 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDynG2G: An Efficient Stochastic Graph Embedding Method for Temporal Graphs
Sep 28, 2021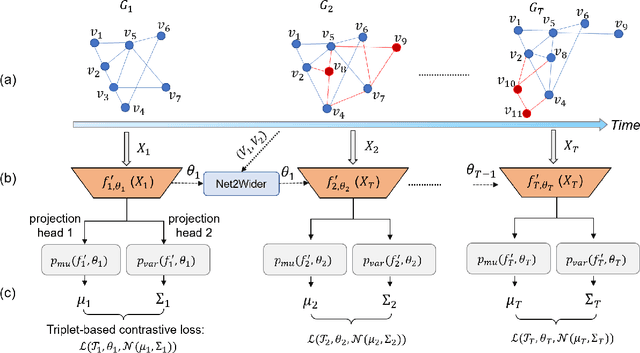
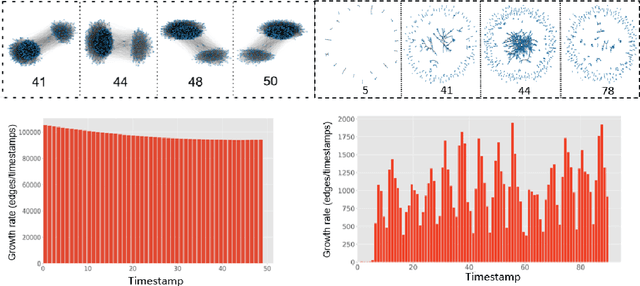
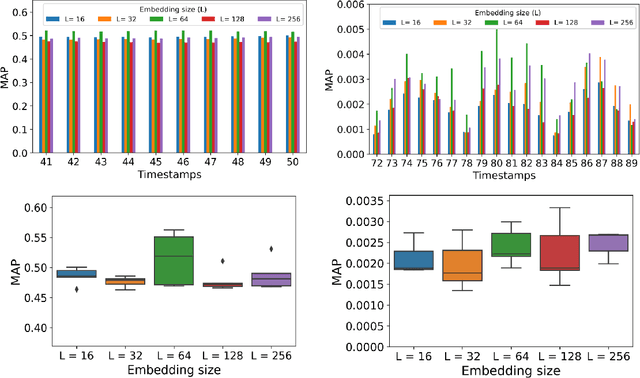
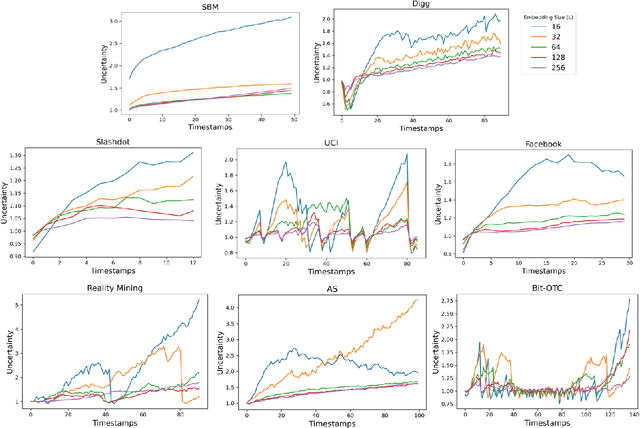
Dynamic graph embedding has gained great attention recently due to its capability of learning low dimensional graph representations for complex temporal graphs with high accuracy. However, recent advances mostly focus on learning node embeddings as deterministic "vectors" for static graphs yet disregarding the key graph temporal dynamics and the evolving uncertainties associated with node embedding in the latent space. In this work, we propose an efficient stochastic dynamic graph embedding method (DynG2G) that applies an inductive feed-forward encoder trained with node triplet-based contrastive loss. Every node per timestamp is encoded as a time-dependent probabilistic multivariate Gaussian distribution in the latent space, hence we can quantify the node embedding uncertainty on-the-fly. We adopted eight different benchmarks that represent diversity in size (from 96 nodes to 87,626 and from 13,398 edges to 4,870,863) and diversity in dynamics. We demonstrate via extensive experiments on these eight dynamic graph benchmarks that DynG2G achieves new state-of-the-art performance in capturing the underlying temporal node embeddings. We also demonstrate that DynG2G can predict the evolving node embedding uncertainty, which plays a crucial role in quantifying the intrinsic dimensionality of the dynamical system over time. We obtain a universal relation of the optimal embedding dimension, $L_o$, versus the effective dimensionality of uncertainty, $D_u$, and we infer that $L_o=D_u$ for all cases. This implies that the uncertainty quantification approach we employ in the DynG2G correctly captures the intrinsic dimensionality of the dynamics of such evolving graphs despite the diverse nature and composition of the graphs at each timestamp. Moreover, this $L_0 - D_u$ correlation provides a clear path to select adaptively the optimum embedding size at each timestamp by setting $L \ge D_u$.
Seq2Seq and Joint Learning Based Unix Command Line Prediction System
Jun 20, 2020
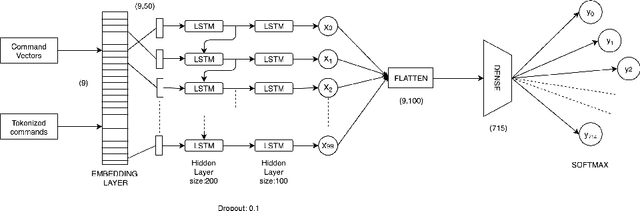
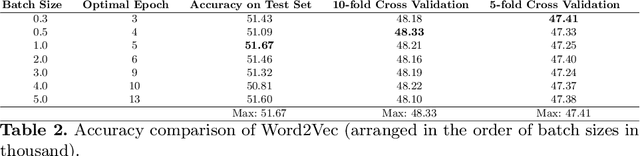

Despite being an open-source operating system pioneered in the early 90s, UNIX based platforms have not been able to garner an overwhelming reception from amateur end users. One of the rationales for under popularity of UNIX based systems is the steep learning curve corresponding to them due to extensive use of command line interface instead of usual interactive graphical user interface. In past years, the majority of insights used to explore the concern are eminently centered around the notion of utilizing chronic log history of the user to make the prediction of successive command. The approaches directed at anatomization of this notion are predominantly in accordance with Probabilistic inference models. The techniques employed in past, however, have not been competent enough to address the predicament as legitimately as anticipated. Instead of deploying usual mechanism of recommendation systems, we have employed a simple yet novel approach of Seq2seq model by leveraging continuous representations of self-curated exhaustive Knowledge Base (KB) to enhance the embedding employed in the model. This work describes an assistive, adaptive and dynamic way of enhancing UNIX command line prediction systems. Experimental methods state that our model has achieved accuracy surpassing mixture of other techniques and adaptive command line interface mechanism as acclaimed in the past.