 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCan Language Models Falsify? Evaluating Algorithmic Reasoning with Counterexample Creation
Feb 26, 2025There is growing excitement about the potential of Language Models (LMs) to accelerate scientific discovery. Falsifying hypotheses is key to scientific progress, as it allows claims to be iteratively refined over time. This process requires significant researcher effort, reasoning, and ingenuity. Yet current benchmarks for LMs predominantly assess their ability to generate solutions rather than challenge them. We advocate for developing benchmarks that evaluate this inverse capability - creating counterexamples for subtly incorrect solutions. To demonstrate this approach, we start with the domain of algorithmic problem solving, where counterexamples can be evaluated automatically using code execution. Specifically, we introduce REFUTE, a dynamically updating benchmark that includes recent problems and incorrect submissions from programming competitions, where human experts successfully identified counterexamples. Our analysis finds that the best reasoning agents, even OpenAI o3-mini (high) with code execution feedback, can create counterexamples for only <9% of incorrect solutions in REFUTE, even though ratings indicate its ability to solve up to 48% of these problems from scratch. We hope our work spurs progress in evaluating and enhancing LMs' ability to falsify incorrect solutions - a capability that is crucial for both accelerating research and making models self-improve through reliable reflective reasoning.
Wu's Method can Boost Symbolic AI to Rival Silver Medalists and AlphaGeometry to Outperform Gold Medalists at IMO Geometry
Apr 11, 2024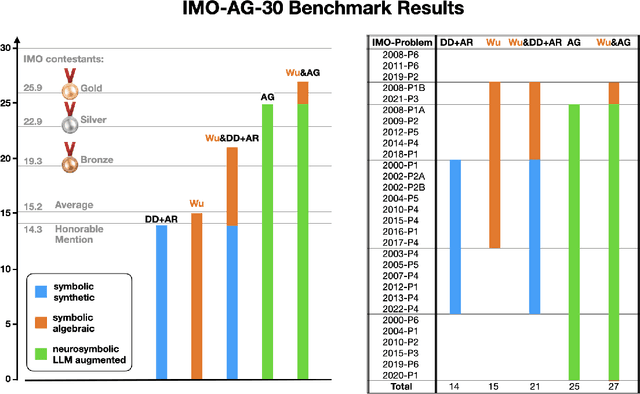
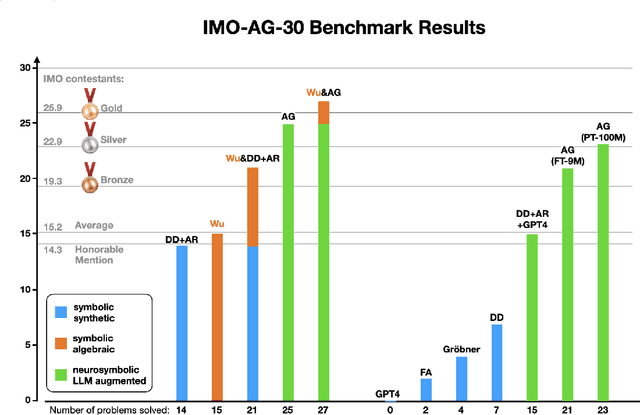
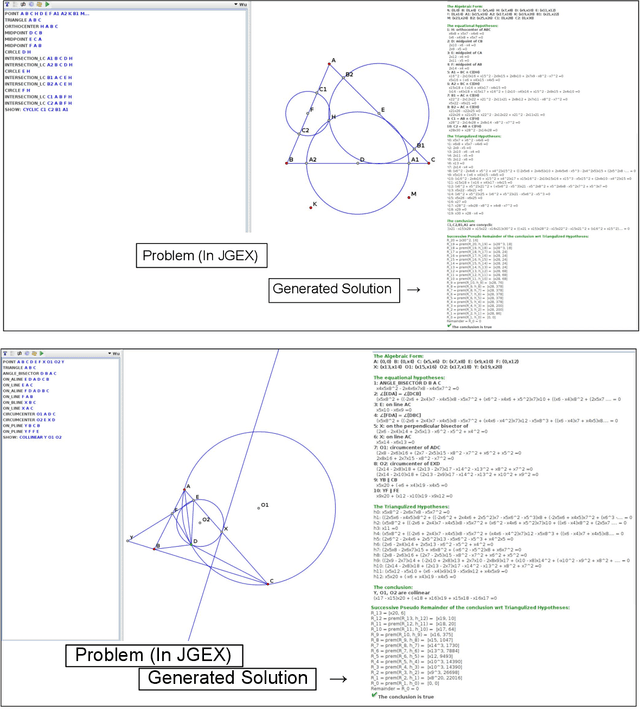
Proving geometric theorems constitutes a hallmark of visual reasoning combining both intuitive and logical skills. Therefore, automated theorem proving of Olympiad-level geometry problems is considered a notable milestone in human-level automated reasoning. The introduction of AlphaGeometry, a neuro-symbolic model trained with 100 million synthetic samples, marked a major breakthrough. It solved 25 of 30 International Mathematical Olympiad (IMO) problems whereas the reported baseline based on Wu's method solved only ten. In this note, we revisit the IMO-AG-30 Challenge introduced with AlphaGeometry, and find that Wu's method is surprisingly strong. Wu's method alone can solve 15 problems, and some of them are not solved by any of the other methods. This leads to two key findings: (i) Combining Wu's method with the classic synthetic methods of deductive databases and angle, ratio, and distance chasing solves 21 out of 30 methods by just using a CPU-only laptop with a time limit of 5 minutes per problem. Essentially, this classic method solves just 4 problems less than AlphaGeometry and establishes the first fully symbolic baseline strong enough to rival the performance of an IMO silver medalist. (ii) Wu's method even solves 2 of the 5 problems that AlphaGeometry failed to solve. Thus, by combining AlphaGeometry with Wu's method we set a new state-of-the-art for automated theorem proving on IMO-AG-30, solving 27 out of 30 problems, the first AI method which outperforms an IMO gold medalist.
RanDumb: A Simple Approach that Questions the Efficacy of Continual Representation Learning
Feb 13, 2024
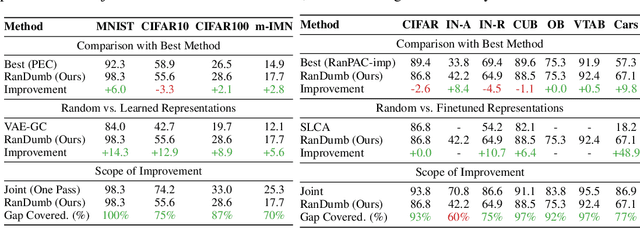


We propose RanDumb to examine the efficacy of continual representation learning. RanDumb embeds raw pixels using a fixed random transform which approximates an RBF-Kernel, initialized before seeing any data, and learns a simple linear classifier on top. We present a surprising and consistent finding: RanDumb significantly outperforms the continually learned representations using deep networks across numerous continual learning benchmarks, demonstrating the poor performance of representation learning in these scenarios. RanDumb stores no exemplars and performs a single pass over the data, processing one sample at a time. It complements GDumb, operating in a low-exemplar regime where GDumb has especially poor performance. We reach the same consistent conclusions when RanDumb is extended to scenarios with pretrained models replacing the random transform with pretrained feature extractor. Our investigation is both surprising and alarming as it questions our understanding of how to effectively design and train models that require efficient continual representation learning, and necessitates a principled reinvestigation of the widely explored problem formulation itself. Our code is available at https://github.com/drimpossible/RanDumb.