 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Neural Synthesis for SMT-Assisted Proof-Oriented Programming
May 03, 2024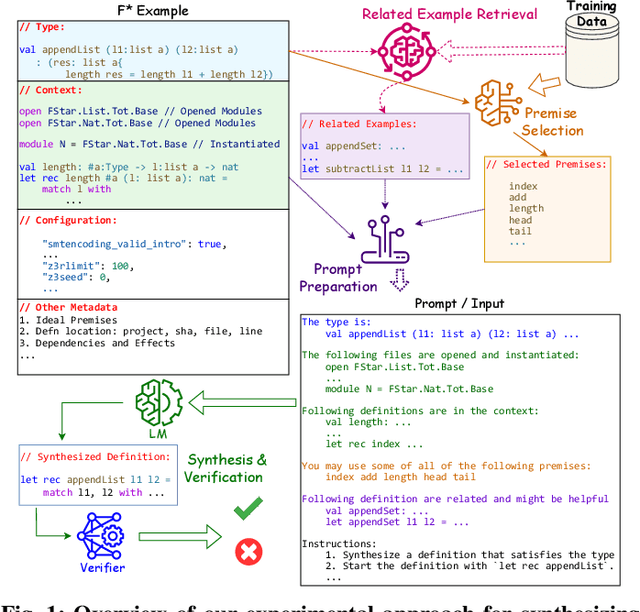
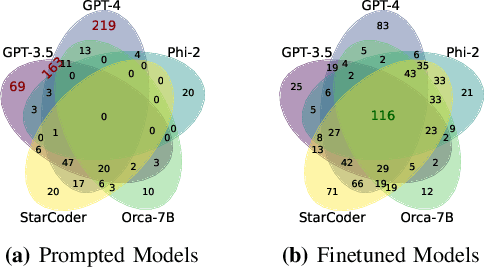
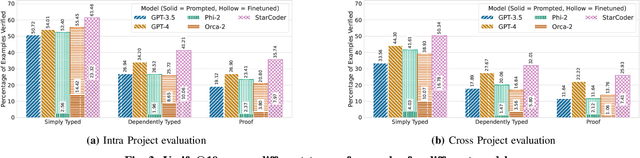
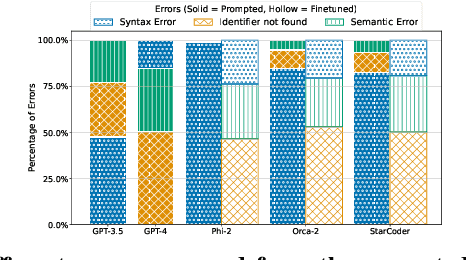
Proof-oriented programs mix computational content with proofs of program correctness. However, the human effort involved in programming and proving is still substantial, despite the use of Satisfiability Modulo Theories (SMT) solvers to automate proofs in languages such as F*. Seeking to spur research on using AI to automate the construction of proof-oriented programs, we curate a dataset of 600K lines of open-source F* programs and proofs, including software used in production systems ranging from Windows and Linux, to Python and Firefox. Our dataset includes around 32K top-level F* definitions, each representing a type-directed program and proof synthesis problem -- producing a definition given a formal specification expressed as an F* type. We provide a program-fragment checker that queries F* to check the correctness of candidate solutions. We believe this is the largest corpus of SMT-assisted program proofs coupled with a reproducible program-fragment checker. Grounded in this dataset, we investigate the use of AI to synthesize programs and their proofs in F*, with promising results. Our main finding in that the performance of fine-tuned smaller language models (such as Phi-2 or StarCoder) compare favorably with large language models (such as GPT-4), at a much lower computational cost. We also identify various type-based retrieval augmentation techniques and find that they boost performance significantly. With detailed error analysis and case studies, we identify potential strengths and weaknesses of models and techniques and suggest directions for future improvements.
Ranking LLM-Generated Loop Invariants for Program Verification
Oct 18, 2023Synthesizing inductive loop invariants is fundamental to automating program verification. In this work, we observe that Large Language Models (such as gpt-3.5 or gpt-4) are capable of synthesizing loop invariants for a class of programs in a 0-shot setting, yet require several samples to generate the correct invariants. This can lead to a large number of calls to a program verifier to establish an invariant. To address this issue, we propose a {\it re-ranking} approach for the generated results of LLMs. We have designed a ranker that can distinguish between correct inductive invariants and incorrect attempts based on the problem definition. The ranker is optimized as a contrastive ranker. Experimental results demonstrate that this re-ranking mechanism significantly improves the ranking of correct invariants among the generated candidates, leading to a notable reduction in the number of calls to a verifier.
Formalizing Natural Language Intent into Program Specifications via Large Language Models
Oct 03, 2023Informal natural language that describes code functionality, such as code comments or function documentation, may contain substantial information about a programs intent. However, there is typically no guarantee that a programs implementation and natural language documentation are aligned. In the case of a conflict, leveraging information in code-adjacent natural language has the potential to enhance fault localization, debugging, and code trustworthiness. In practice, however, this information is often underutilized due to the inherent ambiguity of natural language which makes natural language intent challenging to check programmatically. The "emergent abilities" of Large Language Models (LLMs) have the potential to facilitate the translation of natural language intent to programmatically checkable assertions. However, it is unclear if LLMs can correctly translate informal natural language specifications into formal specifications that match programmer intent. Additionally, it is unclear if such translation could be useful in practice. In this paper, we describe LLM4nl2post, the problem leveraging LLMs for transforming informal natural language to formal method postconditions, expressed as program assertions. We introduce and validate metrics to measure and compare different LLM4nl2post approaches, using the correctness and discriminative power of generated postconditions. We then perform qualitative and quantitative methods to assess the quality of LLM4nl2post postconditions, finding that they are generally correct and able to discriminate incorrect code. Finally, we find that LLM4nl2post via LLMs has the potential to be helpful in practice; specifications generated from natural language were able to catch 70 real-world historical bugs from Defects4J.
Towards Generating Functionally Correct Code Edits from Natural Language Issue Descriptions
Apr 07, 2023



Large language models (LLMs), such as OpenAI's Codex, have demonstrated their potential to generate code from natural language descriptions across a wide range of programming tasks. Several benchmarks have recently emerged to evaluate the ability of LLMs to generate functionally correct code from natural language intent with respect to a set of hidden test cases. This has enabled the research community to identify significant and reproducible advancements in LLM capabilities. However, there is currently a lack of benchmark datasets for assessing the ability of LLMs to generate functionally correct code edits based on natural language descriptions of intended changes. This paper aims to address this gap by motivating the problem NL2Fix of translating natural language descriptions of code changes (namely bug fixes described in Issue reports in repositories) into correct code fixes. To this end, we introduce Defects4J-NL2Fix, a dataset of 283 Java programs from the popular Defects4J dataset augmented with high-level descriptions of bug fixes, and empirically evaluate the performance of several state-of-the-art LLMs for the this task. Results show that these LLMS together are capable of generating plausible fixes for 64.6% of the bugs, and the best LLM-based technique can achieve up to 21.20% top-1 and 35.68% top-5 accuracy on this benchmark.
MergeBERT: Program Merge Conflict Resolution via Neural Transformers
Sep 08, 2021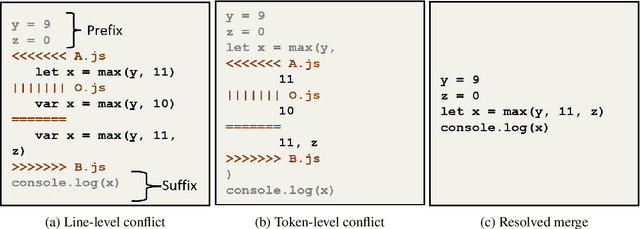
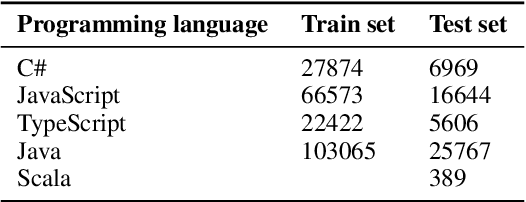

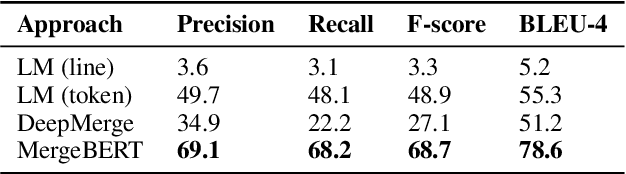
Collaborative software development is an integral part of the modern software development life cycle, essential to the success of large-scale software projects. When multiple developers make concurrent changes around the same lines of code, a merge conflict may occur. Such conflicts stall pull requests and continuous integration pipelines for hours to several days, seriously hurting developer productivity. In this paper, we introduce MergeBERT, a novel neural program merge framework based on the token-level three-way differencing and a transformer encoder model. Exploiting restricted nature of merge conflict resolutions, we reformulate the task of generating the resolution sequence as a classification task over a set of primitive merge patterns extracted from real-world merge commit data. Our model achieves 64--69% precision of merge resolution synthesis, yielding nearly a 2x performance improvement over existing structured and neural program merge tools. Finally, we demonstrate versatility of our model, which is able to perform program merge in a multilingual setting with Java, JavaScript, TypeScript, and C# programming languages, generalizing zero-shot to unseen languages.