 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCausal Transformer for Fusion and Pose Estimation in Deep Visual Inertial Odometry
Sep 13, 2024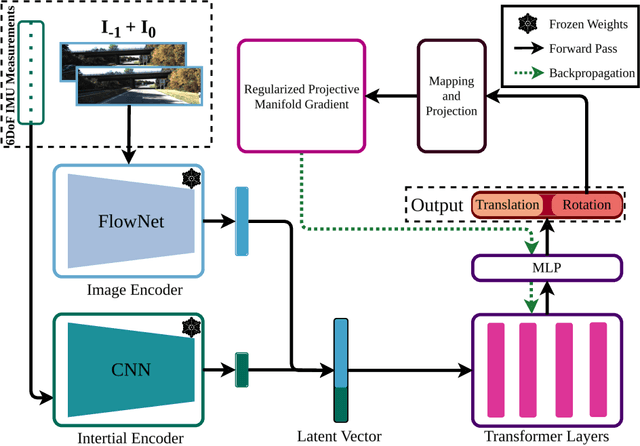
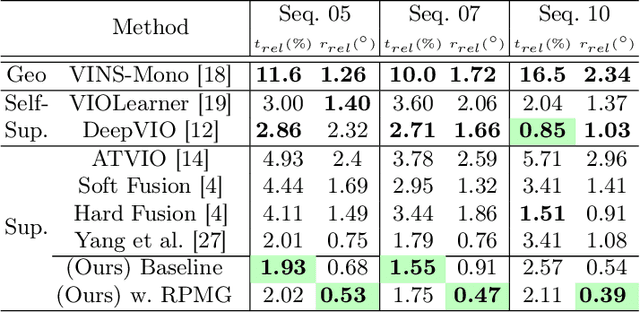
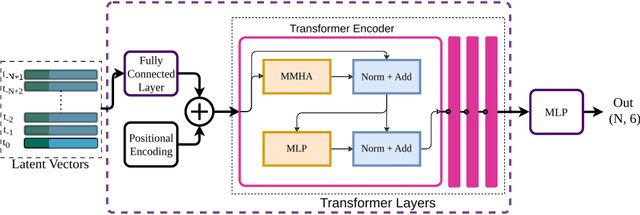
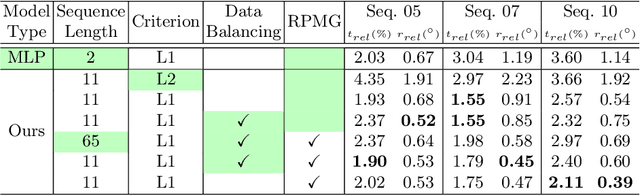
In recent years, transformer-based architectures become the de facto standard for sequence modeling in deep learning frameworks. Inspired by the successful examples, we propose a causal visual-inertial fusion transformer (VIFT) for pose estimation in deep visual-inertial odometry. This study aims to improve pose estimation accuracy by leveraging the attention mechanisms in transformers, which better utilize historical data compared to the recurrent neural network (RNN) based methods seen in recent methods. Transformers typically require large-scale data for training. To address this issue, we utilize inductive biases for deep VIO networks. Since latent visual-inertial feature vectors encompass essential information for pose estimation, we employ transformers to refine pose estimates by updating latent vectors temporally. Our study also examines the impact of data imbalance and rotation learning methods in supervised end-to-end learning of visual inertial odometry by utilizing specialized gradients in backpropagation for the elements of SE$(3)$ group. The proposed method is end-to-end trainable and requires only a monocular camera and IMU during inference. Experimental results demonstrate that VIFT increases the accuracy of monocular VIO networks, achieving state-of-the-art results when compared to previous methods on the KITTI dataset. The code will be made available at https://github.com/ybkurt/VIFT.
XoFTR: Cross-modal Feature Matching Transformer
Apr 15, 2024



We introduce, XoFTR, a cross-modal cross-view method for local feature matching between thermal infrared (TIR) and visible images. Unlike visible images, TIR images are less susceptible to adverse lighting and weather conditions but present difficulties in matching due to significant texture and intensity differences. Current hand-crafted and learning-based methods for visible-TIR matching fall short in handling viewpoint, scale, and texture diversities. To address this, XoFTR incorporates masked image modeling pre-training and fine-tuning with pseudo-thermal image augmentation to handle the modality differences. Additionally, we introduce a refined matching pipeline that adjusts for scale discrepancies and enhances match reliability through sub-pixel level refinement. To validate our approach, we collect a comprehensive visible-thermal dataset, and show that our method outperforms existing methods on many benchmarks.
Generalized Sum Pooling for Metric Learning
Aug 21, 2023



A common architectural choice for deep metric learning is a convolutional neural network followed by global average pooling (GAP). Albeit simple, GAP is a highly effective way to aggregate information. One possible explanation for the effectiveness of GAP is considering each feature vector as representing a different semantic entity and GAP as a convex combination of them. Following this perspective, we generalize GAP and propose a learnable generalized sum pooling method (GSP). GSP improves GAP with two distinct abilities: i) the ability to choose a subset of semantic entities, effectively learning to ignore nuisance information, and ii) learning the weights corresponding to the importance of each entity. Formally, we propose an entropy-smoothed optimal transport problem and show that it is a strict generalization of GAP, i.e., a specific realization of the problem gives back GAP. We show that this optimization problem enjoys analytical gradients enabling us to use it as a direct learnable replacement for GAP. We further propose a zero-shot loss to ease the learning of GSP. We show the effectiveness of our method with extensive evaluations on 4 popular metric learning benchmarks. Code is available at: GSP-DML Framework
MAEVI: Motion Aware Event-Based Video Frame Interpolation
Mar 03, 2023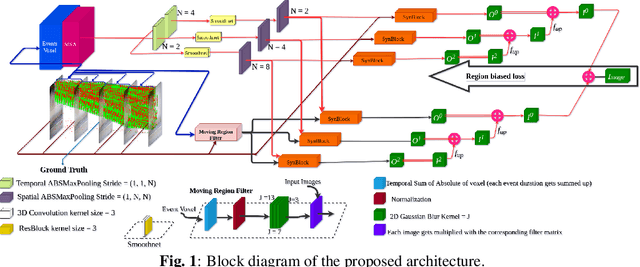

Utilization of event-based cameras is expected to improve the visual quality of video frame interpolation solutions. We introduce a learning-based method to exploit moving region boundaries in a video sequence to increase the overall interpolation quality.Event cameras allow us to determine moving areas precisely; and hence, better video frame interpolation quality can be achieved by emphasizing these regions using an appropriate loss function. The results show a notable average \textit{PSNR} improvement of $1.3$ dB for the tested data sets, as well as subjectively more pleasing visual results with less ghosting and blurry artifacts.
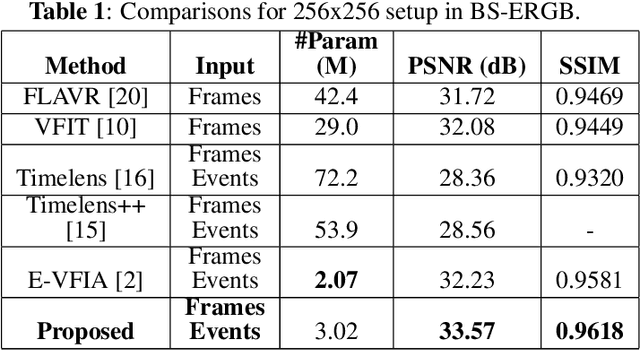
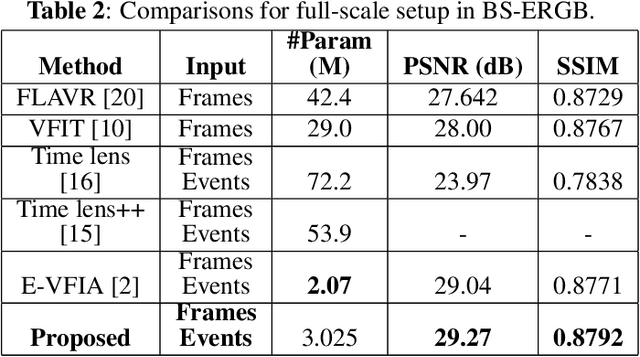
E-VFIA : Event-Based Video Frame Interpolation with Attention
Sep 19, 2022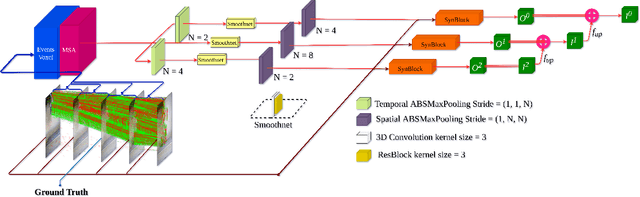
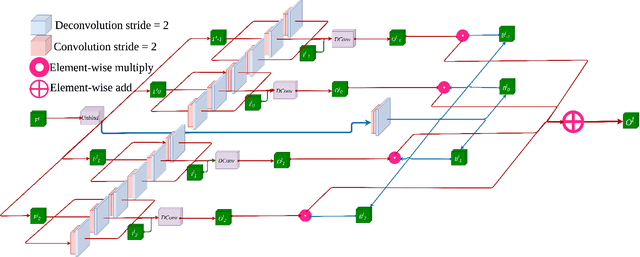
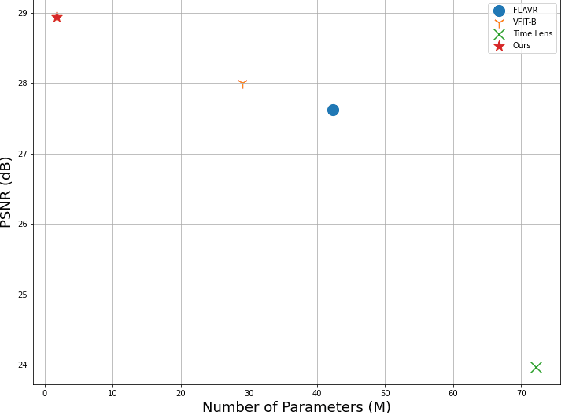
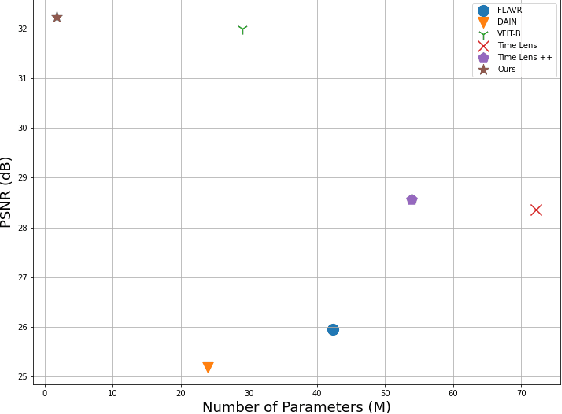
Video frame interpolation (VFI) is a fundamental vision task that aims to synthesize several frames between two consecutive original video images. Most algorithms aim to accomplish VFI by using only keyframes, which is an ill-posed problem since the keyframes usually do not yield any accurate precision about the trajectories of the objects in the scene. On the other hand, event-based cameras provide more precise information between the keyframes of a video. Some recent state-of-the-art event-based methods approach this problem by utilizing event data for better optical flow estimation to interpolate for video frame by warping. Nonetheless, those methods heavily suffer from the ghosting effect. On the other hand, some of kernel-based VFI methods that only use frames as input, have shown that deformable convolutions, when backed up with transformers, can be a reliable way of dealing with long-range dependencies. We propose event-based video frame interpolation with attention (E-VFIA), as a lightweight kernel-based method. E-VFIA fuses event information with standard video frames by deformable convolutions to generate high quality interpolated frames. The proposed method represents events with high temporal resolution and uses a multi-head self-attention mechanism to better encode event-based information, while being less vulnerable to blurring and ghosting artifacts; thus, generating crispier frames. The simulation results show that the proposed technique outperforms current state-of-the-art methods (both frame and event-based) with a significantly smaller model size.
Blind Deinterleaving of Signals in Time Series with Self-attention Based Soft Min-cost Flow Learning
Oct 24, 2020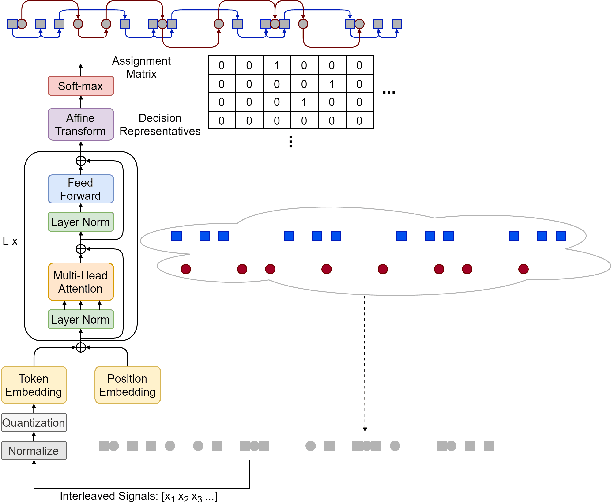

We propose an end-to-end learning approach to address deinterleaving of patterns in time series, in particular, radar signals. We link signal clustering problem to min-cost flow as an equivalent problem once the proper costs exist. We formulate a bi-level optimization problem involving min-cost flow as a sub-problem to learn such costs from the supervised training data. We then approximate the lower level optimization problem by self-attention based neural networks and provide a trainable framework that clusters the patterns in the input as the distinct flows. We evaluate our method with extensive experiments on a large dataset with several challenging scenarios to show the efficiency.
Deep Metric Learning with Alternating Projections onto Feasible Sets
Jul 17, 2019
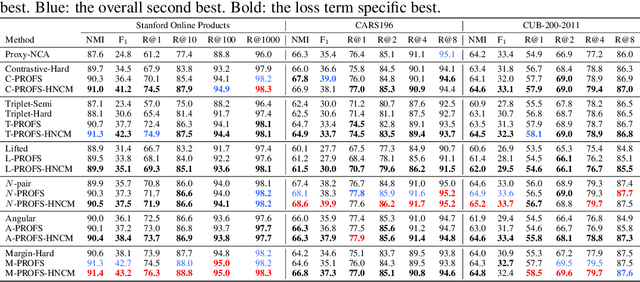
During the training of networks for distance metric learning, minimizers of the typical loss functions can be considered as "feasible points" satisfying a set of constraints imposed by the training data. To this end, we reformulate deep metric learning problem as finding a feasible point of a constraint set where the embedding vectors of the training data satisfy desired intra-class and inter-class proximity. The feasible set induced by the constraint set is expressed as the intersection of the relaxed feasible sets which enforce the proximity constraints only for particular samples (a sample from each class) of the training data. Then, the feasible point problem is to be approximately solved by performing alternating projections onto those feasible sets. Such an approach results in minimizing a typical loss function with a systematic batch set construction where these batches are constrained to contain the same sample from each class for a certain number of iterations. Moreover, these particular samples can be considered as the class representatives, allowing efficient utilization of hard class mining during batch construction. The proposed technique is applied with the contrastive, triplet, lifted structured, $N$-pair, angular and margin-based losses and evaluated on Stanford Online Products, CAR196 and CUB200-2011 datasets for image retrieval and clustering. The proposed approach outperforms state-of-the-art for all 6 loss functions with no additional computational cost and boosts its performance further by hard negative class mining.