 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Filter-Aware Distance Metrics for Nearest Neighbor Search with Multiple Filters
Nov 06, 2025

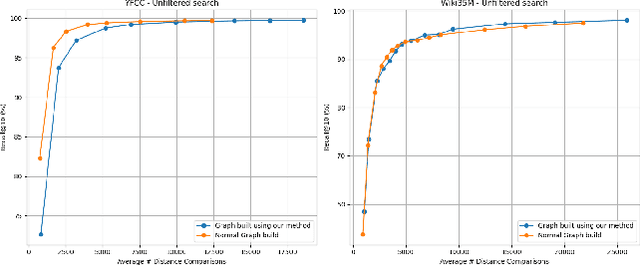

Filtered Approximate Nearest Neighbor (ANN) search retrieves the closest vectors for a query vector from a dataset. It enforces that a specified set of discrete labels $S$ for the query must be included in the labels of each retrieved vector. Existing graph-based methods typically incorporate filter awareness by assigning fixed penalties or prioritizing nodes based on filter satisfaction. However, since these methods use fixed, data in- dependent penalties, they often fail to generalize across datasets with diverse label and vector distributions. In this work, we propose a principled alternative that learns the optimal trade-off between vector distance and filter match directly from the data, rather than relying on fixed penalties. We formulate this as a constrained linear optimization problem, deriving weights that better reflect the underlying filter distribution and more effectively address the filtered ANN search problem. These learned weights guide both the search process and index construction, leading to graph structures that more effectively capture the underlying filter distribution and filter semantics. Our experiments demonstrate that adapting the distance function to the data significantly im- proves accuracy by 5-10% over fixed-penalty methods, providing a more flexible and generalizable framework for the filtered ANN search problem.
Finding Inductive Loop Invariants using Large Language Models
Nov 14, 2023Loop invariants are fundamental to reasoning about programs with loops. They establish properties about a given loop's behavior. When they additionally are inductive, they become useful for the task of formal verification that seeks to establish strong mathematical guarantees about program's runtime behavior. The inductiveness ensures that the invariants can be checked locally without consulting the entire program, thus are indispensable artifacts in a formal proof of correctness. Finding inductive loop invariants is an undecidable problem, and despite a long history of research towards practical solutions, it remains far from a solved problem. This paper investigates the capabilities of the Large Language Models (LLMs) in offering a new solution towards this old, yet important problem. To that end, we first curate a dataset of verification problems on programs with loops. Next, we design a prompt for exploiting LLMs, obtaining inductive loop invariants, that are checked for correctness using sound symbolic tools. Finally, we explore the effectiveness of using an efficient combination of a symbolic tool and an LLM on our dataset and compare it against a purely symbolic baseline. Our results demonstrate that LLMs can help improve the state-of-the-art in automated program verification.
Ranking LLM-Generated Loop Invariants for Program Verification
Oct 18, 2023Synthesizing inductive loop invariants is fundamental to automating program verification. In this work, we observe that Large Language Models (such as gpt-3.5 or gpt-4) are capable of synthesizing loop invariants for a class of programs in a 0-shot setting, yet require several samples to generate the correct invariants. This can lead to a large number of calls to a program verifier to establish an invariant. To address this issue, we propose a {\it re-ranking} approach for the generated results of LLMs. We have designed a ranker that can distinguish between correct inductive invariants and incorrect attempts based on the problem definition. The ranker is optimized as a contrastive ranker. Experimental results demonstrate that this re-ranking mechanism significantly improves the ranking of correct invariants among the generated candidates, leading to a notable reduction in the number of calls to a verifier.
SIRNN: A Math Library for Secure RNN Inference
May 10, 2021
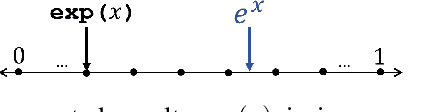


Complex machine learning (ML) inference algorithms like recurrent neural networks (RNNs) use standard functions from math libraries like exponentiation, sigmoid, tanh, and reciprocal of square root. Although prior work on secure 2-party inference provides specialized protocols for convolutional neural networks (CNNs), existing secure implementations of these math operators rely on generic 2-party computation (2PC) protocols that suffer from high communication. We provide new specialized 2PC protocols for math functions that crucially rely on lookup-tables and mixed-bitwidths to address this performance overhead; our protocols for math functions communicate up to 423x less data than prior work. Some of the mixed bitwidth operations used by our math implementations are (zero and signed) extensions, different forms of truncations, multiplication of operands of mixed-bitwidths, and digit decomposition (a generalization of bit decomposition to larger digits). For each of these primitive operations, we construct specialized 2PC protocols that are more communication efficient than generic 2PC, and can be of independent interest. Furthermore, our math implementations are numerically precise, which ensures that the secure implementations preserve model accuracy of cleartext. We build on top of our novel protocols to build SIRNN, a library for end-to-end secure 2-party DNN inference, that provides the first secure implementations of an RNN operating on time series sensor data, an RNN operating on speech data, and a state-of-the-art ML architecture that combines CNNs and RNNs for identifying all heads present in images. Our evaluation shows that SIRNN achieves up to three orders of magnitude of performance improvement when compared to inference of these models using an existing state-of-the-art 2PC framework.
CrypTFlow2: Practical 2-Party Secure Inference
Oct 13, 2020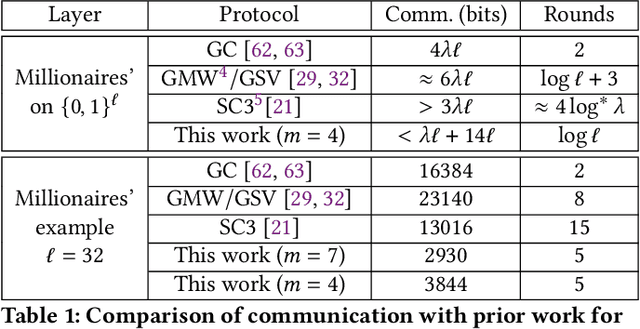
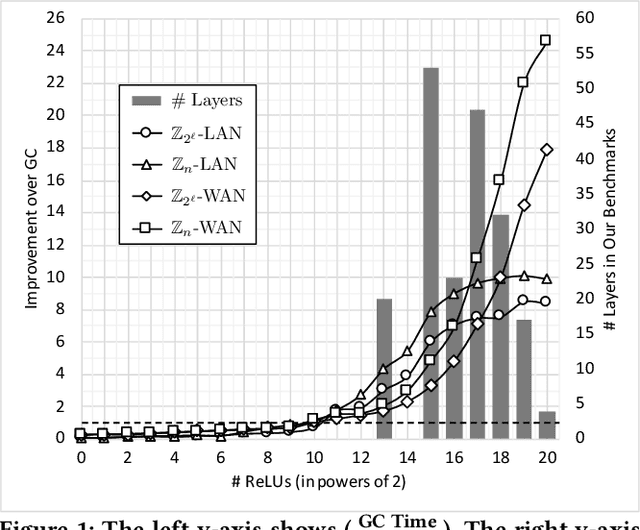
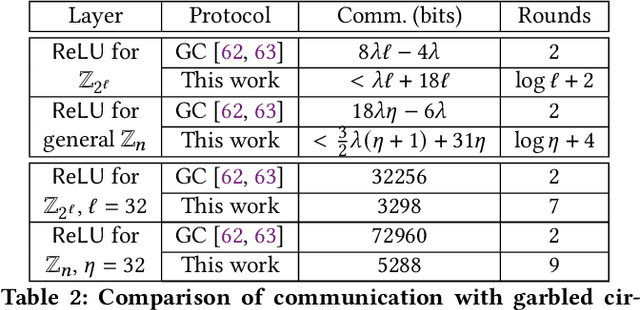
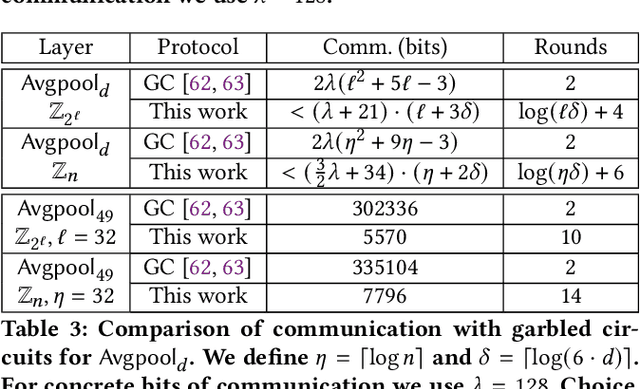
We present CrypTFlow2, a cryptographic framework for secure inference over realistic Deep Neural Networks (DNNs) using secure 2-party computation. CrypTFlow2 protocols are both correct -- i.e., their outputs are bitwise equivalent to the cleartext execution -- and efficient -- they outperform the state-of-the-art protocols in both latency and scale. At the core of CrypTFlow2, we have new 2PC protocols for secure comparison and division, designed carefully to balance round and communication complexity for secure inference tasks. Using CrypTFlow2, we present the first secure inference over ImageNet-scale DNNs like ResNet50 and DenseNet121. These DNNs are at least an order of magnitude larger than those considered in the prior work of 2-party DNN inference. Even on the benchmarks considered by prior work, CrypTFlow2 requires an order of magnitude less communication and 20x-30x less time than the state-of-the-art.
CrypTFlow: Secure TensorFlow Inference
Sep 16, 2019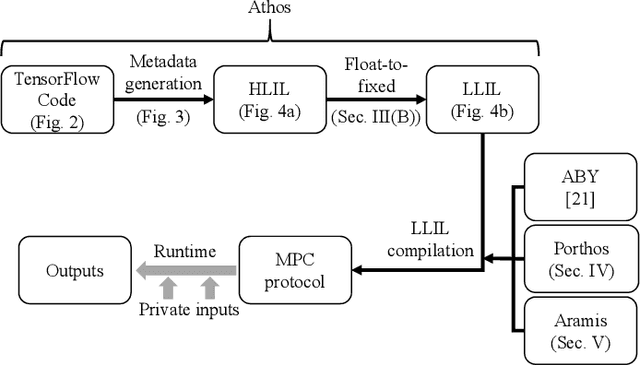

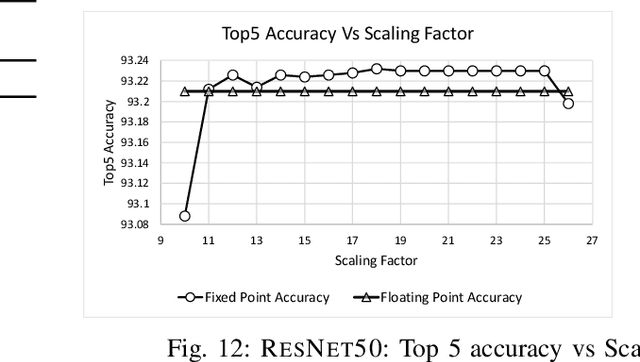
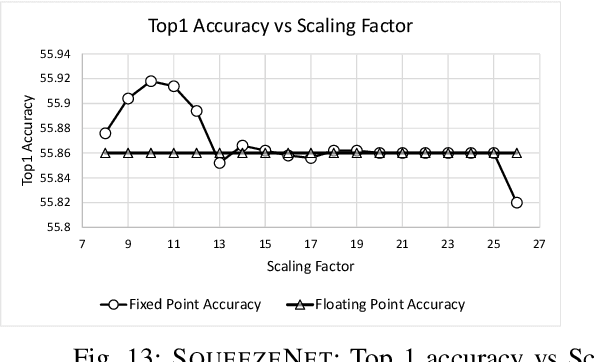
We present CrypTFlow, a first of its kind system that converts TensorFlow inference code into Secure Multi-party Computation (MPC) protocols at the push of a button. To do this, we build three components. Our first component, Athos, is an end-to-end compiler from TensorFlow to a variety of semi-honest MPC protocols. The second component, Porthos, is an improved semi-honest 3-party protocol that provides significant speedups for Tensorflow like applications. Finally, to provide malicious secure MPC protocols, our third component, Aramis, is a novel technique that uses hardware with integrity guarantees to convert any semi-honest MPC protocol into an MPC protocol that provides malicious security. The security of the protocols output by Aramis relies on hardware for integrity and MPC for confidentiality. Moreover, our system, through the use of a new float-to-fixed compiler, matches the inference accuracy over the plaintext floating-point counterparts of these networks. We experimentally demonstrate the power of our system by showing the secure inference of real-world neural networks such as ResNet50, DenseNet121, and SqueezeNet over the ImageNet dataset with running times of about 30 seconds for semi-honest security and under two minutes for malicious security. Prior work in the area of secure inference (SecureML, MiniONN, HyCC, ABY3, CHET, EzPC, Gazelle, and SecureNN) has been limited to semi-honest security of toy networks with 3--4 layers over tiny datasets such as MNIST or CIFAR which have 10 classes. In contrast, our largest network has 200 layers, 65 million parameters and over 1000 ImageNet classes. Even on MNIST/CIFAR, CrypTFlow outperforms prior work.