 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLayer-adaptive Expert Pruning for Pre-Training of Mixture-of-Experts Large Language Models
Jan 20, 2026Although Mixture-of-Experts (MoE) Large Language Models (LLMs) deliver superior accuracy with a reduced number of active parameters, their pre-training represents a significant computationally bottleneck due to underutilized experts and limited training efficiency. This work introduces a Layer-Adaptive Expert Pruning (LAEP) algorithm designed for the pre-training stage of MoE LLMs. In contrast to previous expert pruning approaches that operate primarily in the post-training phase, the proposed algorithm enhances training efficiency by selectively pruning underutilized experts and reorganizing experts across computing devices according to token distribution statistics. Comprehensive experiments demonstrate that LAEP effectively reduces model size and substantially improves pre-training efficiency. In particular, when pre-training the 1010B Base model from scratch, LAEP achieves a 48.3\% improvement in training efficiency alongside a 33.3% parameter reduction, while still delivering excellent performance across multiple domains.
Yuan3.0 Flash: An Open Multimodal Large Language Model for Enterprise Applications
Jan 05, 2026We introduce Yuan3.0 Flash, an open-source Mixture-of-Experts (MoE) MultiModal Large Language Model featuring 3.7B activated parameters and 40B total parameters, specifically designed to enhance performance on enterprise-oriented tasks while maintaining competitive capabilities on general-purpose tasks. To address the overthinking phenomenon commonly observed in Large Reasoning Models (LRMs), we propose Reflection-aware Adaptive Policy Optimization (RAPO), a novel RL training algorithm that effectively regulates overthinking behaviors. In enterprise-oriented tasks such as retrieval-augmented generation (RAG), complex table understanding, and summarization, Yuan3.0 Flash consistently achieves superior performance. Moreover, it also demonstrates strong reasoning capabilities in domains such as mathematics, science, etc., attaining accuracy comparable to frontier model while requiring only approximately 1/4 to 1/2 of the average tokens. Yuan3.0 Flash has been fully open-sourced to facilitate further research and real-world deployment: https://github.com/Yuan-lab-LLM/Yuan3.0.
Dolphin: A Programmable Framework for Scalable Neurosymbolic Learning
Oct 04, 2024



Neurosymbolic learning has emerged as a promising paradigm to incorporate symbolic reasoning into deep learning models. However, existing frameworks are limited in scalability with respect to both the training data and the complexity of symbolic programs. We propose Dolphin, a framework to scale neurosymbolic learning at a fundamental level by mapping both forward chaining and backward gradient propagation in symbolic programs to vectorized computations. For this purpose, Dolphin introduces a set of abstractions and primitives built directly on top of a high-performance deep learning framework like PyTorch, effectively enabling symbolic programs to be written as PyTorch modules. It thereby enables neurosymbolic programs to be written in a language like Python that is familiar to developers and compile them to computation graphs that are amenable to end-to-end differentiation on GPUs. We evaluate Dolphin on a suite of 13 benchmarks across 5 neurosymbolic tasks that combine deep learning models for text, image, or video processing with symbolic programs that involve multi-hop reasoning, recursion, and even black-box functions like Python eval(). Dolphin only takes 0.33%-37.17% of the time (and 2.77% on average) to train these models on the largest input per task compared to baselines Scallop, ISED, and IndeCateR+, which time out on most of these inputs. Models written in Dolphin also achieve state-of-the-art accuracies even on the largest benchmarks.
Artificial Intelligence for Social Good: A Survey
Jan 07, 2020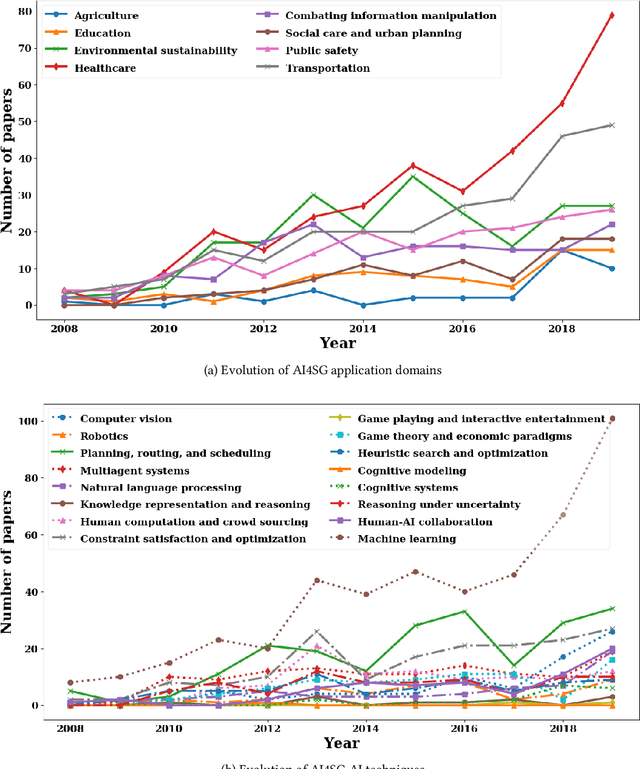

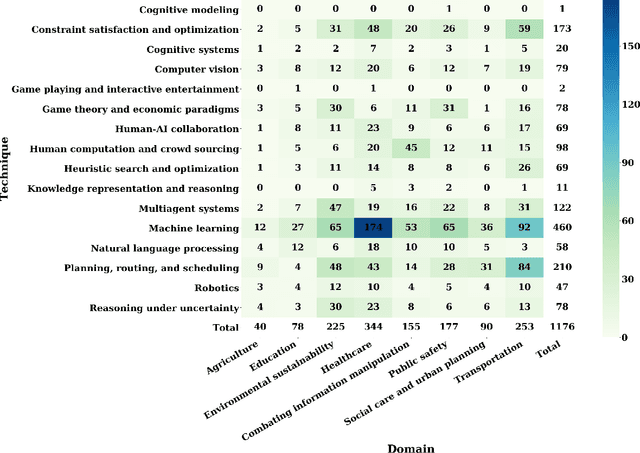
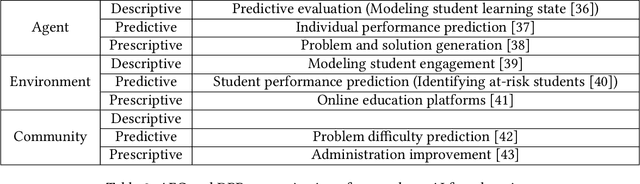
Artificial intelligence for social good (AI4SG) is a research theme that aims to use and advance artificial intelligence to address societal issues and improve the well-being of the world. AI4SG has received lots of attention from the research community in the past decade with several successful applications. Building on the most comprehensive collection of the AI4SG literature to date with over 1000 contributed papers, we provide a detailed account and analysis of the work under the theme in the following ways. (1) We quantitatively analyze the distribution and trend of the AI4SG literature in terms of application domains and AI techniques used. (2) We propose three conceptual methods to systematically group the existing literature and analyze the eight AI4SG application domains in a unified framework. (3) We distill five research topics that represent the common challenges in AI4SG across various application domains. (4) We discuss five issues that, we hope, can shed light on the future development of the AI4SG research.