 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRanking LLM-Generated Loop Invariants for Program Verification
Oct 18, 2023Synthesizing inductive loop invariants is fundamental to automating program verification. In this work, we observe that Large Language Models (such as gpt-3.5 or gpt-4) are capable of synthesizing loop invariants for a class of programs in a 0-shot setting, yet require several samples to generate the correct invariants. This can lead to a large number of calls to a program verifier to establish an invariant. To address this issue, we propose a {\it re-ranking} approach for the generated results of LLMs. We have designed a ranker that can distinguish between correct inductive invariants and incorrect attempts based on the problem definition. The ranker is optimized as a contrastive ranker. Experimental results demonstrate that this re-ranking mechanism significantly improves the ranking of correct invariants among the generated candidates, leading to a notable reduction in the number of calls to a verifier.
Interactive Code Generation via Test-Driven User-Intent Formalization
Aug 11, 2022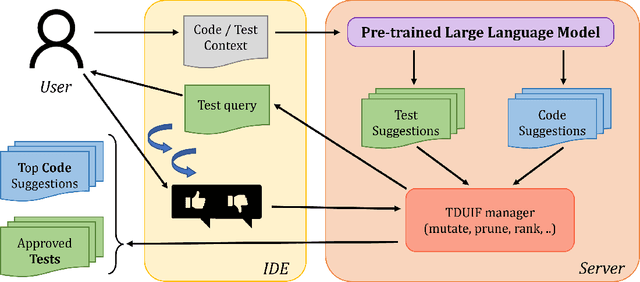



Pre-trained large language models (LLMs) such as OpenAI Codex have shown immense potential in automating significant aspects of coding by producing natural code from informal natural language (NL) intent. However, the code produced does not have any correctness guarantees around satisfying user's intent. In fact, it is hard to define a notion of correctness since natural language can be ambiguous and lacks a formal semantics. In this paper, we take a first step towards addressing the problem above by proposing the workflow of test-driven user-intent formalization (TDUIF), which leverages lightweight user feedback to jointly (a) formalize the user intent as tests (a partial specification), and (b) generates code that meets the formal user intent. To perform a scalable and large-scale automated evaluation of the algorithms without requiring a user in the loop, we describe how to simulate user interaction with high-fidelity using a reference solution. We also describe and implement alternate implementations of several algorithmic components (including mutating and ranking a set of tests) that can be composed for efficient solutions to the TDUIF problem. We have developed a system TICODER that implements several solutions to TDUIF, and compare their relative effectiveness on the MBPP academic code generation benchmark. Our results are promising with using the OpenAI Codex LLM on MBPP: our best algorithm improves the pass@1 code generation accuracy metric from 48.39% to 70.49% with a single user query, and up to 85.48% with up to 5 user queries. Second, we can generate a non-trivial functional unit test consistent with the user intent within an average of 1.69 user queries for 90.40% of the examples for this dataset.
Fault-Aware Neural Code Rankers
Jun 04, 2022

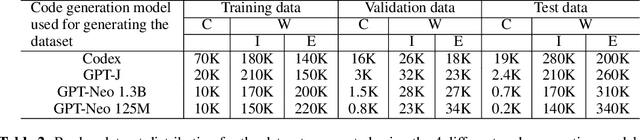

Large language models (LLMs) have demonstrated an impressive ability to generate code for various programming tasks. In many instances, LLMs can generate a correct program for a task when given numerous trials. Consequently, a recent trend is to do large scale sampling of programs using a model and then filtering/ranking the programs based on the program execution on a small number of known unit tests to select one candidate solution. However, these approaches assume that the unit tests are given and assume the ability to safely execute the generated programs (which can do arbitrary dangerous operations such as file manipulations). Both of the above assumptions are impractical in real-world software development. In this paper, we propose fault-aware neural code rankers that can predict the correctness of a sampled program without executing it. The fault-aware rankers are trained to predict different kinds of execution information such as predicting the exact compile/runtime error type (e.g., an IndexError or a TypeError). We show that our fault-aware rankers can significantly increase the pass@1 accuracy of various code generation models (including Codex, GPT-Neo, GPT-J) on APPS, HumanEval and MBPP datasets.
CoCoNet: Co-Optimizing Computation and Communication for Distributed Machine Learning
May 13, 2021
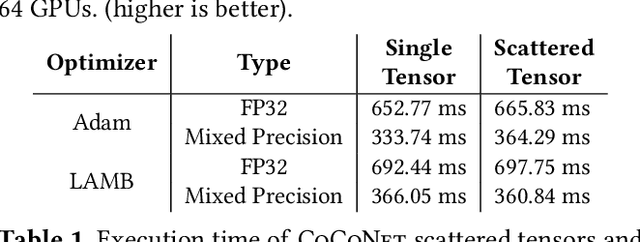

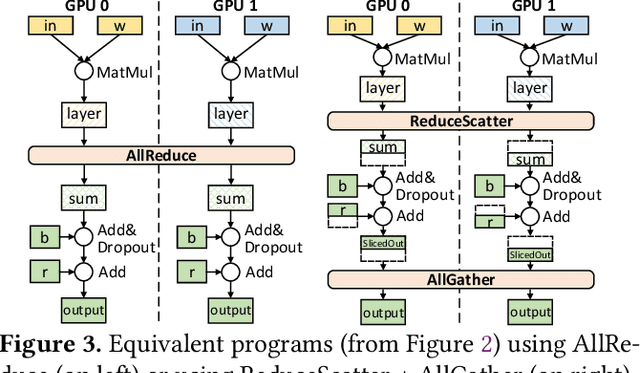
Modern deep learning workloads run on distributed hardware and are difficult to optimize -- data, model, and pipeline parallelism require a developer to thoughtfully restructure their workload around optimized computation and communication kernels in libraries such as cuBLAS and NCCL. The logical separation between computation and communication leaves performance on the table with missed optimization opportunities across abstraction boundaries. To explore these opportunities, this paper presents CoCoNet, which consists of a compute language to express programs with both computation and communication, a scheduling language to apply transformations on such programs, and a compiler to generate high performance kernels. Providing both computation and communication as first class constructs enables new optimizations, such as overlapping or fusion of communication with computation. CoCoNet allowed us to optimize several data, model and pipeline parallel workloads in existing deep learning systems with very few lines of code. We show significant improvements after integrating novel CoCoNet generated kernels.
EVA: An Encrypted Vector Arithmetic Language and Compiler for Efficient Homomorphic Computation
Dec 27, 2019
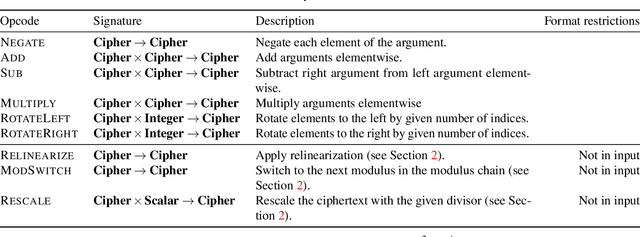
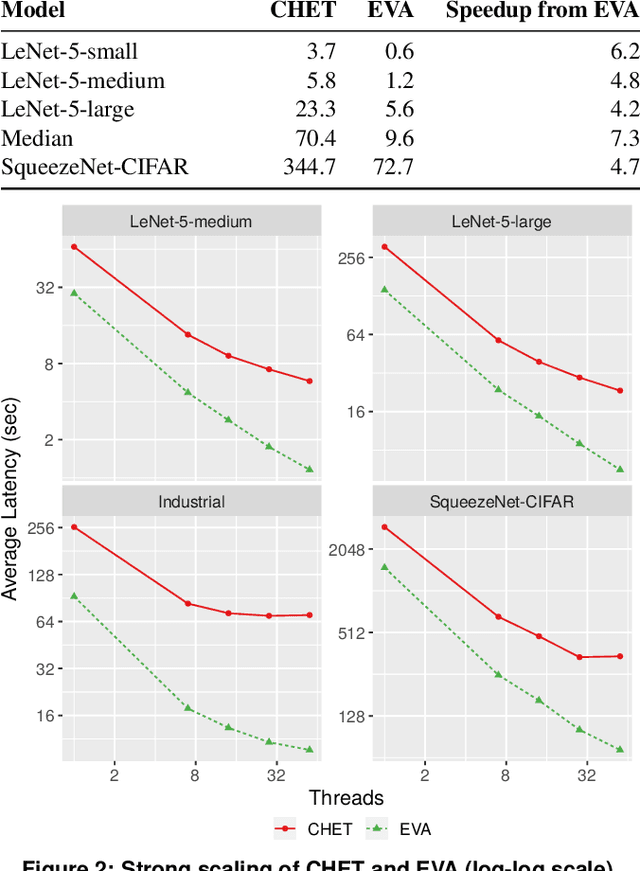
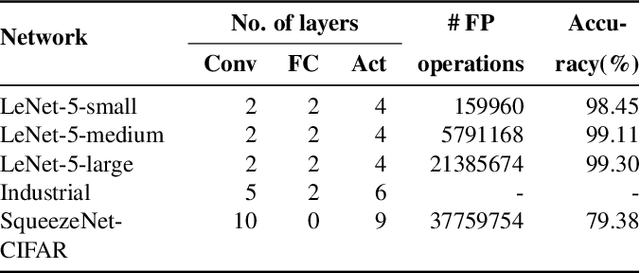
Fully-Homomorphic Encryption (FHE) offers powerful capabilities by enabling secure offloading of both storage and computation, and recent innovations in schemes and implementation have made it all the more attractive. At the same time, FHE is notoriously hard to use with a very constrained programming model, a very unusual performance profile, and many cryptographic constraints. Existing compilers for FHE either target simpler but less efficient FHE schemes or only support specific domains where they can rely on expert provided high-level runtimes to hide complications. This paper presents a new FHE language called Encrypted Vector Arithmetic (EVA), which includes an optimizing compiler that generates correct and secure FHE programs, while hiding all the complexities of the target FHE scheme. Bolstered by our optimizing compiler, programmers can develop efficient general purpose FHE applications directly in EVA. For example, we have developed image processing applications using EVA, with very few lines of code. EVA is designed to also work as an intermediate representation that can be a target for compiling higher-level domain-specific languages. To demonstrate this we have re-targeted CHET, an existing domain-specific compiler for neural network inference, onto EVA. Due to the novel optimizations in EVA, its programs are on average 5.3x faster than those generated by CHET. We believe EVA would enable a wider adoption of FHE by making it easier to develop FHE applications and domain-specific FHE compilers.
CHET: Compiler and Runtime for Homomorphic Evaluation of Tensor Programs
Oct 01, 2018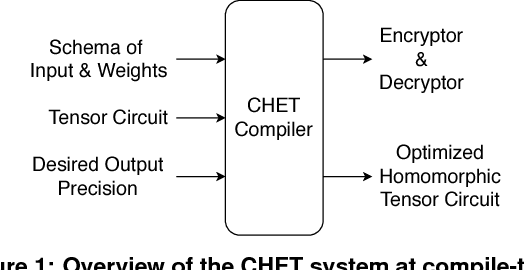
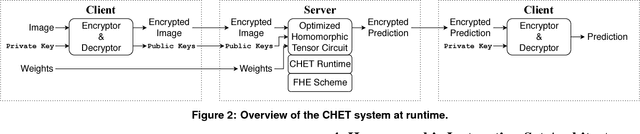
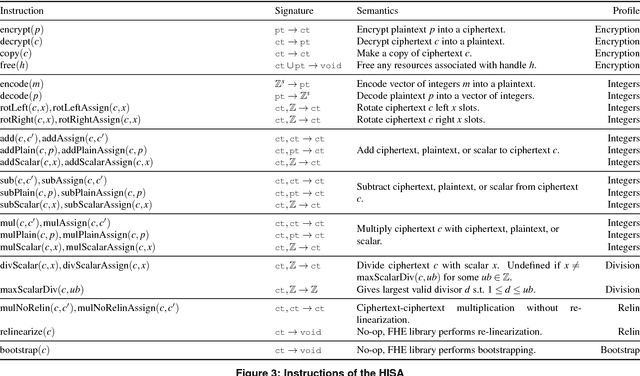
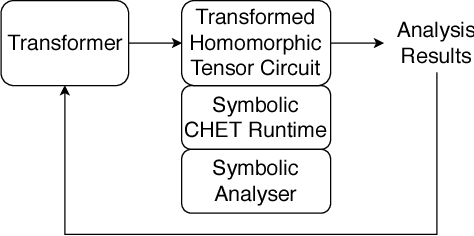
Fully Homomorphic Encryption (FHE) refers to a set of encryption schemes that allow computations to be applied directly on encrypted data without requiring a secret key. This enables novel application scenarios where a client can safely offload storage and computation to a third-party cloud provider without having to trust the software and the hardware vendors with the decryption keys. Recent advances in both FHE schemes and implementations have moved such applications from theoretical possibilities into the realm of practicalities. This paper proposes a compact and well-reasoned interface called the Homomorphic Instruction Set Architecture (HISA) for developing FHE applications. Just as the hardware ISA interface enabled hardware advances to proceed independent of software advances in the compiler and language runtimes, HISA decouples compiler optimizations and runtimes for supporting FHE applications from advancements in the underlying FHE schemes. This paper demonstrates the capabilities of HISA by building an end-to-end software stack for evaluating neural network models on encrypted data. Our stack includes an end-to-end compiler, runtime, and a set of optimizations. Our approach shows generated code, on a set of popular neural network architectures, is faster than hand-optimized implementations.
Parallel Stochastic Gradient Descent with Sound Combiners
May 22, 2017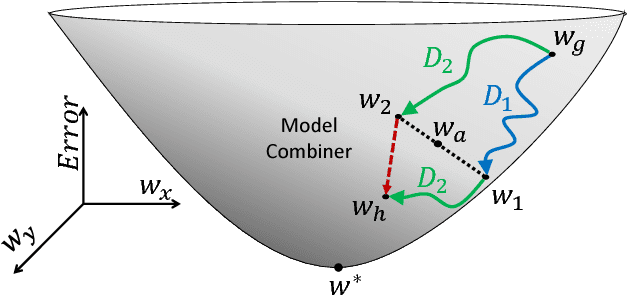

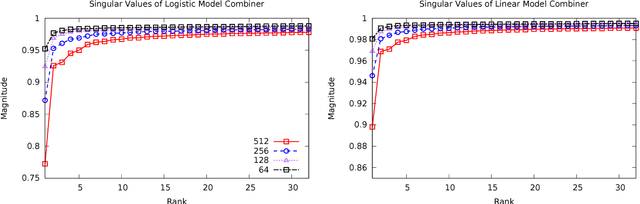
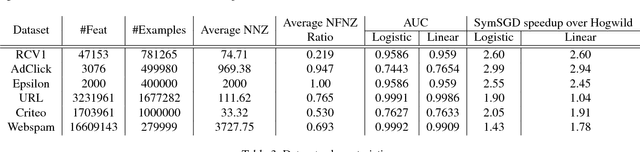
Stochastic gradient descent (SGD) is a well known method for regression and classification tasks. However, it is an inherently sequential algorithm at each step, the processing of the current example depends on the parameters learned from the previous examples. Prior approaches to parallelizing linear learners using SGD, such as HOGWILD! and ALLREDUCE, do not honor these dependencies across threads and thus can potentially suffer poor convergence rates and/or poor scalability. This paper proposes SYMSGD, a parallel SGD algorithm that, to a first-order approximation, retains the sequential semantics of SGD. Each thread learns a local model in addition to a model combiner, which allows local models to be combined to produce the same result as what a sequential SGD would have produced. This paper evaluates SYMSGD's accuracy and performance on 6 datasets on a shared-memory machine shows upto 11x speedup over our heavily optimized sequential baseline on 16 cores and 2.2x, on average, faster than HOGWILD!.