 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Comprehensive Review on Recent Methods and Challenges of Video Description
Nov 30, 2020
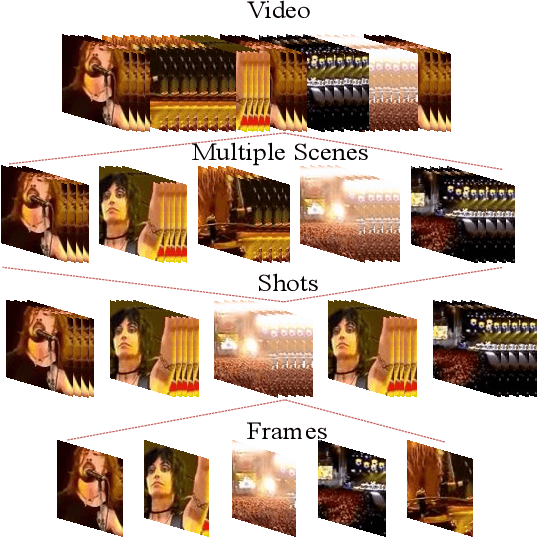
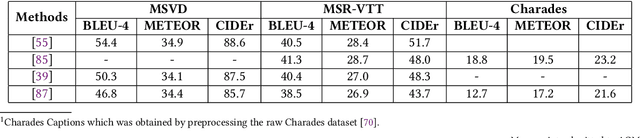
Video description involves the generation of the natural language description of actions, events, and objects in the video. There are various applications of video description by filling the gap between languages and vision for visually impaired people, generating automatic title suggestion based on content, browsing of the video based on the content and video-guided machine translation [86] etc.In the past decade, several works had been done in this field in terms of approaches/methods for video description, evaluation metrics,and datasets. For analyzing the progress in the video description task, a comprehensive survey is needed that covers all the phases of video description approaches with a special focus on recent deep learning approaches. In this work, we report a comprehensive survey on the phases of video description approaches, the dataset for video description, evaluation metrics, open competitions for motivating the research on the video description, open challenges in this field, and future research directions. In this survey, we cover the state-of-the-art approaches proposed for each and every dataset with their pros and cons. For the growth of this research domain,the availability of numerous benchmark dataset is a basic need. Further, we categorize all the dataset into two classes: open domain dataset and domain-specific dataset. From our survey, we observe that the work in this field is in fast-paced development since the task of video description falls in the intersection of computer vision and natural language processing. But still, the work in the video description is far from saturation stage due to various challenges like the redundancy due to similar frames which affect the quality of visual features, the availability of dataset containing more diverse content and availability of an effective evaluation metric.
NITS-Hinglish-SentiMix at SemEval-2020 Task 9: Sentiment Analysis For Code-Mixed Social Media Text
Jul 23, 2020



Sentiment Analysis is the process of deciphering what a sentence emotes and classifying them as either positive, negative, or neutral. In recent times, India has seen a huge influx in the number of active social media users and this has led to a plethora of unstructured text data. Since the Indian population is generally fluent in both Hindi and English, they end up generating code-mixed Hinglish social media text i.e. the expressions of Hindi language, written in the Roman script alongside other English words. The ability to adequately comprehend the notions in these texts is truly necessary. Our team, rns2020 participated in Task 9 at SemEval2020 intending to design a system to carry out the sentiment analysis of code-mixed social media text. This work proposes a system named NITS-Hinglish-SentiMix to viably complete the sentiment analysis of such code-mixed Hinglish text. The proposed framework has recorded an F-Score of 0.617 on the test data.
Towards the Study of Morphological Processing of the Tangkhul Language
Jun 29, 2020
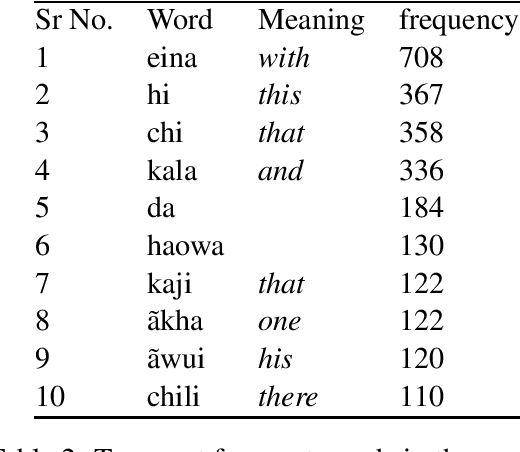


There is no or little work on natural language processing of Tangkhul language. The current work is a humble beginning of morphological processing of this language using an unsupervised approach. We use a small corpus collected from different sources of text books, short stories and articles of other topics. Based on the experiments carried out, the morpheme identification task using morphessor gives reasonable and interesting output despite using a small corpus.
* In proceeding of Regional International Conference on Natural Language Processing (regICON) 2017, 3rd and 4th November 2017, Imphal, India
Seq2Seq and Joint Learning Based Unix Command Line Prediction System
Jun 20, 2020
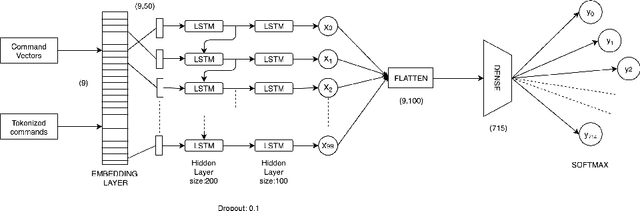
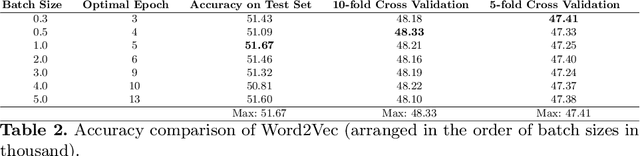

Despite being an open-source operating system pioneered in the early 90s, UNIX based platforms have not been able to garner an overwhelming reception from amateur end users. One of the rationales for under popularity of UNIX based systems is the steep learning curve corresponding to them due to extensive use of command line interface instead of usual interactive graphical user interface. In past years, the majority of insights used to explore the concern are eminently centered around the notion of utilizing chronic log history of the user to make the prediction of successive command. The approaches directed at anatomization of this notion are predominantly in accordance with Probabilistic inference models. The techniques employed in past, however, have not been competent enough to address the predicament as legitimately as anticipated. Instead of deploying usual mechanism of recommendation systems, we have employed a simple yet novel approach of Seq2seq model by leveraging continuous representations of self-curated exhaustive Knowledge Base (KB) to enhance the embedding employed in the model. This work describes an assistive, adaptive and dynamic way of enhancing UNIX command line prediction systems. Experimental methods state that our model has achieved accuracy surpassing mixture of other techniques and adaptive command line interface mechanism as acclaimed in the past.
NITS-VC System for VATEX Video Captioning Challenge 2020
Jun 07, 2020


Video captioning is process of summarising the content, event and action of the video into a short textual form which can be helpful in many research areas such as video guided machine translation, video sentiment analysis and providing aid to needy individual. In this paper, a system description of the framework used for VATEX-2020 video captioning challenge is presented. We employ an encoder-decoder based approach in which the visual features of the video are encoded using 3D convolutional neural network (C3D) and in the decoding phase two Long Short Term Memory (LSTM) recurrent networks are used in which visual features and input captions are fused separately and final output is generated by performing element-wise product between the output of both LSTMs. Our model is able to achieve BLEU scores of 0.20 and 0.22 on public and private test data sets respectively.