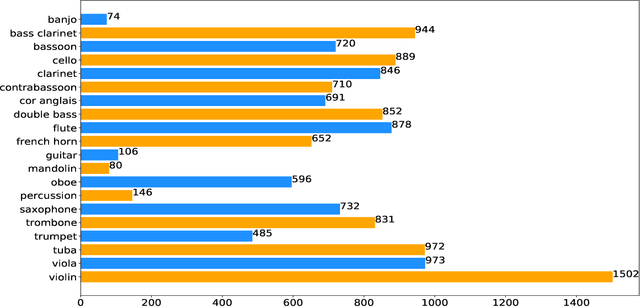
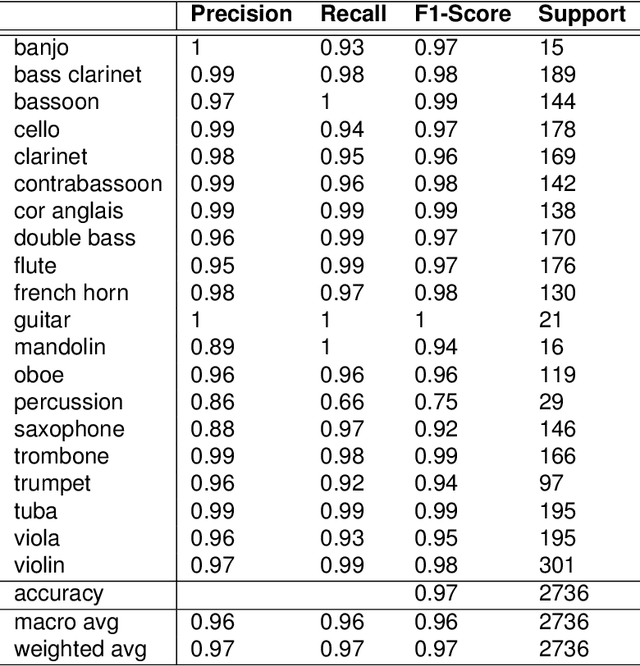
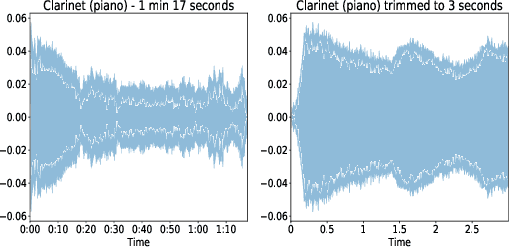
The task of efficient automatic music classification is of vital importance and forms the basis for various advanced applications of AI in the musical domain. Musical instrument recognition is the task of instrument identification by virtue of its audio. This audio, also termed as the sound vibrations are leveraged by the model to match with the instrument classes. In this paper, we use an artificial neural network (ANN) model that was trained to perform classification on twenty different classes of musical instruments. Here we use use only the mel-frequency cepstral coefficients (MFCCs) of the audio data. Our proposed model trains on the full London philharmonic orchestra dataset which contains twenty classes of instruments belonging to the four families viz. woodwinds, brass, percussion, and strings. Based on experimental results our model achieves state-of-the-art accuracy on the same.
* Was suggested to upload on a later date
Seq2Seq and Joint Learning Based Unix Command Line Prediction System
Jun 20, 2020
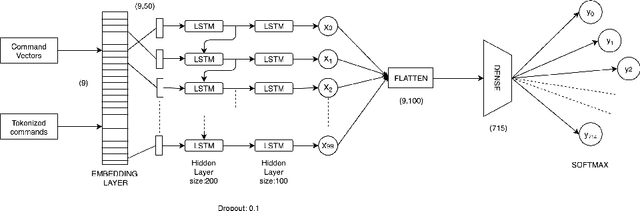
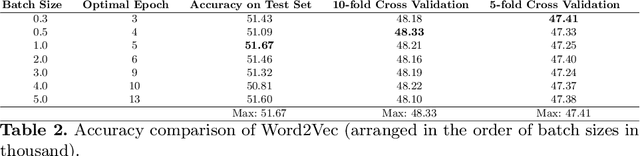

Despite being an open-source operating system pioneered in the early 90s, UNIX based platforms have not been able to garner an overwhelming reception from amateur end users. One of the rationales for under popularity of UNIX based systems is the steep learning curve corresponding to them due to extensive use of command line interface instead of usual interactive graphical user interface. In past years, the majority of insights used to explore the concern are eminently centered around the notion of utilizing chronic log history of the user to make the prediction of successive command. The approaches directed at anatomization of this notion are predominantly in accordance with Probabilistic inference models. The techniques employed in past, however, have not been competent enough to address the predicament as legitimately as anticipated. Instead of deploying usual mechanism of recommendation systems, we have employed a simple yet novel approach of Seq2seq model by leveraging continuous representations of self-curated exhaustive Knowledge Base (KB) to enhance the embedding employed in the model. This work describes an assistive, adaptive and dynamic way of enhancing UNIX command line prediction systems. Experimental methods state that our model has achieved accuracy surpassing mixture of other techniques and adaptive command line interface mechanism as acclaimed in the past.