 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAnalyzing Roles of Classifiers and Code-Mixed factors for Sentiment Identification
Paper and Code
Mar 15, 2018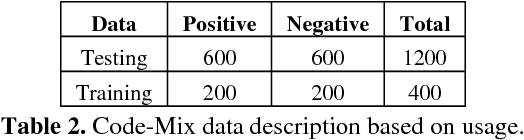
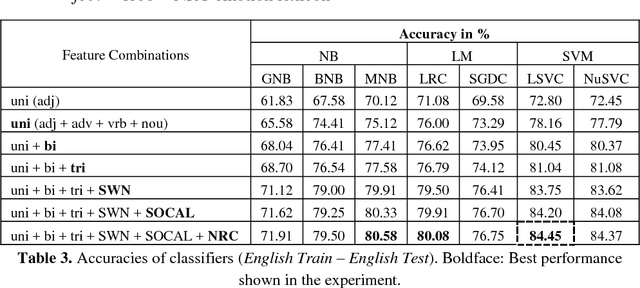
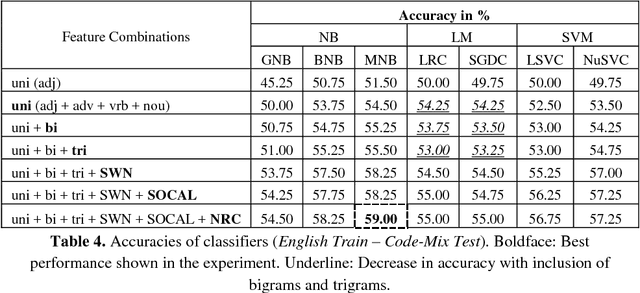
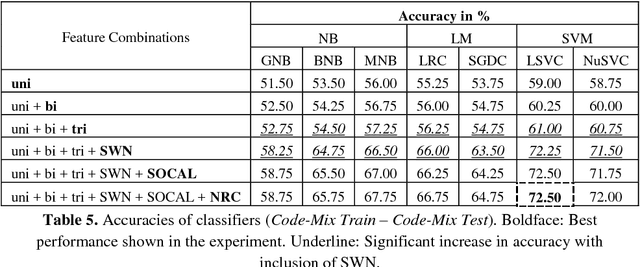
Multilingual speakers often switch between languages to express themselves on social communication platforms. Sometimes, the original script of the language is preserved, while using a common script for all the languages is quite popular as well due to convenience. On such occasions, multiple languages are being mixed with different rules of grammar, using the same script which makes it a challenging task for natural language processing even in case of accurate sentiment identification. In this paper, we report results of various experiments carried out on movie reviews dataset having this code-mixing property of two languages, English and Bengali, both typed in Roman script. We have tested various machine learning algorithms trained only on English features on our code-mixed data and have achieved the maximum accuracy of 59.00% using Naive Bayes (NB) model. We have also tested various models trained on code-mixed data, as well as English features and the highest accuracy of 72.50% was obtained by a Support Vector Machine (SVM) model. Finally, we have analyzed the misclassified snippets and have discussed the challenges needed to be resolved for better accuracy.