 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdvCodeMix: Adversarial Attack on Code-Mixed Data
Oct 30, 2021


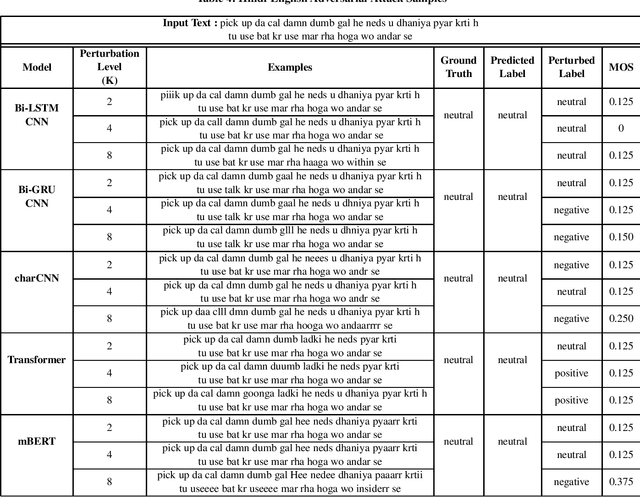
Research on adversarial attacks are becoming widely popular in the recent years. One of the unexplored areas where prior research is lacking is the effect of adversarial attacks on code-mixed data. Therefore, in the present work, we have explained the first generalized framework on text perturbation to attack code-mixed classification models in a black-box setting. We rely on various perturbation techniques that preserve the semantic structures of the sentences and also obscure the attacks from the perception of a human user. The present methodology leverages the importance of a token to decide where to attack by employing various perturbation strategies. We test our strategies on various sentiment classification models trained on Bengali-English and Hindi-English code-mixed datasets, and reduce their F1-scores by nearly 51 % and 53 % respectively, which can be further reduced if a larger number of tokens are perturbed in a given sentence.
Context-aware Retail Product Recommendation with Regularized Gradient Boosting
Sep 17, 2021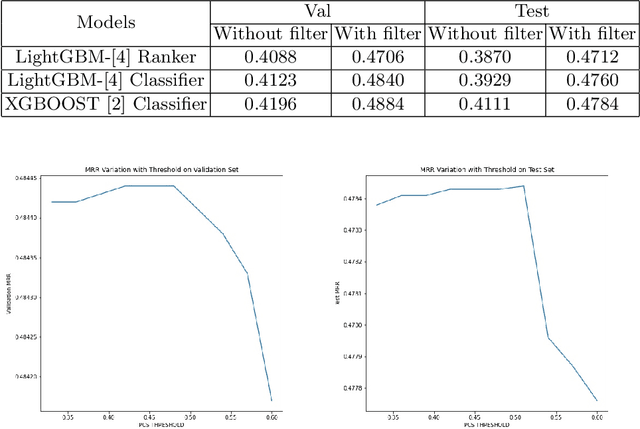
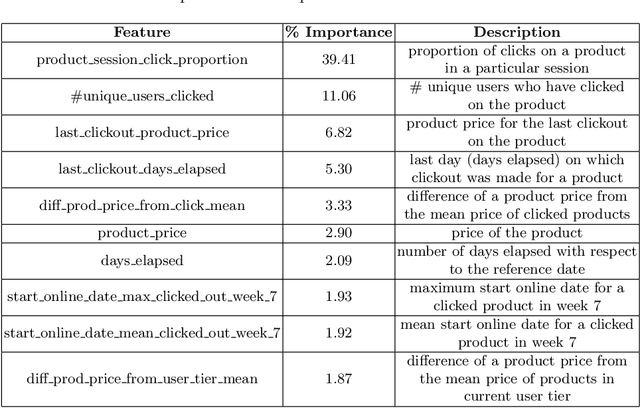
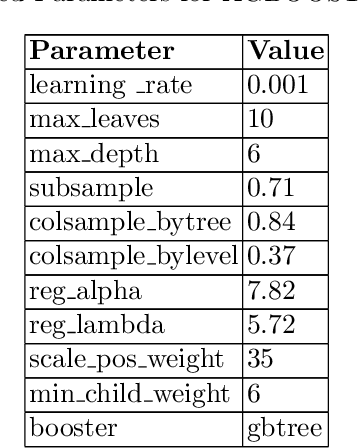
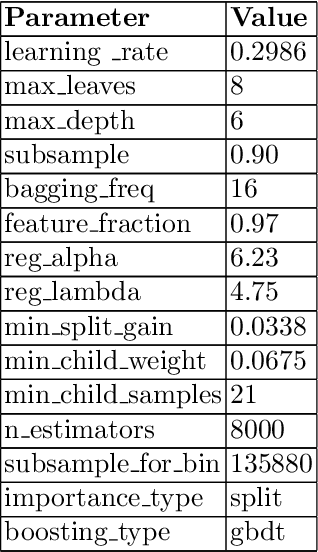
In the FARFETCH Fashion Recommendation challenge, the participants needed to predict the order in which various products would be shown to a user in a recommendation impression. The data was provided in two phases - a validation phase and a test phase. The validation phase had a labelled training set that contained a binary column indicating whether a product has been clicked or not. The dataset comprises over 5,000,000 recommendation events, 450,000 products and 230,000 unique users. It represents real, unbiased, but anonymised, interactions of actual users of the FARFETCH platform. The final evaluation was done according to the performance in the second phase. A total of 167 participants participated in the challenge, and we secured the 6th rank during the final evaluation with an MRR of 0.4658 on the test set. We have designed a unique context-aware system that takes the similarity of a product to the user context into account to rank products more effectively. Post evaluation, we have been able to fine-tune our approach with an MRR of 0.4784 on the test set, which would have placed us at the 3rd position.
A Heuristic-driven Uncertainty based Ensemble Framework for Fake News Detection in Tweets and News Articles
Apr 05, 2021

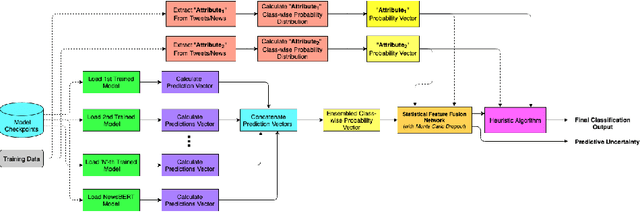
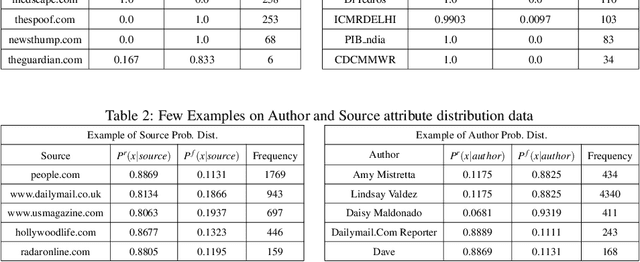
The significance of social media has increased manifold in the past few decades as it helps people from even the most remote corners of the world to stay connected. With the advent of technology, digital media has become more relevant and widely used than ever before and along with this, there has been a resurgence in the circulation of fake news and tweets that demand immediate attention. In this paper, we describe a novel Fake News Detection system that automatically identifies whether a news item is "real" or "fake", as an extension of our work in the CONSTRAINT COVID-19 Fake News Detection in English challenge. We have used an ensemble model consisting of pre-trained models followed by a statistical feature fusion network , along with a novel heuristic algorithm by incorporating various attributes present in news items or tweets like source, username handles, URL domains and authors as statistical feature. Our proposed framework have also quantified reliable predictive uncertainty along with proper class output confidence level for the classification task. We have evaluated our results on the COVID-19 Fake News dataset and FakeNewsNet dataset to show the effectiveness of the proposed algorithm on detecting fake news in short news content as well as in news articles. We obtained a best F1-score of 0.9892 on the COVID-19 dataset, and an F1-score of 0.9073 on the FakeNewsNet dataset.
A Heuristic-driven Ensemble Framework for COVID-19 Fake News Detection
Jan 10, 2021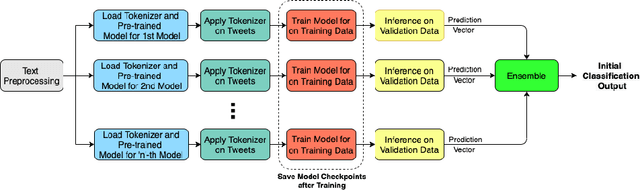
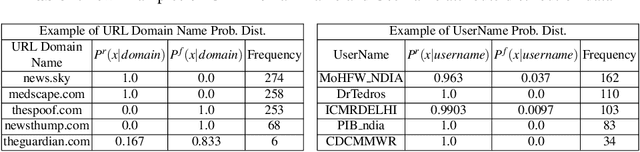
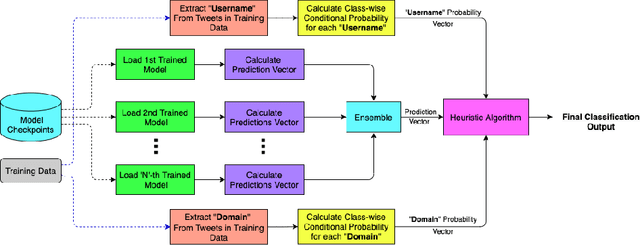
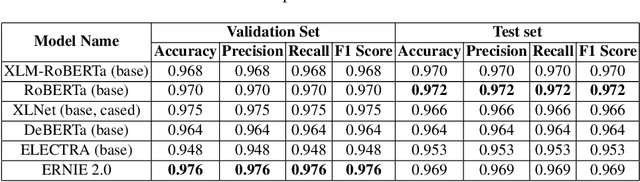
The significance of social media has increased manifold in the past few decades as it helps people from even the most remote corners of the world stay connected. With the COVID-19 pandemic raging, social media has become more relevant and widely used than ever before, and along with this, there has been a resurgence in the circulation of fake news and tweets that demand immediate attention. In this paper, we describe our Fake News Detection system that automatically identifies whether a tweet related to COVID-19 is "real" or "fake", as a part of CONSTRAINT COVID19 Fake News Detection in English challenge. We have used an ensemble model consisting of pre-trained models that has helped us achieve a joint 8th position on the leader board. We have achieved an F1-score of 0.9831 against a top score of 0.9869. Post completion of the competition, we have been able to drastically improve our system by incorporating a novel heuristic algorithm based on username handles and link domains in tweets fetching an F1-score of 0.9883 and achieving state-of-the art results on the given dataset.