 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Neural Synthesis for SMT-Assisted Proof-Oriented Programming
May 03, 2024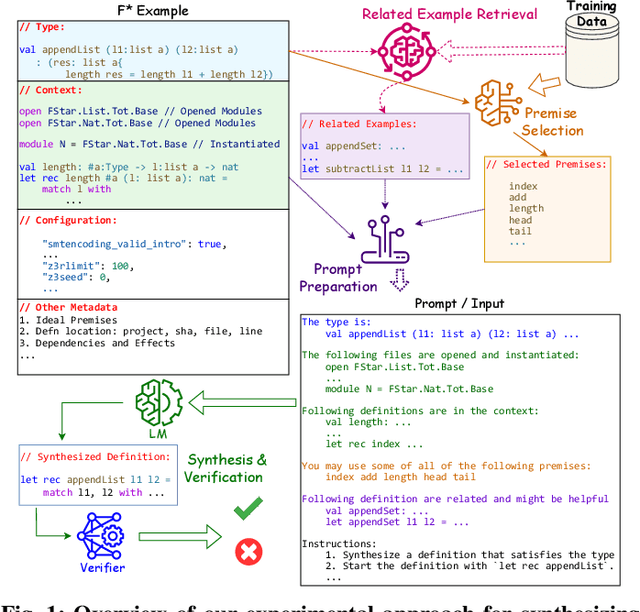
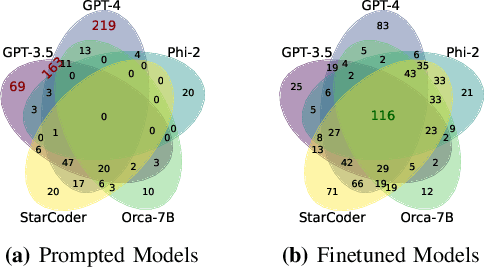
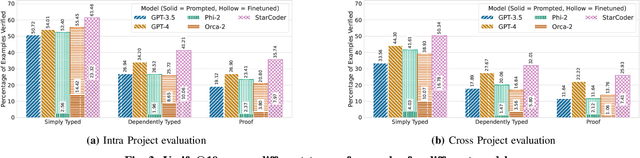
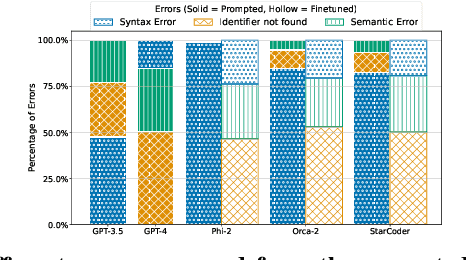
Proof-oriented programs mix computational content with proofs of program correctness. However, the human effort involved in programming and proving is still substantial, despite the use of Satisfiability Modulo Theories (SMT) solvers to automate proofs in languages such as F*. Seeking to spur research on using AI to automate the construction of proof-oriented programs, we curate a dataset of 600K lines of open-source F* programs and proofs, including software used in production systems ranging from Windows and Linux, to Python and Firefox. Our dataset includes around 32K top-level F* definitions, each representing a type-directed program and proof synthesis problem -- producing a definition given a formal specification expressed as an F* type. We provide a program-fragment checker that queries F* to check the correctness of candidate solutions. We believe this is the largest corpus of SMT-assisted program proofs coupled with a reproducible program-fragment checker. Grounded in this dataset, we investigate the use of AI to synthesize programs and their proofs in F*, with promising results. Our main finding in that the performance of fine-tuned smaller language models (such as Phi-2 or StarCoder) compare favorably with large language models (such as GPT-4), at a much lower computational cost. We also identify various type-based retrieval augmentation techniques and find that they boost performance significantly. With detailed error analysis and case studies, we identify potential strengths and weaknesses of models and techniques and suggest directions for future improvements.
Wu's Method can Boost Symbolic AI to Rival Silver Medalists and AlphaGeometry to Outperform Gold Medalists at IMO Geometry
Apr 11, 2024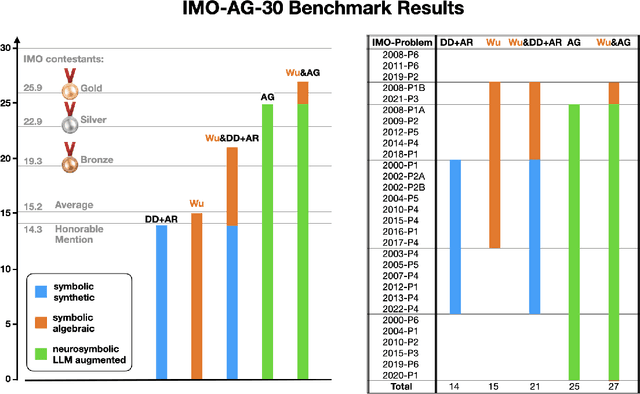
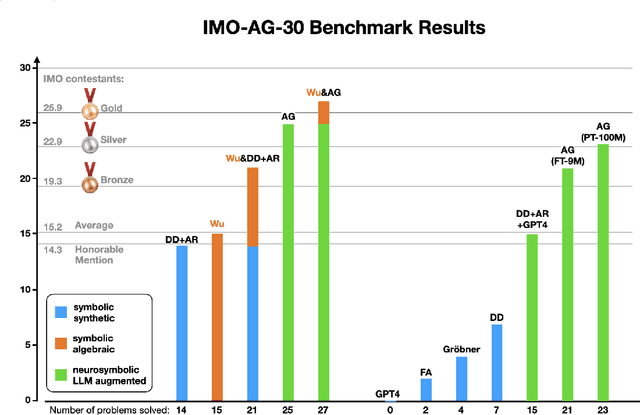
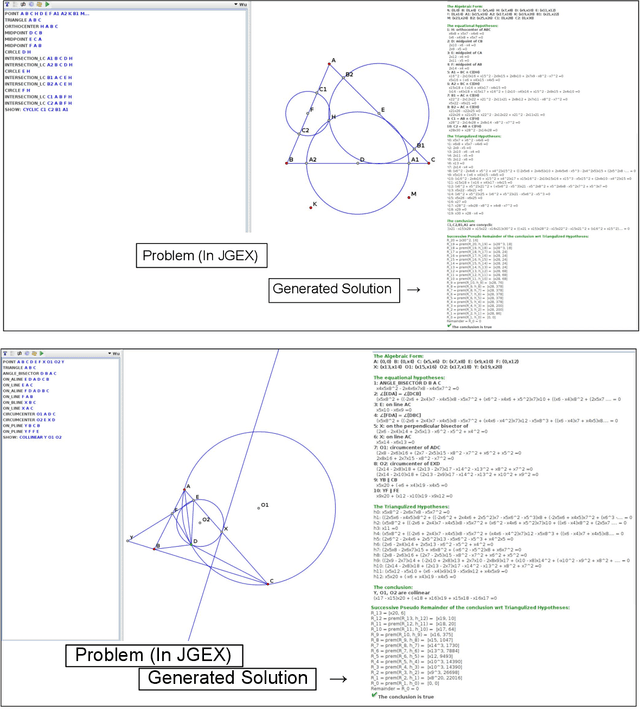
Proving geometric theorems constitutes a hallmark of visual reasoning combining both intuitive and logical skills. Therefore, automated theorem proving of Olympiad-level geometry problems is considered a notable milestone in human-level automated reasoning. The introduction of AlphaGeometry, a neuro-symbolic model trained with 100 million synthetic samples, marked a major breakthrough. It solved 25 of 30 International Mathematical Olympiad (IMO) problems whereas the reported baseline based on Wu's method solved only ten. In this note, we revisit the IMO-AG-30 Challenge introduced with AlphaGeometry, and find that Wu's method is surprisingly strong. Wu's method alone can solve 15 problems, and some of them are not solved by any of the other methods. This leads to two key findings: (i) Combining Wu's method with the classic synthetic methods of deductive databases and angle, ratio, and distance chasing solves 21 out of 30 methods by just using a CPU-only laptop with a time limit of 5 minutes per problem. Essentially, this classic method solves just 4 problems less than AlphaGeometry and establishes the first fully symbolic baseline strong enough to rival the performance of an IMO silver medalist. (ii) Wu's method even solves 2 of the 5 problems that AlphaGeometry failed to solve. Thus, by combining AlphaGeometry with Wu's method we set a new state-of-the-art for automated theorem proving on IMO-AG-30, solving 27 out of 30 problems, the first AI method which outperforms an IMO gold medalist.