 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCausal Transformer for Fusion and Pose Estimation in Deep Visual Inertial Odometry
Sep 13, 2024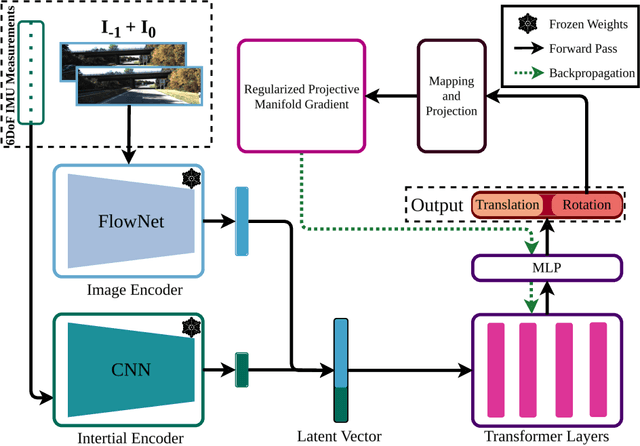
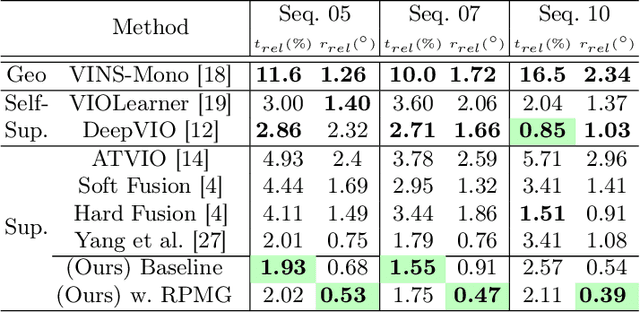
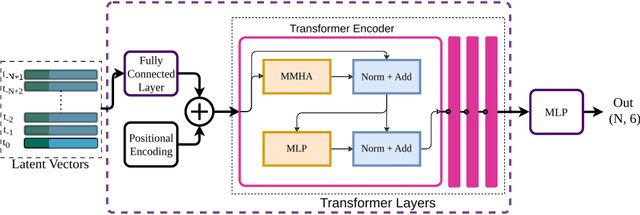
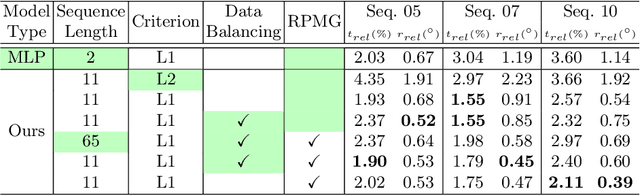
In recent years, transformer-based architectures become the de facto standard for sequence modeling in deep learning frameworks. Inspired by the successful examples, we propose a causal visual-inertial fusion transformer (VIFT) for pose estimation in deep visual-inertial odometry. This study aims to improve pose estimation accuracy by leveraging the attention mechanisms in transformers, which better utilize historical data compared to the recurrent neural network (RNN) based methods seen in recent methods. Transformers typically require large-scale data for training. To address this issue, we utilize inductive biases for deep VIO networks. Since latent visual-inertial feature vectors encompass essential information for pose estimation, we employ transformers to refine pose estimates by updating latent vectors temporally. Our study also examines the impact of data imbalance and rotation learning methods in supervised end-to-end learning of visual inertial odometry by utilizing specialized gradients in backpropagation for the elements of SE$(3)$ group. The proposed method is end-to-end trainable and requires only a monocular camera and IMU during inference. Experimental results demonstrate that VIFT increases the accuracy of monocular VIO networks, achieving state-of-the-art results when compared to previous methods on the KITTI dataset. The code will be made available at https://github.com/ybkurt/VIFT.
MAEVI: Motion Aware Event-Based Video Frame Interpolation
Mar 03, 2023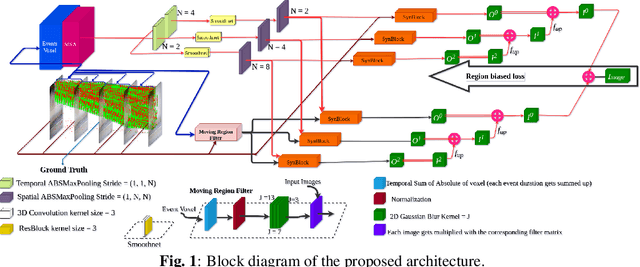

Utilization of event-based cameras is expected to improve the visual quality of video frame interpolation solutions. We introduce a learning-based method to exploit moving region boundaries in a video sequence to increase the overall interpolation quality.Event cameras allow us to determine moving areas precisely; and hence, better video frame interpolation quality can be achieved by emphasizing these regions using an appropriate loss function. The results show a notable average \textit{PSNR} improvement of $1.3$ dB for the tested data sets, as well as subjectively more pleasing visual results with less ghosting and blurry artifacts.
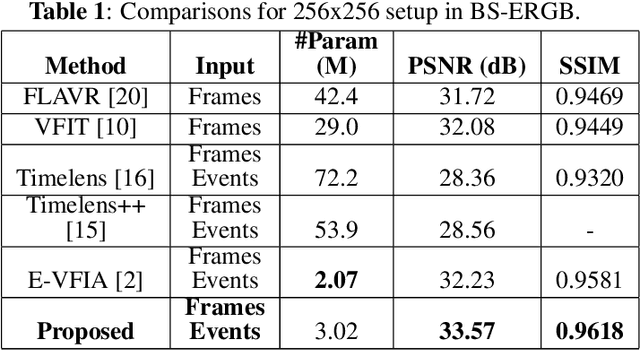
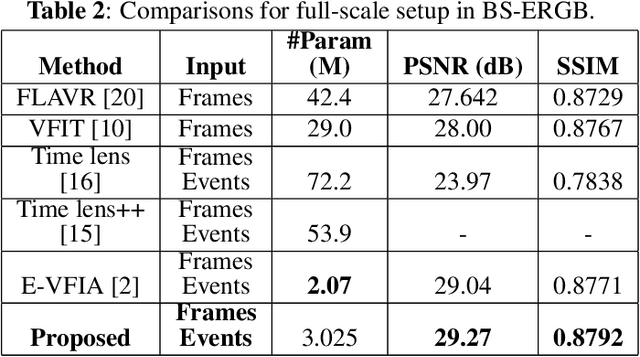
E-VFIA : Event-Based Video Frame Interpolation with Attention
Sep 19, 2022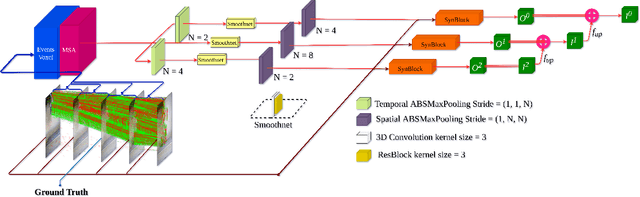
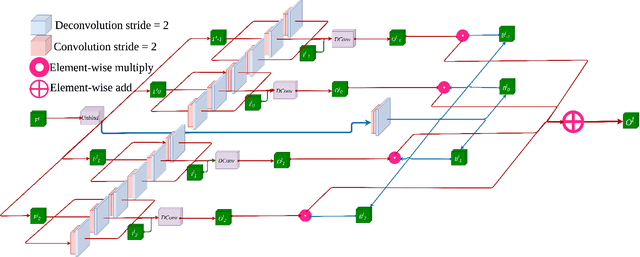
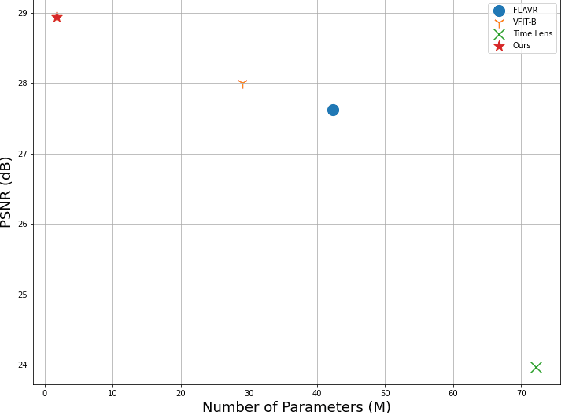
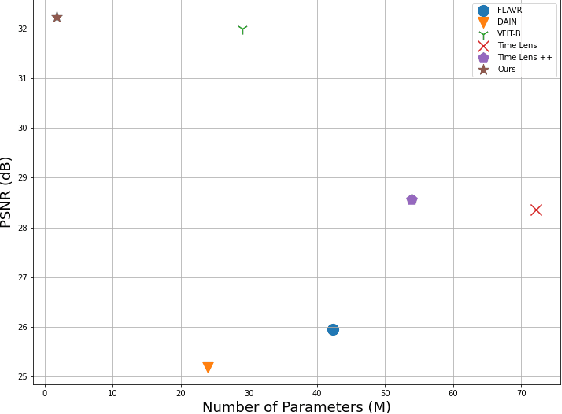
Video frame interpolation (VFI) is a fundamental vision task that aims to synthesize several frames between two consecutive original video images. Most algorithms aim to accomplish VFI by using only keyframes, which is an ill-posed problem since the keyframes usually do not yield any accurate precision about the trajectories of the objects in the scene. On the other hand, event-based cameras provide more precise information between the keyframes of a video. Some recent state-of-the-art event-based methods approach this problem by utilizing event data for better optical flow estimation to interpolate for video frame by warping. Nonetheless, those methods heavily suffer from the ghosting effect. On the other hand, some of kernel-based VFI methods that only use frames as input, have shown that deformable convolutions, when backed up with transformers, can be a reliable way of dealing with long-range dependencies. We propose event-based video frame interpolation with attention (E-VFIA), as a lightweight kernel-based method. E-VFIA fuses event information with standard video frames by deformable convolutions to generate high quality interpolated frames. The proposed method represents events with high temporal resolution and uses a multi-head self-attention mechanism to better encode event-based information, while being less vulnerable to blurring and ghosting artifacts; thus, generating crispier frames. The simulation results show that the proposed technique outperforms current state-of-the-art methods (both frame and event-based) with a significantly smaller model size.