 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning to Evict from Key-Value Cache
Feb 10, 2026The growing size of Large Language Models (LLMs) makes efficient inference challenging, primarily due to the memory demands of the autoregressive Key-Value (KV) cache. Existing eviction or compression methods reduce cost but rely on heuristics, such as recency or past attention scores, which serve only as indirect proxies for a token's future utility and introduce computational overhead. We reframe KV cache eviction as a reinforcement learning (RL) problem: learning to rank tokens by their predicted usefulness for future decoding. To this end, we introduce KV Policy (KVP), a framework of lightweight per-head RL agents trained on pre-computed generation traces using only key and value vectors. Each agent learns a specialized eviction policy guided by future utility, which evaluates the quality of the ranking across all cache budgets, requiring no modifications to the underlying LLM or additional inference. Evaluated across two different model families on the long-context benchmark RULER and the multi-turn dialogue benchmark OASST2-4k, KVP significantly outperforms baselines. Furthermore, zero-shot tests on standard downstream tasks (e.g., LongBench, BOOLQ, ARC) indicate that KVP generalizes well beyond its training distribution and to longer context lengths. These results demonstrate that learning to predict future token utility is a powerful and scalable paradigm for adaptive KV cache management.
Robust Autonomy Emerges from Self-Play
Feb 05, 2025Self-play has powered breakthroughs in two-player and multi-player games. Here we show that self-play is a surprisingly effective strategy in another domain. We show that robust and naturalistic driving emerges entirely from self-play in simulation at unprecedented scale -- 1.6~billion~km of driving. This is enabled by Gigaflow, a batched simulator that can synthesize and train on 42 years of subjective driving experience per hour on a single 8-GPU node. The resulting policy achieves state-of-the-art performance on three independent autonomous driving benchmarks. The policy outperforms the prior state of the art when tested on recorded real-world scenarios, amidst human drivers, without ever seeing human data during training. The policy is realistic when assessed against human references and achieves unprecedented robustness, averaging 17.5 years of continuous driving between incidents in simulation.
Leveraging Cardiovascular Simulations for In-Vivo Prediction of Cardiac Biomarkers
Dec 23, 2024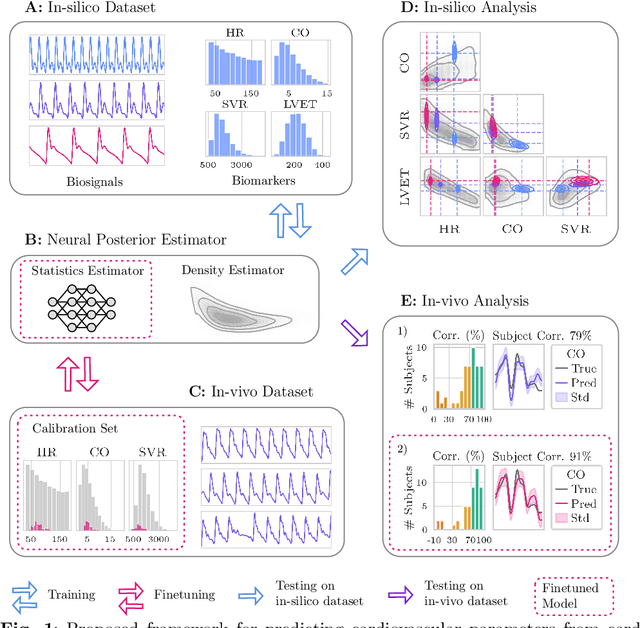
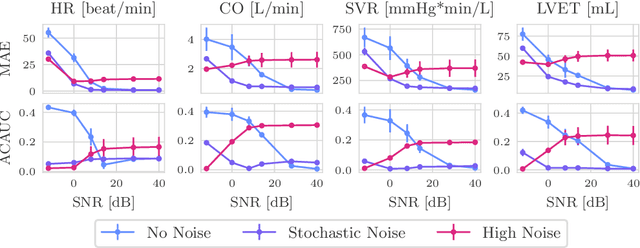
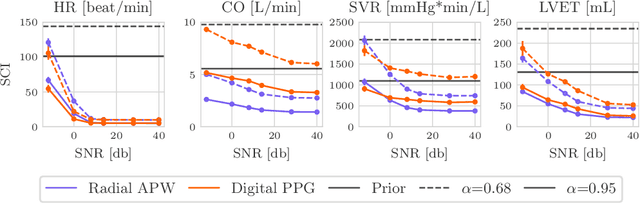
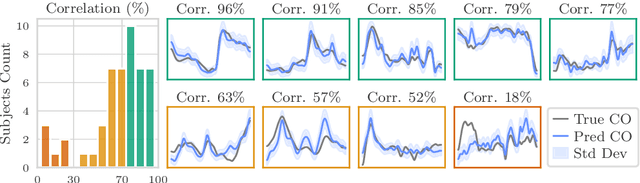
Whole-body hemodynamics simulators, which model blood flow and pressure waveforms as functions of physiological parameters, are now essential tools for studying cardiovascular systems. However, solving the corresponding inverse problem of mapping observations (e.g., arterial pressure waveforms at specific locations in the arterial network) back to plausible physiological parameters remains challenging. Leveraging recent advances in simulation-based inference, we cast this problem as statistical inference by training an amortized neural posterior estimator on a newly built large dataset of cardiac simulations that we publicly release. To better align simulated data with real-world measurements, we incorporate stochastic elements modeling exogenous effects. The proposed framework can further integrate in-vivo data sources to refine its predictive capabilities on real-world data. In silico, we demonstrate that the proposed framework enables finely quantifying uncertainty associated with individual measurements, allowing trustworthy prediction of four biomarkers of clinical interest--namely Heart Rate, Cardiac Output, Systemic Vascular Resistance, and Left Ventricular Ejection Time--from arterial pressure waveforms and photoplethysmograms. Furthermore, we validate the framework in vivo, where our method accurately captures temporal trends in CO and SVR monitoring on the VitalDB dataset. Finally, the predictive error made by the model monotonically increases with the predicted uncertainty, thereby directly supporting the automatic rejection of unusable measurements.
Addressing Misspecification in Simulation-based Inference through Data-driven Calibration
May 14, 2024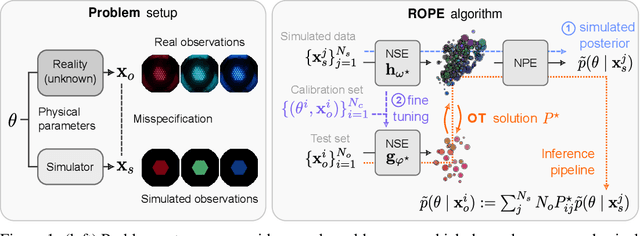
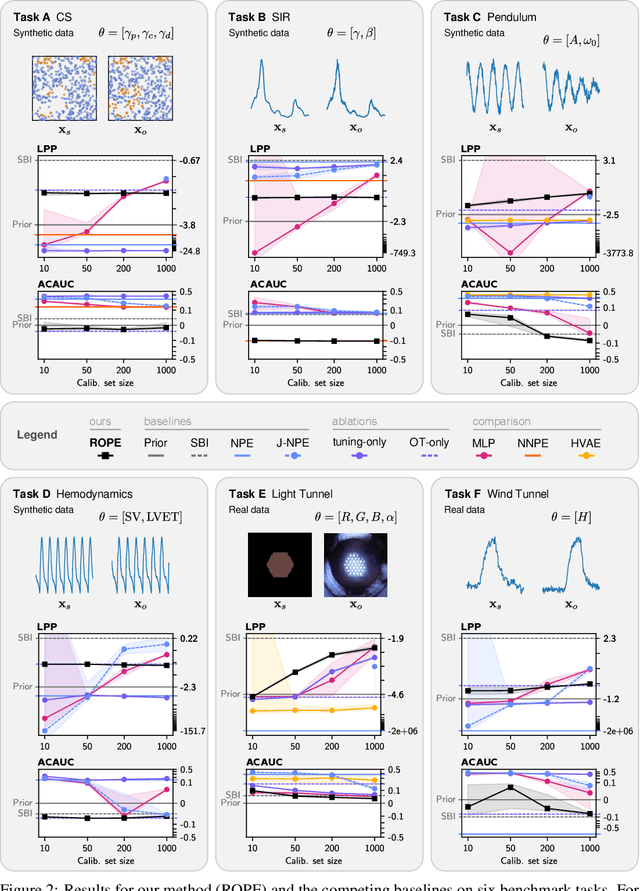
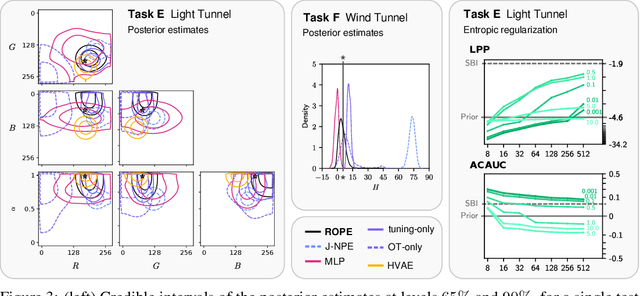
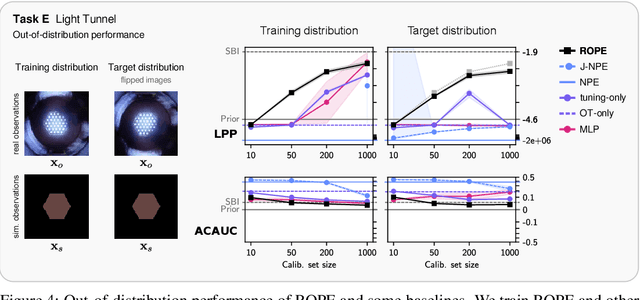
Driven by steady progress in generative modeling, simulation-based inference (SBI) has enabled inference over stochastic simulators. However, recent work has demonstrated that model misspecification can harm SBI's reliability. This work introduces robust posterior estimation (ROPE), a framework that overcomes model misspecification with a small real-world calibration set of ground truth parameter measurements. We formalize the misspecification gap as the solution of an optimal transport problem between learned representations of real-world and simulated observations. Assuming the prior distribution over the parameters of interest is known and well-specified, our method offers a controllable balance between calibrated uncertainty and informative inference under all possible misspecifications of the simulator. Our empirical results on four synthetic tasks and two real-world problems demonstrate that ROPE outperforms baselines and consistently returns informative and calibrated credible intervals.
RanDumb: A Simple Approach that Questions the Efficacy of Continual Representation Learning
Feb 13, 2024
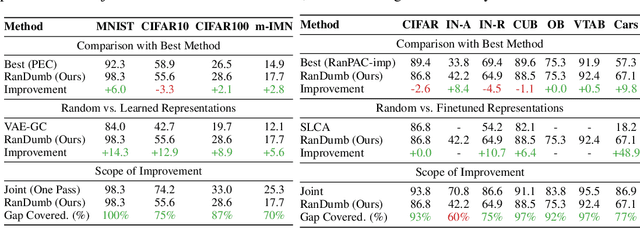


We propose RanDumb to examine the efficacy of continual representation learning. RanDumb embeds raw pixels using a fixed random transform which approximates an RBF-Kernel, initialized before seeing any data, and learns a simple linear classifier on top. We present a surprising and consistent finding: RanDumb significantly outperforms the continually learned representations using deep networks across numerous continual learning benchmarks, demonstrating the poor performance of representation learning in these scenarios. RanDumb stores no exemplars and performs a single pass over the data, processing one sample at a time. It complements GDumb, operating in a low-exemplar regime where GDumb has especially poor performance. We reach the same consistent conclusions when RanDumb is extended to scenarios with pretrained models replacing the random transform with pretrained feature extractor. Our investigation is both surprising and alarming as it questions our understanding of how to effectively design and train models that require efficient continual representation learning, and necessitates a principled reinvestigation of the widely explored problem formulation itself. Our code is available at https://github.com/drimpossible/RanDumb.
Domain Generalization without Excess Empirical Risk
Aug 30, 2023Given data from diverse sets of distinct distributions, domain generalization aims to learn models that generalize to unseen distributions. A common approach is designing a data-driven surrogate penalty to capture generalization and minimize the empirical risk jointly with the penalty. We argue that a significant failure mode of this recipe is an excess risk due to an erroneous penalty or hardness in joint optimization. We present an approach that eliminates this problem. Instead of jointly minimizing empirical risk with the penalty, we minimize the penalty under the constraint of optimality of the empirical risk. This change guarantees that the domain generalization penalty cannot impair optimization of the empirical risk, i.e., in-distribution performance. To solve the proposed optimization problem, we demonstrate an exciting connection to rate-distortion theory and utilize its tools to design an efficient method. Our approach can be applied to any penalty-based domain generalization method, and we demonstrate its effectiveness by applying it to three examplar methods from the literature, showing significant improvements.
Generalized Sum Pooling for Metric Learning
Aug 21, 2023A common architectural choice for deep metric learning is a convolutional neural network followed by global average pooling (GAP). Albeit simple, GAP is a highly effective way to aggregate information. One possible explanation for the effectiveness of GAP is considering each feature vector as representing a different semantic entity and GAP as a convex combination of them. Following this perspective, we generalize GAP and propose a learnable generalized sum pooling method (GSP). GSP improves GAP with two distinct abilities: i) the ability to choose a subset of semantic entities, effectively learning to ignore nuisance information, and ii) learning the weights corresponding to the importance of each entity. Formally, we propose an entropy-smoothed optimal transport problem and show that it is a strict generalization of GAP, i.e., a specific realization of the problem gives back GAP. We show that this optimization problem enjoys analytical gradients enabling us to use it as a direct learnable replacement for GAP. We further propose a zero-shot loss to ease the learning of GSP. We show the effectiveness of our method with extensive evaluations on 4 popular metric learning benchmarks. Code is available at: GSP-DML Framework
Simulation-based Inference for Cardiovascular Models
Jul 29, 2023Over the past decades, hemodynamics simulators have steadily evolved and have become tools of choice for studying cardiovascular systems in-silico. While such tools are routinely used to simulate whole-body hemodynamics from physiological parameters, solving the corresponding inverse problem of mapping waveforms back to plausible physiological parameters remains both promising and challenging. Motivated by advances in simulation-based inference (SBI), we cast this inverse problem as statistical inference. In contrast to alternative approaches, SBI provides \textit{posterior distributions} for the parameters of interest, providing a \textit{multi-dimensional} representation of uncertainty for \textit{individual} measurements. We showcase this ability by performing an in-silico uncertainty analysis of five biomarkers of clinical interest comparing several measurement modalities. Beyond the corroboration of known facts, such as the feasibility of estimating heart rate, our study highlights the potential of estimating new biomarkers from standard-of-care measurements. SBI reveals practically relevant findings that cannot be captured by standard sensitivity analyses, such as the existence of sub-populations for which parameter estimation exhibits distinct uncertainty regimes. Finally, we study the gap between in-vivo and in-silico with the MIMIC-III waveform database and critically discuss how cardiovascular simulations can inform real-world data analysis.
Online Continual Learning Without the Storage Constraint
May 16, 2023



Online continual learning (OCL) research has primarily focused on mitigating catastrophic forgetting with fixed and limited storage allocation throughout the agent's lifetime. However, the growing affordability of data storage highlights a broad range of applications that do not adhere to these assumptions. In these cases, the primary concern lies in managing computational expenditures rather than storage. In this paper, we target such settings, investigating the online continual learning problem by relaxing storage constraints and emphasizing fixed, limited economical budget. We provide a simple algorithm that can compactly store and utilize the entirety of the incoming data stream under tiny computational budgets using a kNN classifier and universal pre-trained feature extractors. Our algorithm provides a consistency property attractive to continual learning: It will never forget past seen data. We set a new state of the art on two large-scale OCL datasets: Continual LOCalization (CLOC), which has 39M images over 712 classes, and Continual Google Landmarks V2 (CGLM), which has 580K images over 10,788 classes -- beating methods under far higher computational budgets than ours in terms of both reducing catastrophic forgetting of past data and quickly adapting to rapidly changing data streams. We provide code to reproduce our results at \url{https://github.com/drimpossible/ACM}.
Generalizing Gaussian Smoothing for Random Search
Nov 27, 2022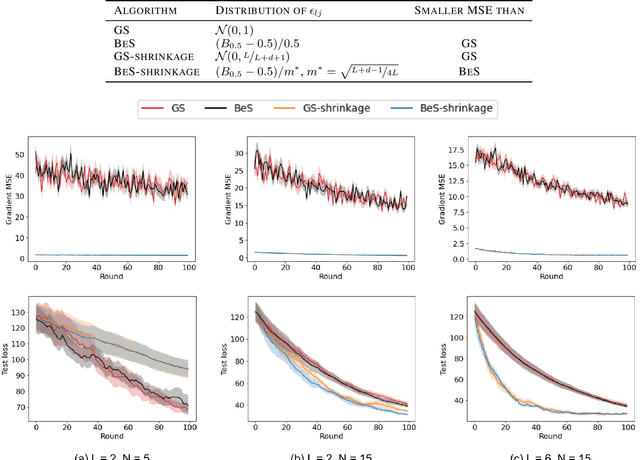
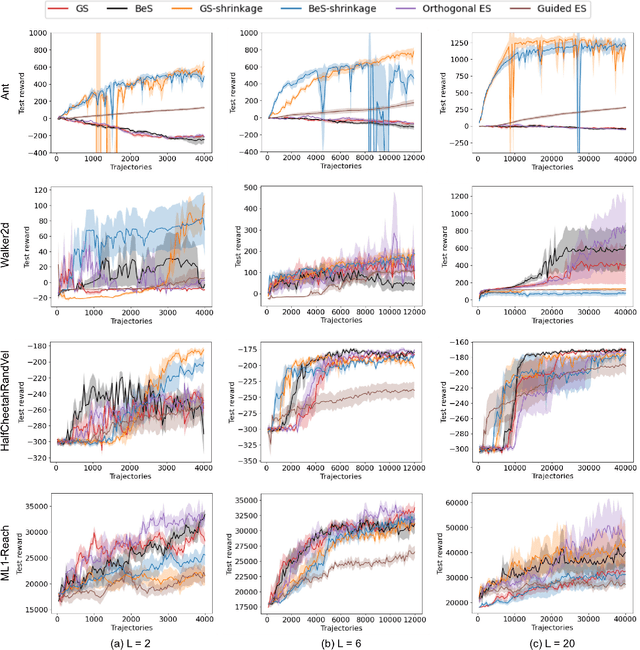
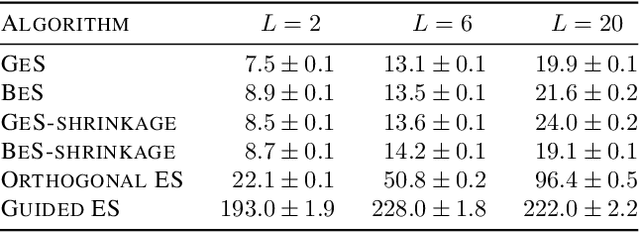
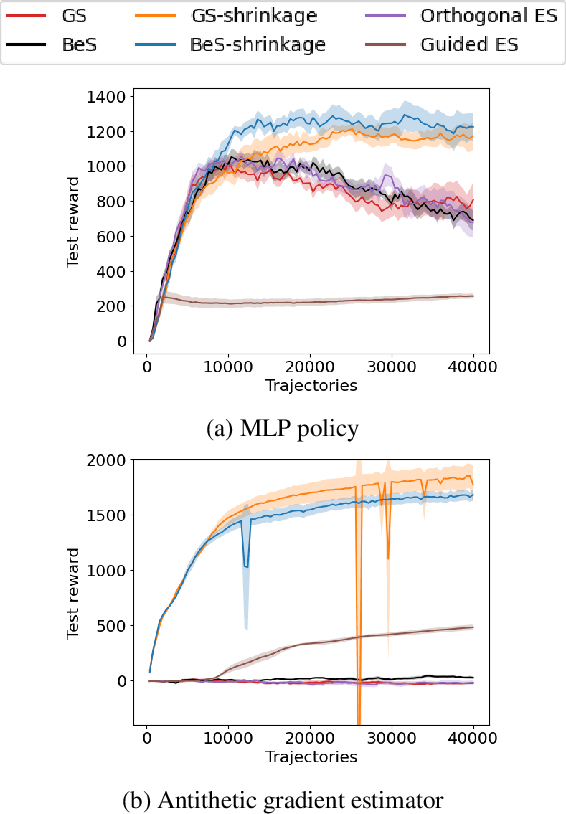
Gaussian smoothing (GS) is a derivative-free optimization (DFO) algorithm that estimates the gradient of an objective using perturbations of the current parameters sampled from a standard normal distribution. We generalize it to sampling perturbations from a larger family of distributions. Based on an analysis of DFO for non-convex functions, we propose to choose a distribution for perturbations that minimizes the mean squared error (MSE) of the gradient estimate. We derive three such distributions with provably smaller MSE than Gaussian smoothing. We conduct evaluations of the three sampling distributions on linear regression, reinforcement learning, and DFO benchmarks in order to validate our claims. Our proposal improves on GS with the same computational complexity, and are usually competitive with and often outperform Guided ES and Orthogonal ES, two computationally more expensive algorithms that adapt the covariance matrix of normally distributed perturbations.