Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards the Study of Morphological Processing of the Tangkhul Language
Jun 29, 2020
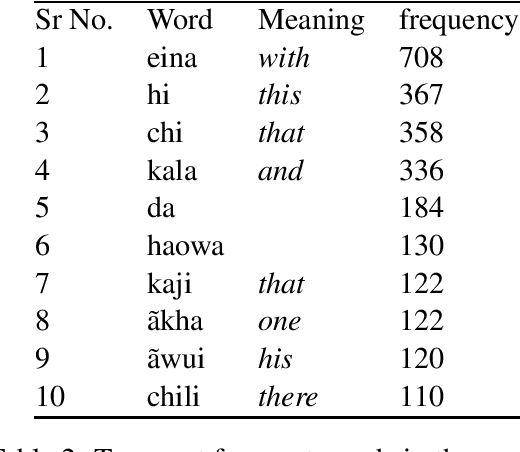


There is no or little work on natural language processing of Tangkhul language. The current work is a humble beginning of morphological processing of this language using an unsupervised approach. We use a small corpus collected from different sources of text books, short stories and articles of other topics. Based on the experiments carried out, the morpheme identification task using morphessor gives reasonable and interesting output despite using a small corpus.
* In proceeding of Regional International Conference on Natural
Language Processing (regICON) 2017, 3rd and 4th November 2017, IIIT Senapati,
Manipur, India
* In proceeding of Regional International Conference on Natural Language Processing (regICON) 2017, 3rd and 4th November 2017, Imphal, India
* In proceeding of Regional International Conference on Natural Language Processing (regICON) 2017, 3rd and 4th November 2017, Imphal, India
Via