 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMixture of Detectors: A Compact View of Machine-Generated Text Detection
Sep 26, 2025Large Language Models (LLMs) are gearing up to surpass human creativity. The veracity of the statement needs careful consideration. In recent developments, critical questions arise regarding the authenticity of human work and the preservation of their creativity and innovative abilities. This paper investigates such issues. This paper addresses machine-generated text detection across several scenarios, including document-level binary and multiclass classification or generator attribution, sentence-level segmentation to differentiate between human-AI collaborative text, and adversarial attacks aimed at reducing the detectability of machine-generated text. We introduce a new work called BMAS English: an English language dataset for binary classification of human and machine text, for multiclass classification, which not only identifies machine-generated text but can also try to determine its generator, and Adversarial attack addressing where it is a common act for the mitigation of detection, and Sentence-level segmentation, for predicting the boundaries between human and machine-generated text. We believe that this paper will address previous work in Machine-Generated Text Detection (MGTD) in a more meaningful way.
Breaking the Silence Detecting and Mitigating Gendered Abuse in Hindi, Tamil, and Indian English Online Spaces
Apr 03, 2024Online gender-based harassment is a widespread issue limiting the free expression and participation of women and marginalized genders in digital spaces. Detecting such abusive content can enable platforms to curb this menace. We participated in the Gendered Abuse Detection in Indic Languages shared task at ICON2023 that provided datasets of annotated Twitter posts in English, Hindi and Tamil for building classifiers to identify gendered abuse. Our team CNLP-NITS-PP developed an ensemble approach combining CNN and BiLSTM networks that can effectively model semantic and sequential patterns in textual data. The CNN captures localized features indicative of abusive language through its convolution filters applied on embedded input text. To determine context-based offensiveness, the BiLSTM analyzes this sequence for dependencies among words and phrases. Multiple variations were trained using FastText and GloVe word embeddings for each language dataset comprising over 7,600 crowdsourced annotations across labels for explicit abuse, targeted minority attacks and general offences. The validation scores showed strong performance across f1-measures, especially for English 0.84. Our experiments reveal how customizing embeddings and model hyperparameters can improve detection capability. The proposed architecture ranked 1st in the competition, proving its ability to handle real-world noisy text with code-switching. This technique has a promising scope as platforms aim to combat cyber harassment facing Indic language internet users. Our Code is at https://github.com/advaithavetagiri/CNLP-NITS-PP
TRAVID: An End-to-End Video Translation Framework
Sep 20, 2023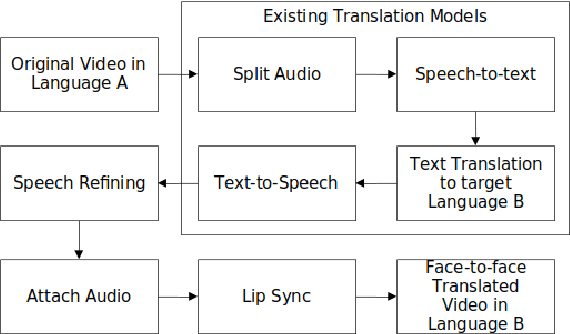

In today's globalized world, effective communication with people from diverse linguistic backgrounds has become increasingly crucial. While traditional methods of language translation, such as written text or voice-only translations, can accomplish the task, they often fail to capture the complete context and nuanced information conveyed through nonverbal cues like facial expressions and lip movements. In this paper, we present an end-to-end video translation system that not only translates spoken language but also synchronizes the translated speech with the lip movements of the speaker. Our system focuses on translating educational lectures in various Indian languages, and it is designed to be effective even in low-resource system settings. By incorporating lip movements that align with the target language and matching them with the speaker's voice using voice cloning techniques, our application offers an enhanced experience for students and users. This additional feature creates a more immersive and realistic learning environment, ultimately making the learning process more effective and engaging.
Deep Neural Network for Musical Instrument Recognition using MFCCs
May 05, 2021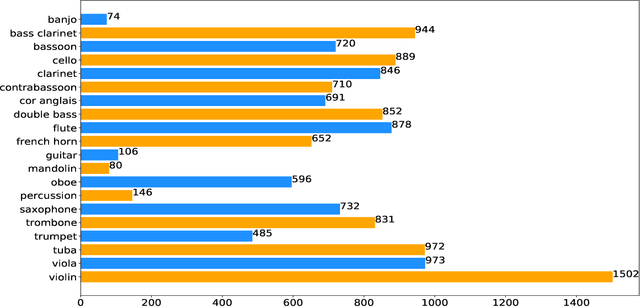
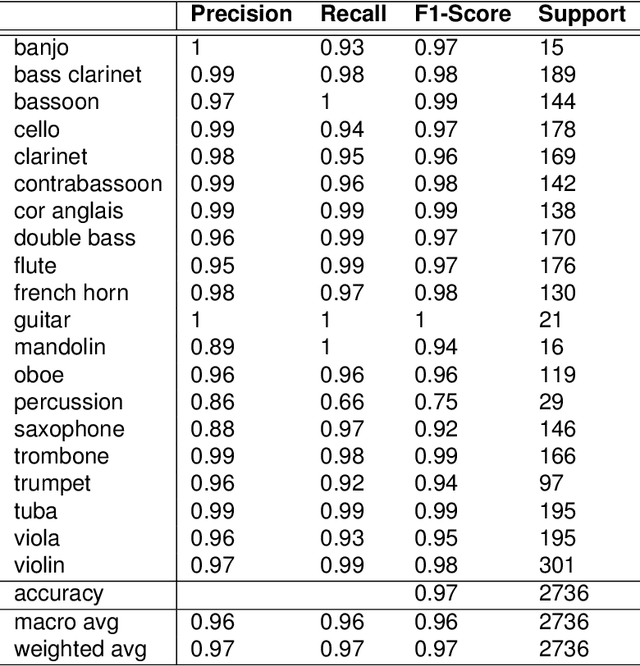
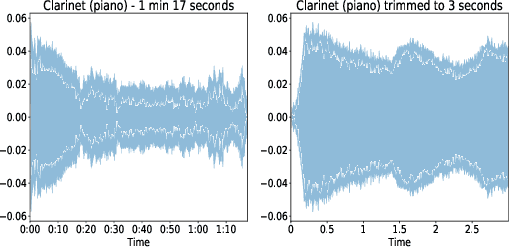
The task of efficient automatic music classification is of vital importance and forms the basis for various advanced applications of AI in the musical domain. Musical instrument recognition is the task of instrument identification by virtue of its audio. This audio, also termed as the sound vibrations are leveraged by the model to match with the instrument classes. In this paper, we use an artificial neural network (ANN) model that was trained to perform classification on twenty different classes of musical instruments. Here we use use only the mel-frequency cepstral coefficients (MFCCs) of the audio data. Our proposed model trains on the full London philharmonic orchestra dataset which contains twenty classes of instruments belonging to the four families viz. woodwinds, brass, percussion, and strings. Based on experimental results our model achieves state-of-the-art accuracy on the same.
* Was suggested to upload on a later date