 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdvCodeMix: Adversarial Attack on Code-Mixed Data
Oct 30, 2021


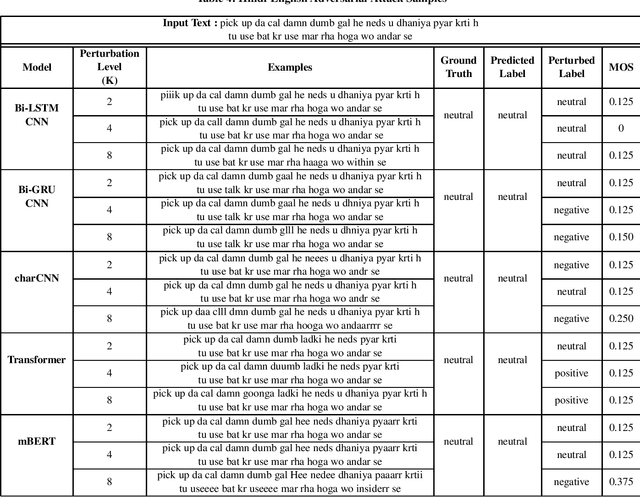
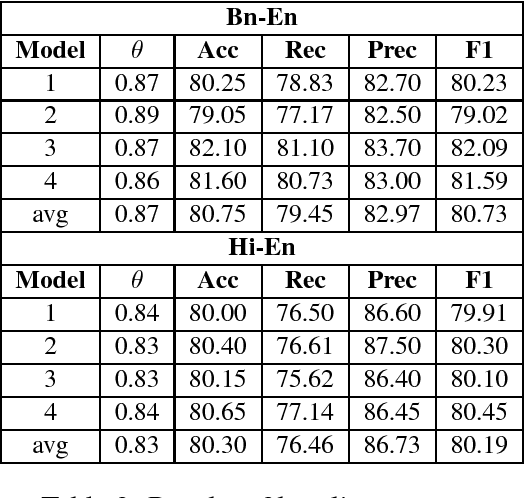
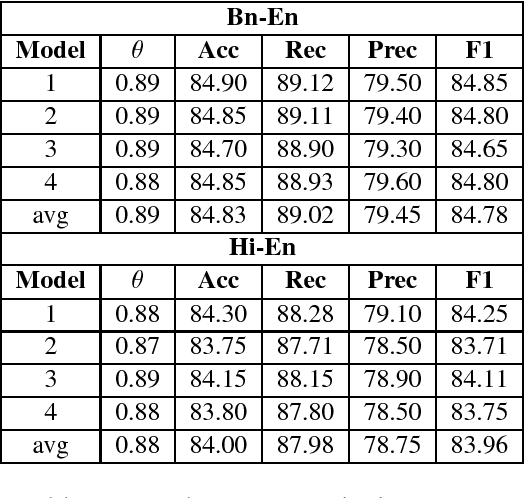
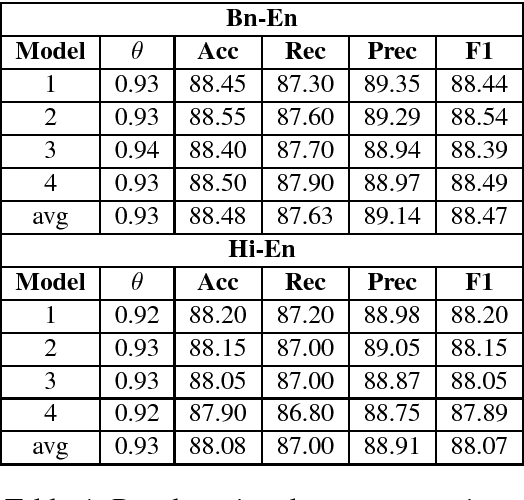
Research on adversarial attacks are becoming widely popular in the recent years. One of the unexplored areas where prior research is lacking is the effect of adversarial attacks on code-mixed data. Therefore, in the present work, we have explained the first generalized framework on text perturbation to attack code-mixed classification models in a black-box setting. We rely on various perturbation techniques that preserve the semantic structures of the sentences and also obscure the attacks from the perception of a human user. The present methodology leverages the importance of a token to decide where to attack by employing various perturbation strategies. We test our strategies on various sentiment classification models trained on Bengali-English and Hindi-English code-mixed datasets, and reduce their F1-scores by nearly 51 % and 53 % respectively, which can be further reduced if a larger number of tokens are perturbed in a given sentence.
Team Neuro at SemEval-2020 Task 8: Multi-Modal Fine Grain Emotion Classification of Memes using Multitask Learning
May 21, 2020
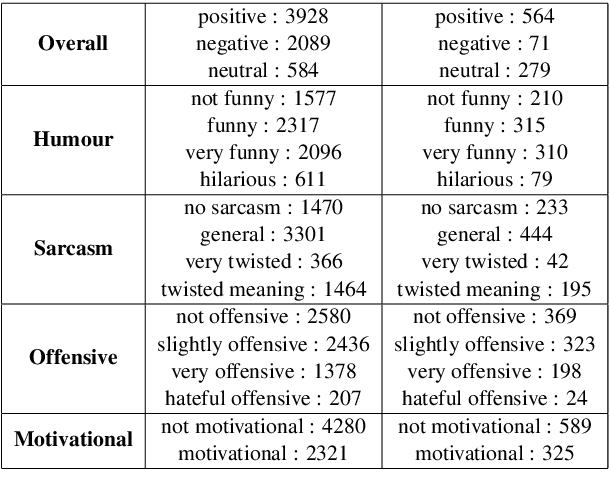
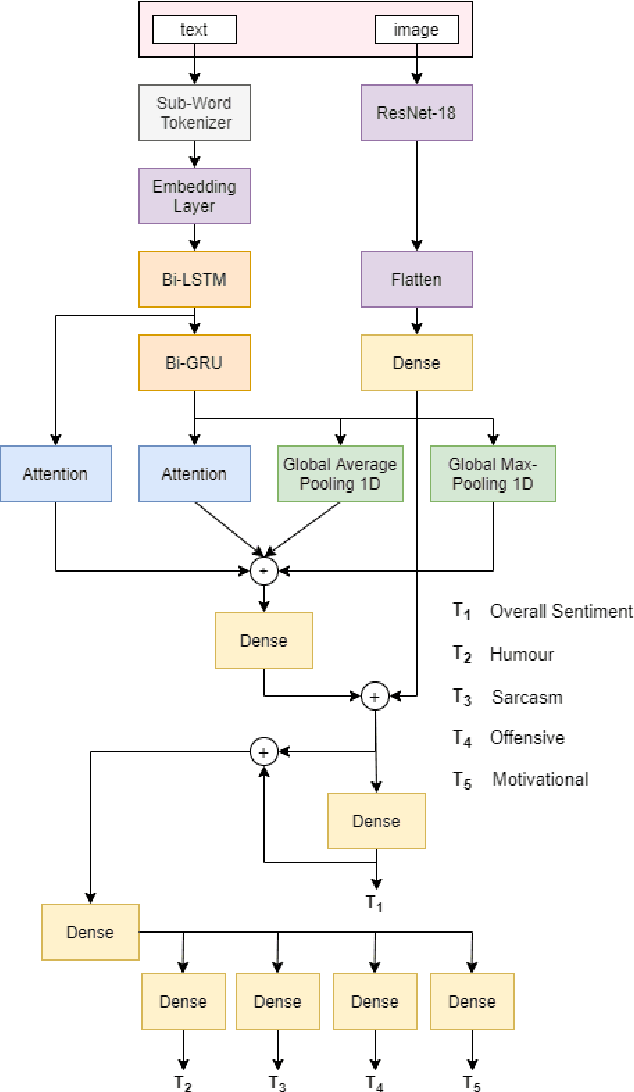
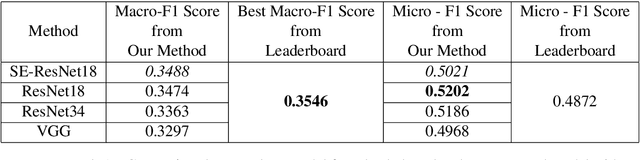
In this article, we describe the system that we used for the memotion analysis challenge, which is Task 8 of SemEval-2020. This challenge had three subtasks where affect based sentiment classification of the memes was required along with intensities. The system we proposed combines the three tasks into a single one by representing it as multi-label hierarchical classification problem.Here,Multi-Task learning or Joint learning Procedure is used to train our model.We have used dual channels to extract text and image based features from separate Deep Neural Network Backbone and aggregate them to create task specific features. These task specific aggregated feature vectors ware then passed on to smaller networks with dense layers, each one assigned for predicting one type of fine grain sentiment label. Our Proposed method show the superiority of this system in few tasks to other best models from the challenge.
Code-Mixed to Monolingual Translation Framework
Nov 22, 2019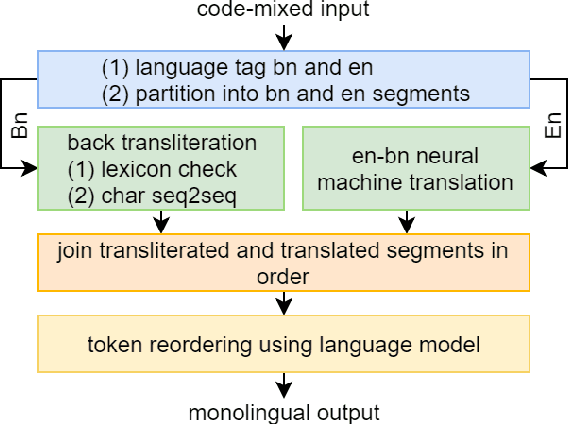
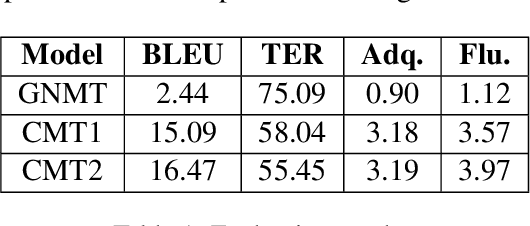
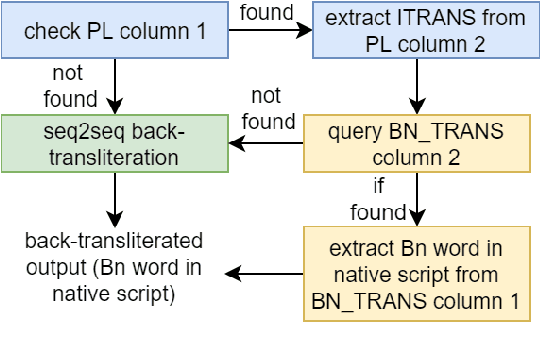
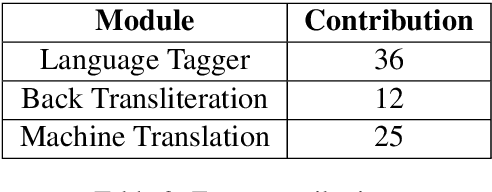
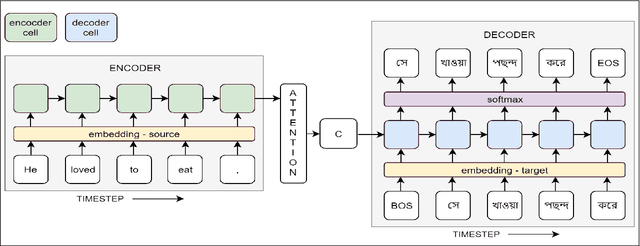
The use of multilingualism in the new generation is widespread in the form of code-mixed data on social media, and therefore a robust translation system is required for catering to the monolingual users, as well as for easier comprehension by language processing models. In this work, we present a translation framework that uses a translation-transliteration strategy for translating code-mixed data into their equivalent monolingual instances. For converting the output to a more fluent form, it is reordered using a target language model. The most important advantage of the proposed framework is that it does not require a code-mixed to monolingual parallel corpus at any point. On testing the framework, it achieved BLEU and TER scores of 16.47 and 55.45, respectively. Since the proposed framework deals with various sub-modules, we dive deeper into the importance of each of them, analyze the errors and finally, discuss some improvement strategies.
SMT vs NMT: A Comparison over Hindi & Bengali Simple Sentences
Dec 12, 2018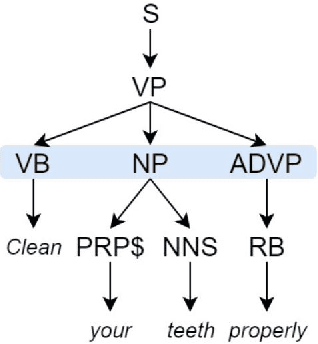
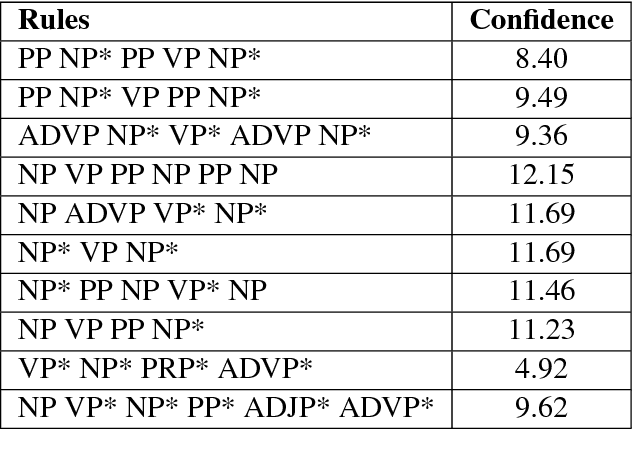
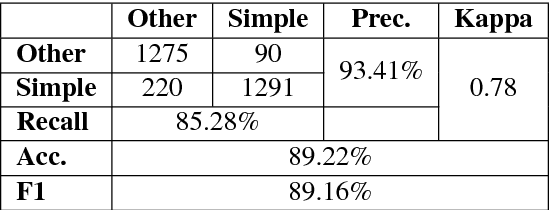
In the present article, we identified the qualitative differences between Statistical Machine Translation (SMT) and Neural Machine Translation (NMT) outputs. We have tried to answer two important questions: 1. Does NMT perform equivalently well with respect to SMT and 2. Does it add extra flavor in improving the quality of MT output by employing simple sentences as training units. In order to obtain insights, we have developed three core models viz., SMT model based on Moses toolkit, followed by character and word level NMT models. All of the systems use English-Hindi and English-Bengali language pairs containing simple sentences as well as sentences of other complexity. In order to preserve the translations semantics with respect to the target words of a sentence, we have employed soft-attention into our word level NMT model. We have further evaluated all the systems with respect to the scenarios where they succeed and fail. Finally, the quality of translation has been validated using BLEU and TER metrics along with manual parameters like fluency, adequacy etc. We observed that NMT outperforms SMT in case of simple sentences whereas SMT outperforms in case of all types of sentence.
Strategies for Language Identification in Code-Mixed Low Resource Languages
Oct 31, 2018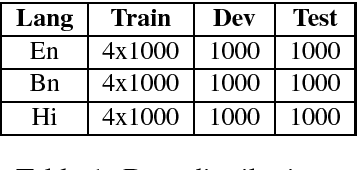
In recent years, substantial work has been done on language tagging of code-mixed data, but most of them use large amounts of data to build their models. In this article, we present three strategies to build a word level language tagger for code-mixed data using very low resources. Each of them secured an accuracy higher than our baseline model, and the best performing system got an accuracy around 91%. Combining all, the ensemble system achieved an accuracy of around 92.6%.
Language Identification in Code-Mixed Data using Multichannel Neural Networks and Context Capture
Aug 21, 2018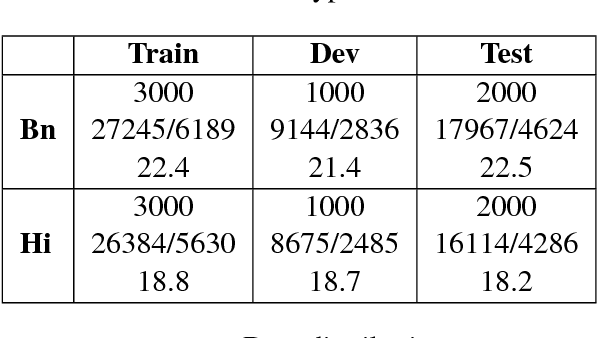

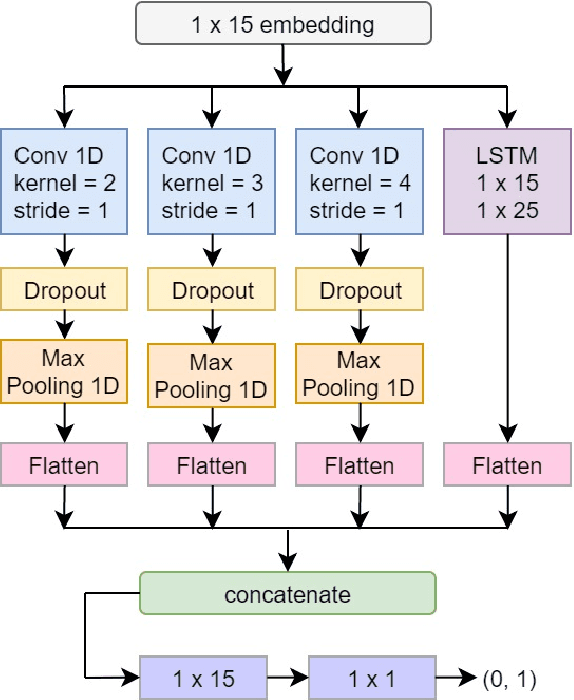
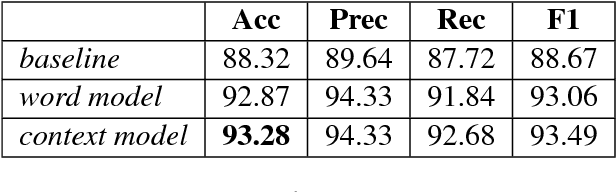
An accurate language identification tool is an absolute necessity for building complex NLP systems to be used on code-mixed data. Lot of work has been recently done on the same, but there's still room for improvement. Inspired from the recent advancements in neural network architectures for computer vision tasks, we have implemented multichannel neural networks combining CNN and LSTM for word level language identification of code-mixed data. Combining this with a Bi-LSTM-CRF context capture module, accuracies of 93.28% and 93.32% is achieved on our two testing sets.
Language Identification of Bengali-English Code-Mixed data using Character & Phonetic based LSTM Models
Jun 27, 2018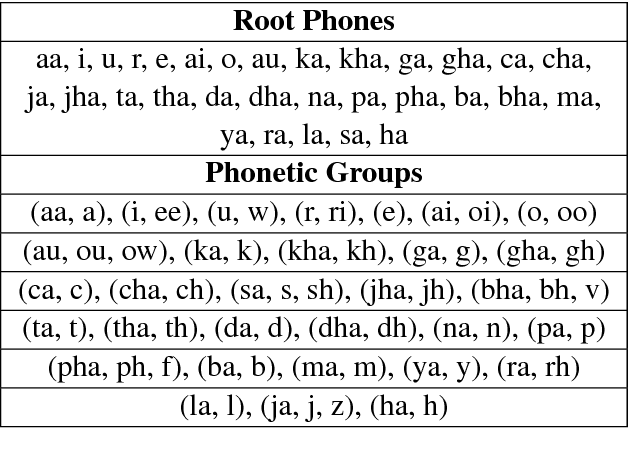
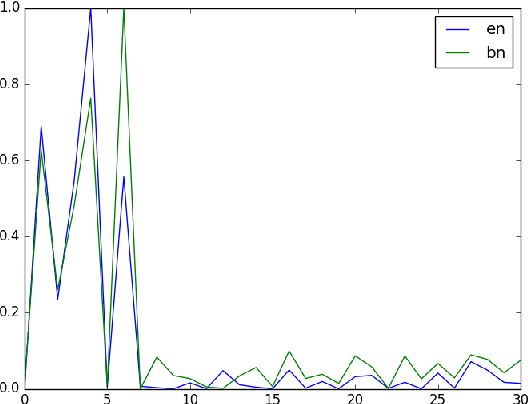
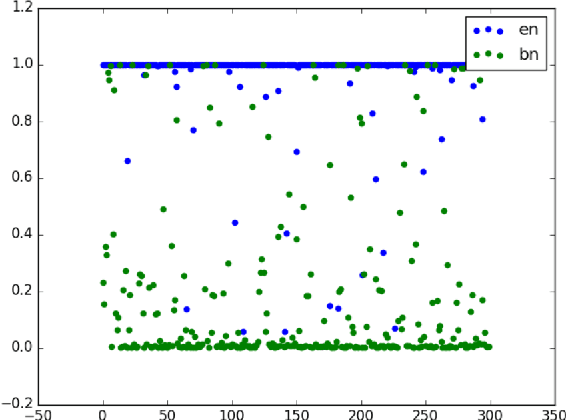
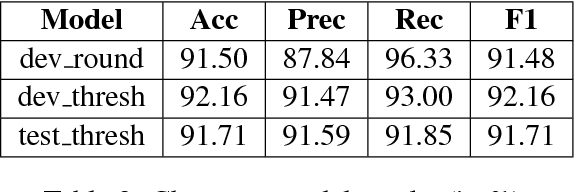
Language identification of social media text still remains a challenging task due to properties like code-mixing and inconsistent phonetic transliterations. In this paper, we present a supervised learning approach for language identification at the word level of low resource Bengali-English code-mixed data taken from social media. We employ two methods of word encoding, namely character based and root phone based to train our deep LSTM models. Utilizing these two models we created two ensemble models using stacking and threshold technique which gave 91.78% and 92.35% accuracies respectively on our testing data.
Normalization of Transliterated Words in Code-Mixed Data Using Seq2Seq Model & Levenshtein Distance
May 22, 2018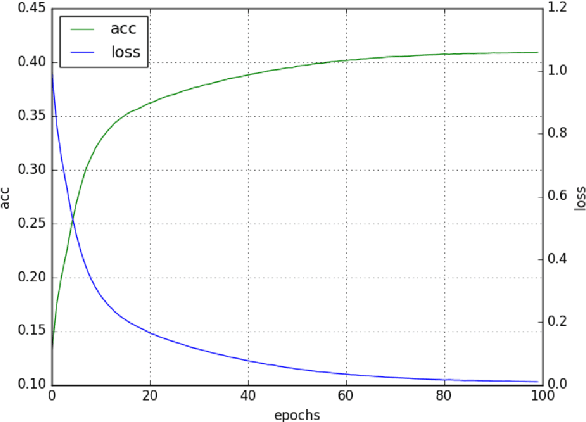
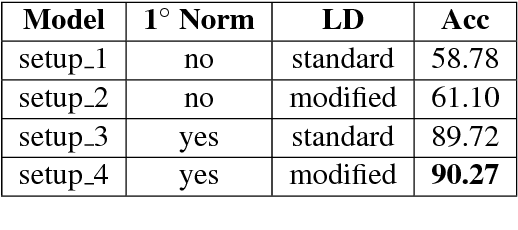
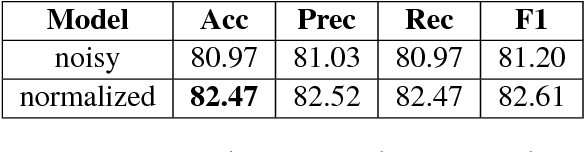
Building tools for code-mixed data is rapidly gaining popularity in the NLP research community as such data is exponentially rising on social media. Working with code-mixed data contains several challenges, especially due to grammatical inconsistencies and spelling variations in addition to all the previous known challenges for social media scenarios. In this article, we present a novel architecture focusing on normalizing phonetic typing variations, which is commonly seen in code-mixed data. One of the main features of our architecture is that in addition to normalizing, it can also be utilized for back-transliteration and word identification in some cases. Our model achieved an accuracy of 90.27% on the test data.
Analyzing Roles of Classifiers and Code-Mixed factors for Sentiment Identification
Mar 15, 2018
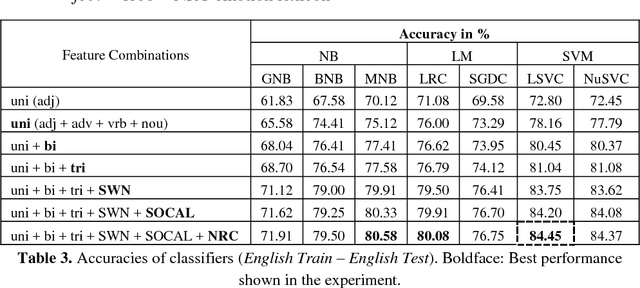
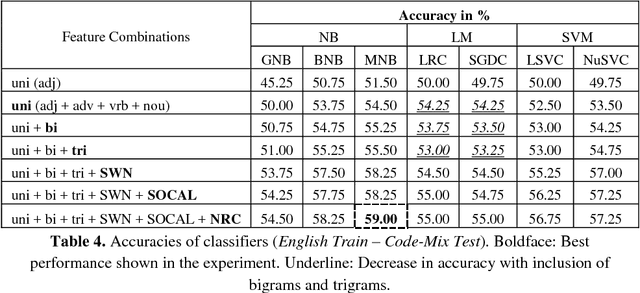
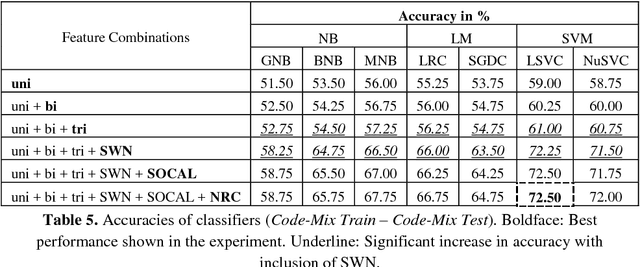
Multilingual speakers often switch between languages to express themselves on social communication platforms. Sometimes, the original script of the language is preserved, while using a common script for all the languages is quite popular as well due to convenience. On such occasions, multiple languages are being mixed with different rules of grammar, using the same script which makes it a challenging task for natural language processing even in case of accurate sentiment identification. In this paper, we report results of various experiments carried out on movie reviews dataset having this code-mixing property of two languages, English and Bengali, both typed in Roman script. We have tested various machine learning algorithms trained only on English features on our code-mixed data and have achieved the maximum accuracy of 59.00% using Naive Bayes (NB) model. We have also tested various models trained on code-mixed data, as well as English features and the highest accuracy of 72.50% was obtained by a Support Vector Machine (SVM) model. Finally, we have analyzed the misclassified snippets and have discussed the challenges needed to be resolved for better accuracy.
Preparing Bengali-English Code-Mixed Corpus for Sentiment Analysis of Indian Languages
Mar 11, 2018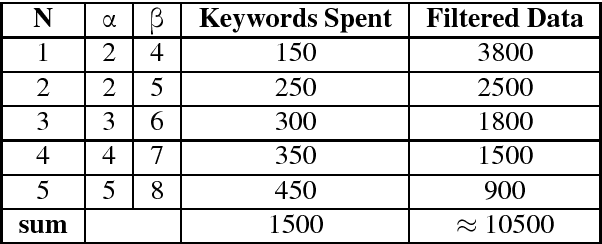
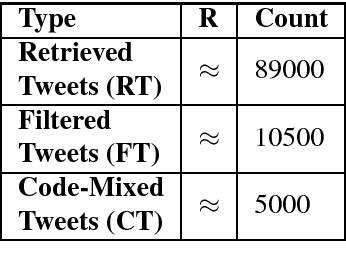
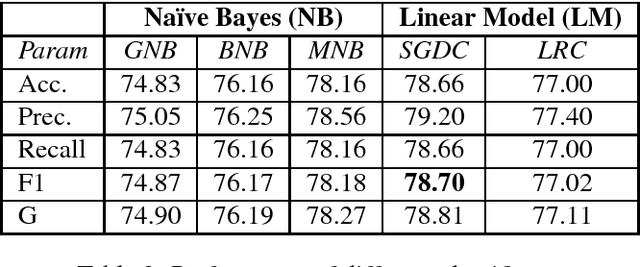
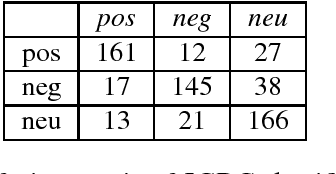
Analysis of informative contents and sentiments of social users has been attempted quite intensively in the recent past. Most of the systems are usable only for monolingual data and fails or gives poor results when used on data with code-mixing property. To gather attention and encourage researchers to work on this crisis, we prepared gold standard Bengali-English code-mixed data with language and polarity tag for sentiment analysis purposes. In this paper, we discuss the systems we prepared to collect and filter raw Twitter data. In order to reduce manual work while annotation, hybrid systems combining rule based and supervised models were developed for both language and sentiment tagging. The final corpus was annotated by a group of annotators following a few guidelines. The gold standard corpus thus obtained has impressive inter-annotator agreement obtained in terms of Kappa values. Various metrics like Code-Mixed Index (CMI), Code-Mixed Factor (CF) along with various aspects (language and emotion) also qualitatively polled the code-mixed and sentiment properties of the corpus.