Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLanguage Identification of Bengali-English Code-Mixed data using Character & Phonetic based LSTM Models
Paper and Code
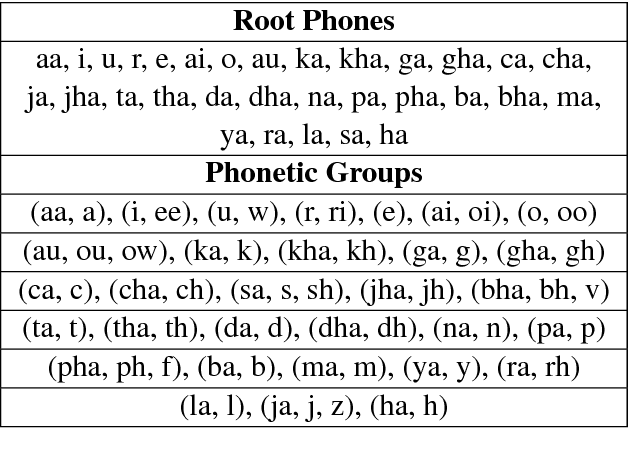
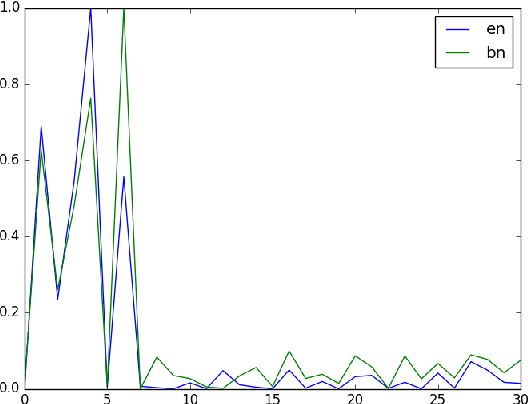
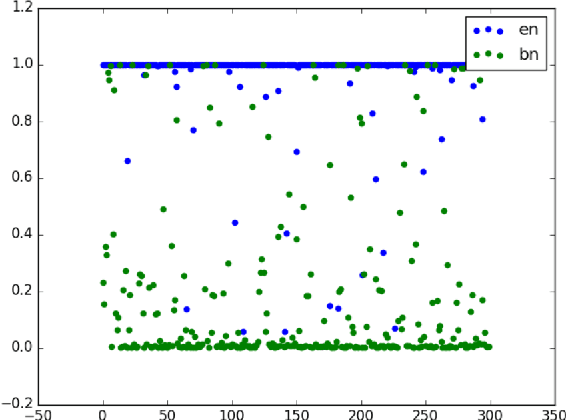
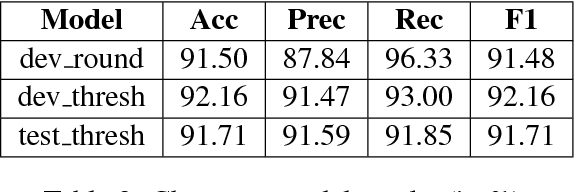
Language identification of social media text still remains a challenging task due to properties like code-mixing and inconsistent phonetic transliterations. In this paper, we present a supervised learning approach for language identification at the word level of low resource Bengali-English code-mixed data taken from social media. We employ two methods of word encoding, namely character based and root phone based to train our deep LSTM models. Utilizing these two models we created two ensemble models using stacking and threshold technique which gave 91.78% and 92.35% accuracies respectively on our testing data.
* 6 pages, 5 figures, 5 tables
View paper on