 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edgedinov3.seg: Open-Vocabulary Semantic Segmentation with DINOv3
Mar 19, 2026Open-Vocabulary Semantic Segmentation (OVSS) assigns pixel-level labels from an open set of text-defined categories, demanding reliable generalization to unseen classes at inference. Although modern vision-language models (VLMs) support strong open-vocabulary recognition, their representations learned through global contrastive objectives remain suboptimal for dense prediction, prompting many OVSS methods to depend on limited adaptation or refinement of image-text similarity maps. This, in turn, restricts spatial precision and robustness in complex, cluttered scenes. We introduce dinov3.seg, extending dinov3.txt into a dedicated framework for OVSS. Our contributions are four-fold. First, we design a task-specific architecture tailored to this backbone, systematically adapting established design principles from prior open-vocabulary segmentation work. Second, we jointly leverage text embeddings aligned with both the global [CLS] token and local patch-level visual features from ViT-based encoder, effectively combining semantic discrimination with fine-grained spatial locality. Third, unlike prior approaches that rely primarily on post hoc similarity refinement, we perform early refinement of visual representations prior to image-text interaction, followed by late refinement of the resulting image-text correlation features, enabling more accurate and robust dense predictions in cluttered scenes. Finally, we propose a high-resolution local-global inference strategy based on sliding-window aggregation, which preserves spatial detail while maintaining global context. We conduct extensive experiments on five widely adopted OVSS benchmarks to evaluate our approach. The results demonstrate its effectiveness and robustness, consistently outperforming current state-of-the-art methods.
OmniCode: A Benchmark for Evaluating Software Engineering Agents
Feb 02, 2026LLM-powered coding agents are redefining how real-world software is developed. To drive the research towards better coding agents, we require challenging benchmarks that can rigorously evaluate the ability of such agents to perform various software engineering tasks. However, popular coding benchmarks such as HumanEval and SWE-Bench focus on narrowly scoped tasks such as competition programming and patch generation. In reality, software engineers have to handle a broader set of tasks for real-world software development. To address this gap, we propose OmniCode, a novel software engineering benchmark that contains a broader and more diverse set of task categories beyond code or patch generation. Overall, OmniCode contains 1794 tasks spanning three programming languages (Python, Java, and C++) and four key categories: bug fixing, test generation, code review fixing, and style fixing. In contrast to prior software engineering benchmarks, the tasks in OmniCode are (1) manually validated to eliminate ill-defined problems, and (2) synthetically crafted or recently curated to avoid data leakage issues, presenting a new framework for synthetically generating diverse software tasks from limited real-world data. We evaluate OmniCode with popular agent frameworks such as SWE-Agent and show that while they may perform well on bug fixing for Python, they fall short on tasks such as Test Generation and in languages such as C++ and Java. For instance, SWE-Agent achieves a maximum of 20.9% with DeepSeek-V3.1 on Java Test Generation tasks. OmniCode aims to serve as a robust benchmark and spur the development of agents that can perform well across different aspects of software development. Code and data are available at https://github.com/seal-research/OmniCode.
AerOSeg: Harnessing SAM for Open-Vocabulary Segmentation in Remote Sensing Images
Apr 12, 2025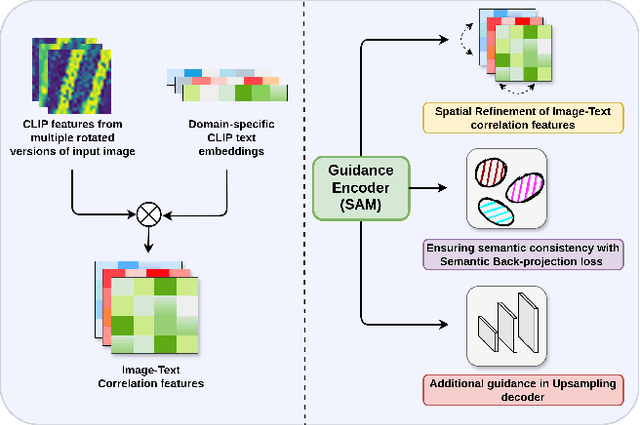

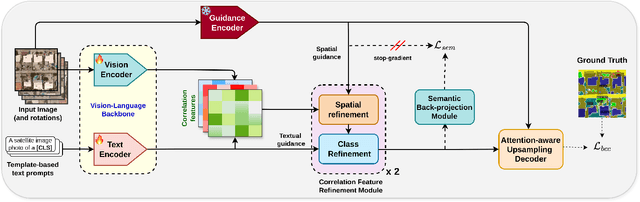

Image segmentation beyond predefined categories is a key challenge in remote sensing, where novel and unseen classes often emerge during inference. Open-vocabulary image Segmentation addresses these generalization issues in traditional supervised segmentation models while reducing reliance on extensive per-pixel annotations, which are both expensive and labor-intensive to obtain. Most Open-Vocabulary Segmentation (OVS) methods are designed for natural images but struggle with remote sensing data due to scale variations, orientation changes, and complex scene compositions. This necessitates the development of OVS approaches specifically tailored for remote sensing. In this context, we propose AerOSeg, a novel OVS approach for remote sensing data. First, we compute robust image-text correlation features using multiple rotated versions of the input image and domain-specific prompts. These features are then refined through spatial and class refinement blocks. Inspired by the success of the Segment Anything Model (SAM) in diverse domains, we leverage SAM features to guide the spatial refinement of correlation features. Additionally, we introduce a semantic back-projection module and loss to ensure the seamless propagation of SAM's semantic information throughout the segmentation pipeline. Finally, we enhance the refined correlation features using a multi-scale attention-aware decoder to produce the final segmentation map. We validate our SAM-guided Open-Vocabulary Remote Sensing Segmentation model on three benchmark remote sensing datasets: iSAID, DLRSD, and OpenEarthMap. Our model outperforms state-of-the-art open-vocabulary segmentation methods, achieving an average improvement of 2.54 h-mIoU.
When Domain Generalization meets Generalized Category Discovery: An Adaptive Task-Arithmetic Driven Approach
Mar 21, 2025Generalized Class Discovery (GCD) clusters base and novel classes in a target domain using supervision from a source domain with only base classes. Current methods often falter with distribution shifts and typically require access to target data during training, which can sometimes be impractical. To address this issue, we introduce the novel paradigm of Domain Generalization in GCD (DG-GCD), where only source data is available for training, while the target domain, with a distinct data distribution, remains unseen until inference. To this end, our solution, DG2CD-Net, aims to construct a domain-independent, discriminative embedding space for GCD. The core innovation is an episodic training strategy that enhances cross-domain generalization by adapting a base model on tasks derived from source and synthetic domains generated by a foundation model. Each episode focuses on a cross-domain GCD task, diversifying task setups over episodes and combining open-set domain adaptation with a novel margin loss and representation learning for optimizing the feature space progressively. To capture the effects of fine-tuning on the base model, we extend task arithmetic by adaptively weighting the local task vectors concerning the fine-tuned models based on their GCD performance on a validation distribution. This episodic update mechanism boosts the adaptability of the base model to unseen targets. Experiments across three datasets confirm that DG2CD-Net outperforms existing GCD methods customized for DG-GCD.
CoCoNUT: Structural Code Understanding does not fall out of a tree
Jan 29, 2025

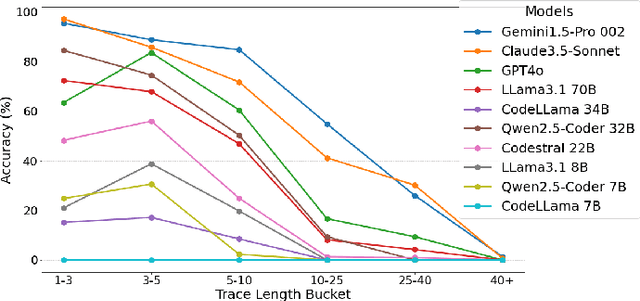

Large Language Models (LLMs) have shown impressive performance across a wide array of tasks involving both structured and unstructured textual data. Recent results on various benchmarks for code generation, repair, or completion suggest that certain models have programming abilities comparable to or even surpass humans. In this work, we demonstrate that high performance on such benchmarks does not correlate to humans' innate ability to understand structural control flow in code. To this end, we extract solutions from the HumanEval benchmark, which the relevant models perform strongly on, and trace their execution path using function calls sampled from the respective test set. Using this dataset, we investigate the ability of seven state-of-the-art LLMs to match the execution trace and find that, despite their ability to generate semantically identical code, they possess limited ability to trace execution paths, especially for longer traces and specific control structures. We find that even the top-performing model, Gemini, can fully and correctly generate only 47% of HumanEval task traces. Additionally, we introduce a subset for three key structures not contained in HumanEval: Recursion, Parallel Processing, and Object-Oriented Programming, including concepts like Inheritance and Polymorphism. Besides OOP, we show that none of the investigated models achieve an accuracy over 5% on the relevant traces. Aggregating these specialized parts with HumanEval tasks, we present CoCoNUT: Code Control Flow for Navigation Understanding and Testing, which measures a model's ability to trace execution of code upon relevant calls, including advanced structural components. We conclude that current LLMs need significant improvement to enhance code reasoning abilities. We hope our dataset helps researchers bridge this gap.
Dolphin: A Programmable Framework for Scalable Neurosymbolic Learning
Oct 04, 2024



Neurosymbolic learning has emerged as a promising paradigm to incorporate symbolic reasoning into deep learning models. However, existing frameworks are limited in scalability with respect to both the training data and the complexity of symbolic programs. We propose Dolphin, a framework to scale neurosymbolic learning at a fundamental level by mapping both forward chaining and backward gradient propagation in symbolic programs to vectorized computations. For this purpose, Dolphin introduces a set of abstractions and primitives built directly on top of a high-performance deep learning framework like PyTorch, effectively enabling symbolic programs to be written as PyTorch modules. It thereby enables neurosymbolic programs to be written in a language like Python that is familiar to developers and compile them to computation graphs that are amenable to end-to-end differentiation on GPUs. We evaluate Dolphin on a suite of 13 benchmarks across 5 neurosymbolic tasks that combine deep learning models for text, image, or video processing with symbolic programs that involve multi-hop reasoning, recursion, and even black-box functions like Python eval(). Dolphin only takes 0.33%-37.17% of the time (and 2.77% on average) to train these models on the largest input per task compared to baselines Scallop, ISED, and IndeCateR+, which time out on most of these inputs. Models written in Dolphin also achieve state-of-the-art accuracies even on the largest benchmarks.
Few Shot Class Incremental Learning using Vision-Language models
May 02, 2024Recent advancements in deep learning have demonstrated remarkable performance comparable to human capabilities across various supervised computer vision tasks. However, the prevalent assumption of having an extensive pool of training data encompassing all classes prior to model training often diverges from real-world scenarios, where limited data availability for novel classes is the norm. The challenge emerges in seamlessly integrating new classes with few samples into the training data, demanding the model to adeptly accommodate these additions without compromising its performance on base classes. To address this exigency, the research community has introduced several solutions under the realm of few-shot class incremental learning (FSCIL). In this study, we introduce an innovative FSCIL framework that utilizes language regularizer and subspace regularizer. During base training, the language regularizer helps incorporate semantic information extracted from a Vision-Language model. The subspace regularizer helps in facilitating the model's acquisition of nuanced connections between image and text semantics inherent to base classes during incremental training. Our proposed framework not only empowers the model to embrace novel classes with limited data, but also ensures the preservation of performance on base classes. To substantiate the efficacy of our approach, we conduct comprehensive experiments on three distinct FSCIL benchmarks, where our framework attains state-of-the-art performance.
Can No-reference features help in Full-reference image quality estimation?
Mar 02, 2022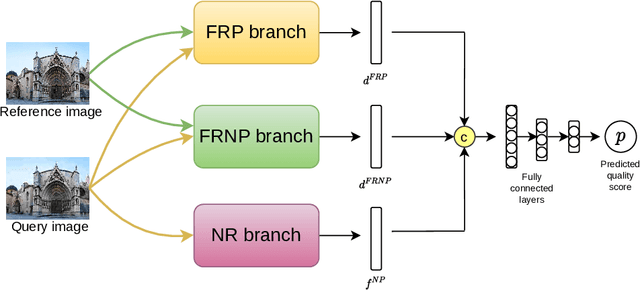
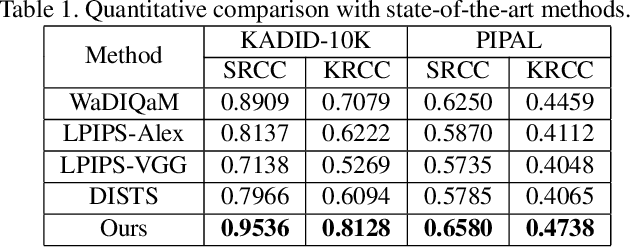

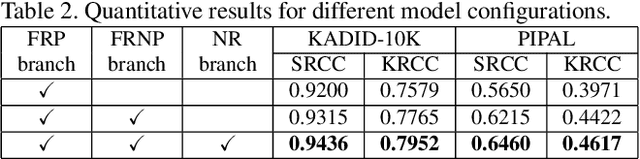
Development of perceptual image quality assessment (IQA) metrics has been of significant interest to computer vision community. The aim of these metrics is to model quality of an image as perceived by humans. Recent works in Full-reference IQA research perform pixelwise comparison between deep features corresponding to query and reference images for quality prediction. However, pixelwise feature comparison may not be meaningful if distortion present in query image is severe. In this context, we explore utilization of no-reference features in Full-reference IQA task. Our model consists of both full-reference and no-reference branches. Full-reference branches use both distorted and reference images, whereas No-reference branch only uses distorted image. Our experiments show that use of no-reference features boosts performance of image quality assessment. Our model achieves higher SRCC and KRCC scores than a number of state-of-the-art algorithms on KADID-10K and PIPAL datasets.
Anomaly Detection in Retinal Images using Multi-Scale Deep Feature Sparse Coding
Jan 27, 2022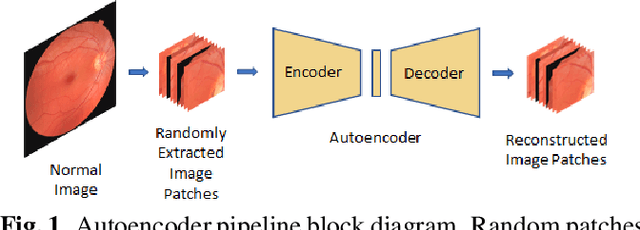
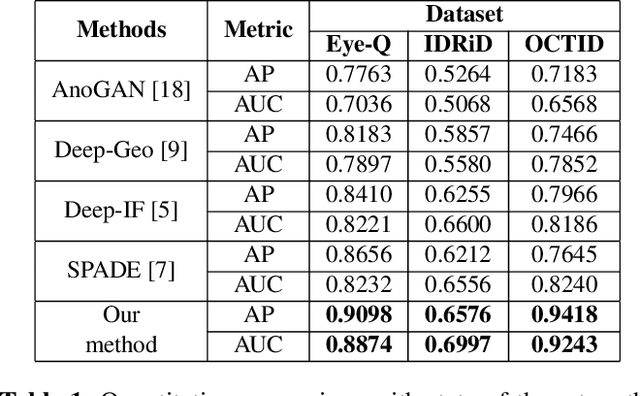
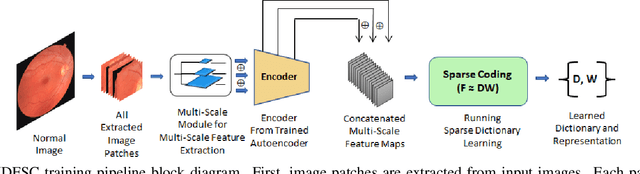
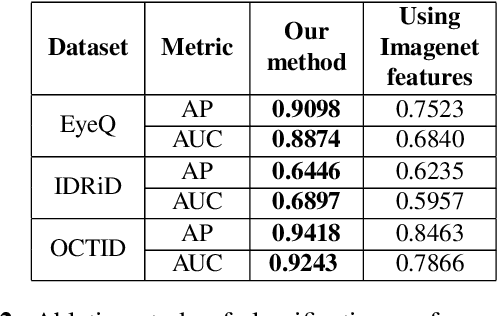
Convolutional Neural Network models have successfully detected retinal illness from optical coherence tomography (OCT) and fundus images. These CNN models frequently rely on vast amounts of labeled data for training, difficult to obtain, especially for rare diseases. Furthermore, a deep learning system trained on a data set with only one or a few diseases cannot detect other diseases, limiting the system's practical use in disease identification. We have introduced an unsupervised approach for detecting anomalies in retinal images to overcome this issue. We have proposed a simple, memory efficient, easy to train method which followed a multi-step training technique that incorporated autoencoder training and Multi-Scale Deep Feature Sparse Coding (MDFSC), an extended version of normal sparse coding, to accommodate diverse types of retinal datasets. We achieve relative AUC score improvement of 7.8\%, 6.7\% and 12.1\% over state-of-the-art SPADE on Eye-Q, IDRiD and OCTID datasets respectively.
Non-linear Motion Estimation for Video Frame Interpolation using Space-time Convolutions
Jan 27, 2022Video frame interpolation aims to synthesize one or multiple frames between two consecutive frames in a video. It has a wide range of applications including slow-motion video generation, frame-rate up-scaling and developing video codecs. Some older works tackled this problem by assuming per-pixel linear motion between video frames. However, objects often follow a non-linear motion pattern in the real domain and some recent methods attempt to model per-pixel motion by non-linear models (e.g., quadratic). A quadratic model can also be inaccurate, especially in the case of motion discontinuities over time (i.e. sudden jerks) and occlusions, where some of the flow information may be invalid or inaccurate. In our paper, we propose to approximate the per-pixel motion using a space-time convolution network that is able to adaptively select the motion model to be used. Specifically, we are able to softly switch between a linear and a quadratic model. Towards this end, we use an end-to-end 3D CNN encoder-decoder architecture over bidirectional optical flows and occlusion maps to estimate the non-linear motion model of each pixel. Further, a motion refinement module is employed to refine the non-linear motion and the interpolated frames are estimated by a simple warping of the neighboring frames with the estimated per-pixel motion. Through a set of comprehensive experiments, we validate the effectiveness of our model and show that our method outperforms state-of-the-art algorithms on four datasets (Vimeo, DAVIS, HD and GoPro).