 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDo We Need Frontier Models to Verify Mathematical Proofs?
Apr 02, 2026Advances in training, post-training, and inference-time methods have enabled frontier reasoning models to win gold medals in math competitions and settle challenging open problems. Gaining trust in the responses of these models requires that natural language proofs be checked for errors. LLM judges are increasingly being adopted to meet the growing demand for evaluating such proofs. While verification is considered easier than generation, what model capability does reliable verification actually require? We systematically evaluate four open-source and two frontier LLMs on datasets of human-graded natural language proofs of competition-level problems. We consider two key metrics: verifier accuracy and self-consistency (the rate of agreement across repeated judgments on the same proof). We observe that smaller open-source models are only up to ~10% behind frontier models in accuracy but they are up to ~25% more inconsistent. Furthermore, we see that verifier accuracy is sensitive to prompt choice across all models. We then demonstrate that the smaller models, in fact, do possess the mathematical capabilities to verify proofs at the level of frontier models, but they struggle to reliably elicit these capabilities with general judging prompts. Through an LLM-guided prompt search, we synthesize an ensemble of specialized prompts that overcome the specific failure modes of smaller models, boosting their performance by up to 9.1% in accuracy and 15.9% in self-consistency. These gains are realized across models and datasets, allowing models like Qwen3.5-35B to perform on par with frontier models such as Gemini 3.1 Pro for proof verification.
On Improving Neurosymbolic Learning by Exploiting the Representation Space
Feb 08, 2026We study the problem of learning neural classifiers in a neurosymbolic setting where the hidden gold labels of input instances must satisfy a logical formula. Learning in this setting proceeds by first computing (a subset of) the possible combinations of labels that satisfy the formula and then computing a loss using those combinations and the classifiers' scores. One challenge is that the space of label combinations can grow exponentially, making learning difficult. We propose a technique that prunes this space by exploiting the intuition that instances with similar latent representations are likely to share the same label. While this intuition has been widely used in weakly supervised learning, its application in our setting is challenging due to label dependencies imposed by logical constraints. We formulate the pruning process as an integer linear program that discards inconsistent label combinations while respecting logical structure. Our approach, CLIPPER, is orthogonal to existing training algorithms and can be seamlessly integrated with them. Across 16 benchmarks over complex neurosymbolic tasks, we demonstrate that CLIPPER boosts the performance of state-of-the-art neurosymbolic engines like Scallop, Dolphin, and ISED by up to 48%, 53%, and 8%, leading to state-of-the-art accuracies.
The Road to Generalizable Neuro-Symbolic Learning Should be Paved with Foundation Models
May 30, 2025Neuro-symbolic learning was proposed to address challenges with training neural networks for complex reasoning tasks with the added benefits of interpretability, reliability, and efficiency. Neuro-symbolic learning methods traditionally train neural models in conjunction with symbolic programs, but they face significant challenges that limit them to simplistic problems. On the other hand, purely-neural foundation models now reach state-of-the-art performance through prompting rather than training, but they are often unreliable and lack interpretability. Supplementing foundation models with symbolic programs, which we call neuro-symbolic prompting, provides a way to use these models for complex reasoning tasks. Doing so raises the question: What role does specialized model training as part of neuro-symbolic learning have in the age of foundation models? To explore this question, we highlight three pitfalls of traditional neuro-symbolic learning with respect to the compute, data, and programs leading to generalization problems. This position paper argues that foundation models enable generalizable neuro-symbolic solutions, offering a path towards achieving the original goals of neuro-symbolic learning without the downsides of training from scratch.
Where's the Bug? Attention Probing for Scalable Fault Localization
Feb 20, 2025Ensuring code correctness remains a challenging problem even as large language models (LLMs) become increasingly capable at code-related tasks. While LLM-based program repair systems can propose bug fixes using only a user's bug report, their effectiveness is fundamentally limited by their ability to perform fault localization (FL), a challenging problem for both humans and LLMs. Existing FL approaches rely on executable test cases, require training on costly and often noisy line-level annotations, or demand resource-intensive LLMs. In this paper, we present Bug Attention Probe (BAP), a method which learns state-of-the-art fault localization without any direct localization labels, outperforming traditional FL baselines and prompting of large-scale LLMs. We evaluate our approach across a variety of code settings, including real-world Java bugs from the standard Defects4J dataset as well as seven other datasets which span a diverse set of bug types and languages. Averaged across all eight datasets, BAP improves by 34.6% top-1 accuracy compared to the strongest baseline and 93.4% over zero-shot prompting GPT-4o. BAP is also significantly more efficient than prompting, outperforming large open-weight models at a small fraction of the computational cost.
Dolphin: A Programmable Framework for Scalable Neurosymbolic Learning
Oct 04, 2024



Neurosymbolic learning has emerged as a promising paradigm to incorporate symbolic reasoning into deep learning models. However, existing frameworks are limited in scalability with respect to both the training data and the complexity of symbolic programs. We propose Dolphin, a framework to scale neurosymbolic learning at a fundamental level by mapping both forward chaining and backward gradient propagation in symbolic programs to vectorized computations. For this purpose, Dolphin introduces a set of abstractions and primitives built directly on top of a high-performance deep learning framework like PyTorch, effectively enabling symbolic programs to be written as PyTorch modules. It thereby enables neurosymbolic programs to be written in a language like Python that is familiar to developers and compile them to computation graphs that are amenable to end-to-end differentiation on GPUs. We evaluate Dolphin on a suite of 13 benchmarks across 5 neurosymbolic tasks that combine deep learning models for text, image, or video processing with symbolic programs that involve multi-hop reasoning, recursion, and even black-box functions like Python eval(). Dolphin only takes 0.33%-37.17% of the time (and 2.77% on average) to train these models on the largest input per task compared to baselines Scallop, ISED, and IndeCateR+, which time out on most of these inputs. Models written in Dolphin also achieve state-of-the-art accuracies even on the largest benchmarks.
Towards Compositionality in Concept Learning
Jun 26, 2024



Concept-based interpretability methods offer a lens into the internals of foundation models by decomposing their embeddings into high-level concepts. These concept representations are most useful when they are compositional, meaning that the individual concepts compose to explain the full sample. We show that existing unsupervised concept extraction methods find concepts which are not compositional. To automatically discover compositional concept representations, we identify two salient properties of such representations, and propose Compositional Concept Extraction (CCE) for finding concepts which obey these properties. We evaluate CCE on five different datasets over image and text data. Our evaluation shows that CCE finds more compositional concept representations than baselines and yields better accuracy on four downstream classification tasks. Code and data are available at https://github.com/adaminsky/compositional_concepts .
MDB: Interactively Querying Datasets and Models
Aug 13, 2023As models are trained and deployed, developers need to be able to systematically debug errors that emerge in the machine learning pipeline. We present MDB, a debugging framework for interactively querying datasets and models. MDB integrates functional programming with relational algebra to build expressive queries over a database of datasets and model predictions. Queries are reusable and easily modified, enabling debuggers to rapidly iterate and refine queries to discover and characterize errors and model behaviors. We evaluate MDB on object detection, bias discovery, image classification, and data imputation tasks across self-driving videos, large language models, and medical records. Our experiments show that MDB enables up to 10x faster and 40\% shorter queries than other baselines. In a user study, we find developers can successfully construct complex queries that describe errors of machine learning models.
Do Machine Learning Models Learn Common Sense?
Mar 02, 2023



Machine learning models can make basic errors that are easily hidden within vast amounts of data. Such errors often run counter to human intuition referred to as "common sense". We thereby seek to characterize common sense for data-driven models, and quantify the extent to which a model has learned common sense. We propose a framework that integrates logic-based methods with statistical inference to derive common sense rules from a model's training data without supervision. We further show how to adapt models at test-time to reduce common sense rule violations and produce more coherent predictions. We evaluate our framework on datasets and models for three different domains. It generates around 250 to 300k rules over these datasets, and uncovers 1.5k to 26k violations of those rules by state-of-the-art models for the respective datasets. Test-time adaptation reduces these violations by up to 38% without impacting overall model accuracy.
Interactive Code Generation via Test-Driven User-Intent Formalization
Aug 11, 2022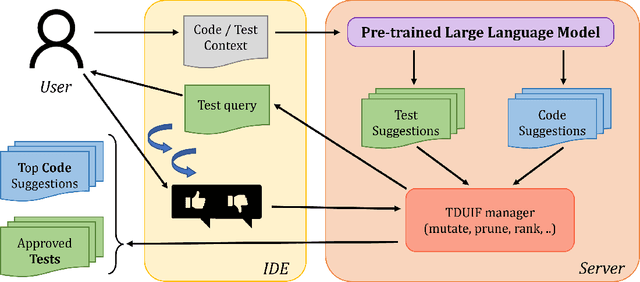



Pre-trained large language models (LLMs) such as OpenAI Codex have shown immense potential in automating significant aspects of coding by producing natural code from informal natural language (NL) intent. However, the code produced does not have any correctness guarantees around satisfying user's intent. In fact, it is hard to define a notion of correctness since natural language can be ambiguous and lacks a formal semantics. In this paper, we take a first step towards addressing the problem above by proposing the workflow of test-driven user-intent formalization (TDUIF), which leverages lightweight user feedback to jointly (a) formalize the user intent as tests (a partial specification), and (b) generates code that meets the formal user intent. To perform a scalable and large-scale automated evaluation of the algorithms without requiring a user in the loop, we describe how to simulate user interaction with high-fidelity using a reference solution. We also describe and implement alternate implementations of several algorithmic components (including mutating and ranking a set of tests) that can be composed for efficient solutions to the TDUIF problem. We have developed a system TICODER that implements several solutions to TDUIF, and compare their relative effectiveness on the MBPP academic code generation benchmark. Our results are promising with using the OpenAI Codex LLM on MBPP: our best algorithm improves the pass@1 code generation accuracy metric from 48.39% to 70.49% with a single user query, and up to 85.48% with up to 5 user queries. Second, we can generate a non-trivial functional unit test consistent with the user intent within an average of 1.69 user queries for 90.40% of the examples for this dataset.