 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGuideline2Graph: Profile-Aware Multimodal Parsing for Executable Clinical Decision Graphs
Apr 02, 2026Clinical practice guidelines are long, multimodal documents whose branching recommendations are difficult to convert into executable clinical decision support (CDS), and one-shot parsing often breaks cross-page continuity. Recent LLM/VLM extractors are mostly local or text-centric, under-specifying section interfaces and failing to consolidate cross-page control flow across full documents into one coherent decision graph. We present a decomposition-first pipeline that converts full-guideline evidence into an executable clinical decision graph through topology-aware chunking, interface-constrained chunk graph generation, and provenance-preserving global aggregation. Rather than relying on single-pass generation, the pipeline uses explicit entry/terminal interfaces and semantic deduplication to preserve cross-page continuity while keeping the induced control flow auditable and structurally consistent. We evaluate on an adjudicated prostate-guideline benchmark with matched inputs and the same underlying VLM backbone across compared methods. On the complete merged graph, our approach improves edge and triplet precision/recall from $19.6\%/16.1\%$ in existing models to $69.0\%/87.5\%$, while node recall rises from $78.1\%$ to $93.8\%$. These results support decomposition-first, auditable guideline-to-CDS conversion on this benchmark, while current evidence remains limited to one adjudicated prostate guideline and motivates broader multi-guideline validation.
Knowledge Distillation Layer that Lets the Student Decide
Sep 06, 2023Typical technique in knowledge distillation (KD) is regularizing the learning of a limited capacity model (student) by pushing its responses to match a powerful model's (teacher). Albeit useful especially in the penultimate layer and beyond, its action on student's feature transform is rather implicit, limiting its practice in the intermediate layers. To explicitly embed the teacher's knowledge in feature transform, we propose a learnable KD layer for the student which improves KD with two distinct abilities: i) learning how to leverage the teacher's knowledge, enabling to discard nuisance information, and ii) feeding forward the transferred knowledge deeper. Thus, the student enjoys the teacher's knowledge during the inference besides training. Formally, we repurpose 1x1-BN-ReLU-1x1 convolution block to assign a semantic vector to each local region according to the template (supervised by the teacher) that the corresponding region of the student matches. To facilitate template learning in the intermediate layers, we propose a novel form of supervision based on the teacher's decisions. Through rigorous experimentation, we demonstrate the effectiveness of our approach on 3 popular classification benchmarks. Code is available at: https://github.com/adagorgun/letKD-framework
Generalized Sum Pooling for Metric Learning
Aug 21, 2023



A common architectural choice for deep metric learning is a convolutional neural network followed by global average pooling (GAP). Albeit simple, GAP is a highly effective way to aggregate information. One possible explanation for the effectiveness of GAP is considering each feature vector as representing a different semantic entity and GAP as a convex combination of them. Following this perspective, we generalize GAP and propose a learnable generalized sum pooling method (GSP). GSP improves GAP with two distinct abilities: i) the ability to choose a subset of semantic entities, effectively learning to ignore nuisance information, and ii) learning the weights corresponding to the importance of each entity. Formally, we propose an entropy-smoothed optimal transport problem and show that it is a strict generalization of GAP, i.e., a specific realization of the problem gives back GAP. We show that this optimization problem enjoys analytical gradients enabling us to use it as a direct learnable replacement for GAP. We further propose a zero-shot loss to ease the learning of GSP. We show the effectiveness of our method with extensive evaluations on 4 popular metric learning benchmarks. Code is available at: GSP-DML Framework
Generalizable Embeddings with Cross-batch Metric Learning
Jul 24, 2023Global average pooling (GAP) is a popular component in deep metric learning (DML) for aggregating features. Its effectiveness is often attributed to treating each feature vector as a distinct semantic entity and GAP as a combination of them. Albeit substantiated, such an explanation's algorithmic implications to learn generalizable entities to represent unseen classes, a crucial DML goal, remain unclear. To address this, we formulate GAP as a convex combination of learnable prototypes. We then show that the prototype learning can be expressed as a recursive process fitting a linear predictor to a batch of samples. Building on that perspective, we consider two batches of disjoint classes at each iteration and regularize the learning by expressing the samples of a batch with the prototypes that are fitted to the other batch. We validate our approach on 4 popular DML benchmarks.
Feature Embedding by Template Matching as a ResNet Block
Oct 03, 2022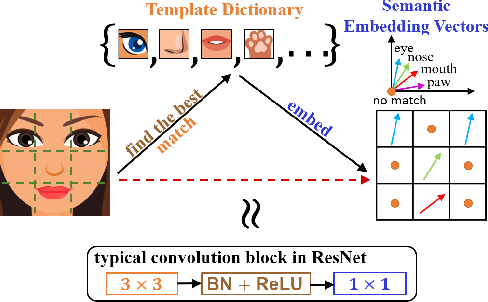
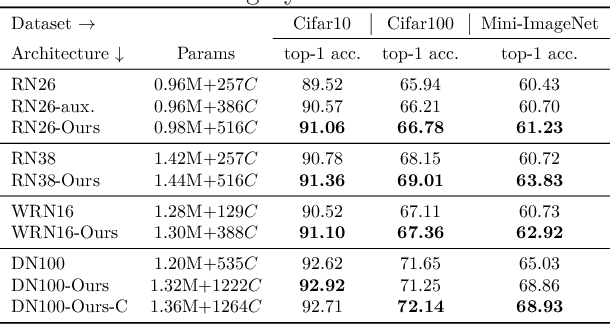
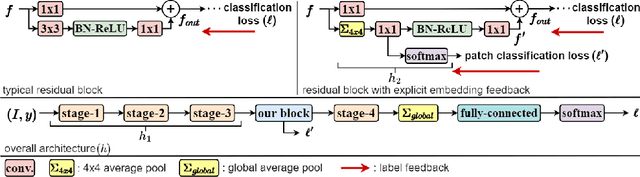
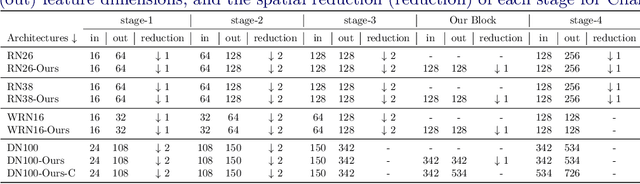
Convolution blocks serve as local feature extractors and are the key to success of the neural networks. To make local semantic feature embedding rather explicit, we reformulate convolution blocks as feature selection according to the best matching kernel. In this manner, we show that typical ResNet blocks indeed perform local feature embedding via template matching once batch normalization (BN) followed by a rectified linear unit (ReLU) is interpreted as arg-max optimizer. Following this perspective, we tailor a residual block that explicitly forces semantically meaningful local feature embedding through using label information. Specifically, we assign a feature vector to each local region according to the classes that the corresponding region matches. We evaluate our method on three popular benchmark datasets with several architectures for image classification and consistently show that our approach substantially improves the performance of the baseline architectures.
Deep Metric Learning with Chance Constraints
Sep 19, 2022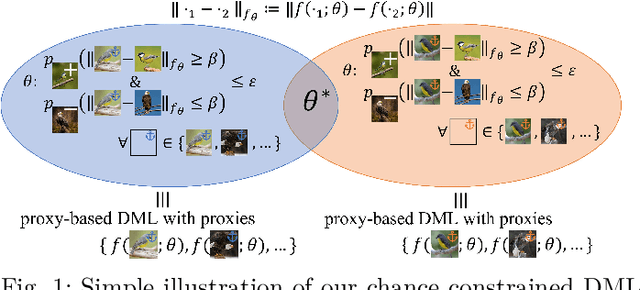
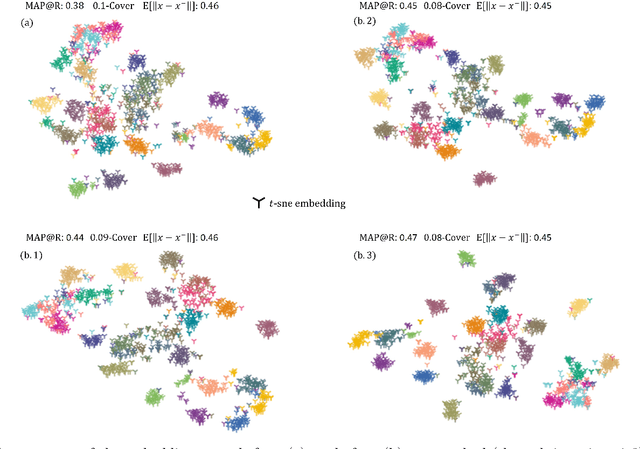
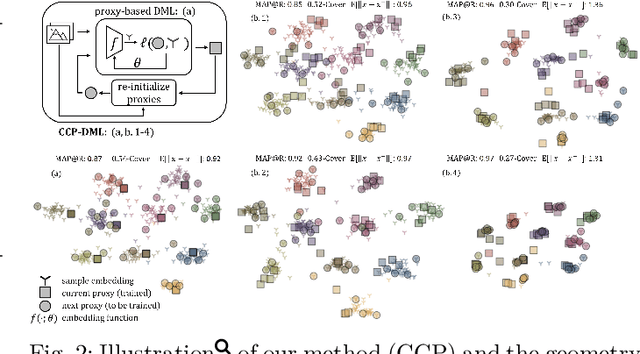

Deep metric learning (DML) aims to minimize empirical expected loss of the pairwise intra-/inter- class proximity violations in the embedding image. We relate DML to feasibility problem of finite chance constraints. We show that minimizer of proxy-based DML satisfies certain chance constraints, and that the worst case generalization performance of the proxy-based methods can be characterized by the radius of the smallest ball around a class proxy to cover the entire domain of the corresponding class samples, suggesting multiple proxies per class helps performance. To provide a scalable algorithm as well as exploiting more proxies, we consider the chance constraints implied by the minimizers of proxy-based DML instances and reformulate DML as finding a feasible point in intersection of such constraints, resulting in a problem to be approximately solved by iterative projections. Simply put, we repeatedly train a regularized proxy-based loss and re-initialize the proxies with the embeddings of the deliberately selected new samples. We apply our method with the well-accepted losses and evaluate on four popular benchmark datasets for image retrieval. Outperforming state-of-the-art, our method consistently improves the performance of the applied losses. Code is available at: https://github.com/yetigurbuz/ccp-dml