 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIsoCompute Playbook: Optimally Scaling Sampling Compute for LLM RL
Mar 12, 2026While scaling laws guide compute allocation for LLM pre-training, analogous prescriptions for reinforcement learning (RL) post-training of large language models (LLMs) remain poorly understood. We study the compute-optimal allocation of sampling compute for on-policy RL methods in LLMs, framing scaling as a compute-constrained optimization over three resources: parallel rollouts per problem, number of problems per batch, and number of update steps. We find that the compute-optimal number of parallel rollouts per problem increases predictably with compute budget and then saturates. This trend holds across both easy and hard problems, though driven by different mechanisms: solution sharpening on easy problems and coverage expansion on hard problems. We further show that increasing the number of parallel rollouts mitigates interference across problems, while the number of problems per batch primarily affects training stability and can be chosen within a broad range. Validated across base models and data distributions, our results recast RL scaling laws as prescriptive allocation rules and provide practical guidance for compute-efficient LLM RL post-training.
Robust Autonomy Emerges from Self-Play
Feb 05, 2025Self-play has powered breakthroughs in two-player and multi-player games. Here we show that self-play is a surprisingly effective strategy in another domain. We show that robust and naturalistic driving emerges entirely from self-play in simulation at unprecedented scale -- 1.6~billion~km of driving. This is enabled by Gigaflow, a batched simulator that can synthesize and train on 42 years of subjective driving experience per hour on a single 8-GPU node. The resulting policy achieves state-of-the-art performance on three independent autonomous driving benchmarks. The policy outperforms the prior state of the art when tested on recorded real-world scenarios, amidst human drivers, without ever seeing human data during training. The policy is realistic when assessed against human references and achieves unprecedented robustness, averaging 17.5 years of continuous driving between incidents in simulation.
Identifying Differential Patient Care Through Inverse Intent Inference
Nov 11, 2024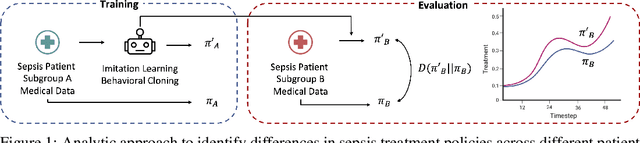


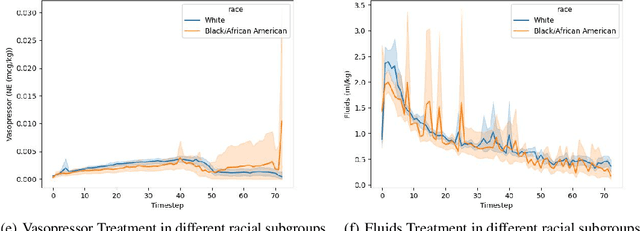
Sepsis is a life-threatening condition defined by end-organ dysfunction due to a dysregulated host response to infection. Although the Surviving Sepsis Campaign has launched and has been releasing sepsis treatment guidelines to unify and normalize the care for sepsis patients, it has been reported in numerous studies that disparities in care exist across the trajectory of patient stay in the emergency department and intensive care unit. Here, we apply a number of reinforcement learning techniques including behavioral cloning, imitation learning, and inverse reinforcement learning, to learn the optimal policy in the management of septic patient subgroups using expert demonstrations. Then we estimate the counterfactual optimal policies by applying the model to another subset of unseen medical populations and identify the difference in cure by comparing it to the real policy. Our data comes from the sepsis cohort of MIMIC-IV and the clinical data warehouses of the Mass General Brigham healthcare system. The ultimate objective of this work is to use the optimal learned policy function to estimate the counterfactual treatment policy and identify deviations across sub-populations of interest. We hope this approach would help us identify any disparities in care and also changes in cure in response to the publication of national sepsis treatment guidelines.
Multiple Sclerosis Severity Classification From Clinical Text
Oct 29, 2020
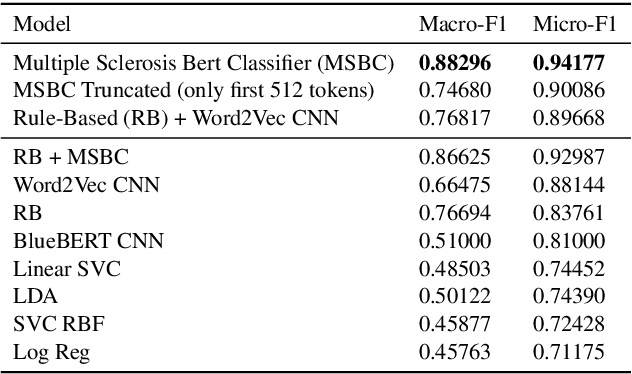
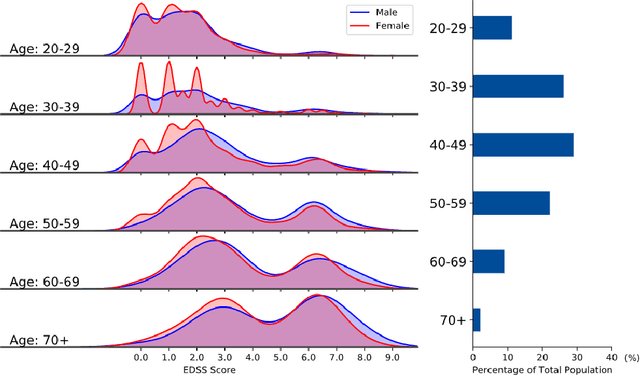
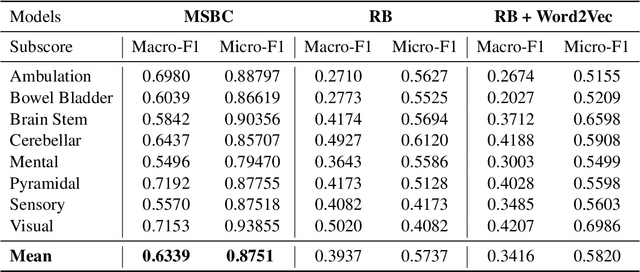
Multiple Sclerosis (MS) is a chronic, inflammatory and degenerative neurological disease, which is monitored by a specialist using the Expanded Disability Status Scale (EDSS) and recorded in unstructured text in the form of a neurology consult note. An EDSS measurement contains an overall "EDSS" score and several functional subscores. Typically, expert knowledge is required to interpret consult notes and generate these scores. Previous approaches used limited context length Word2Vec embeddings and keyword searches to predict scores given a consult note, but often failed when scores were not explicitly stated. In this work, we present MS-BERT, the first publicly available transformer model trained on real clinical data other than MIMIC. Next, we present MSBC, a classifier that applies MS-BERT to generate embeddings and predict EDSS and functional subscores. Lastly, we explore combining MSBC with other models through the use of Snorkel to generate scores for unlabelled consult notes. MSBC achieves state-of-the-art performance on all metrics and prediction tasks and outperforms the models generated from the Snorkel ensemble. We improve Macro-F1 by 0.12 (to 0.88) for predicting EDSS and on average by 0.29 (to 0.63) for predicting functional subscores over previous Word2Vec CNN and rule-based approaches.
Kernelized Capsule Networks
Jun 07, 2019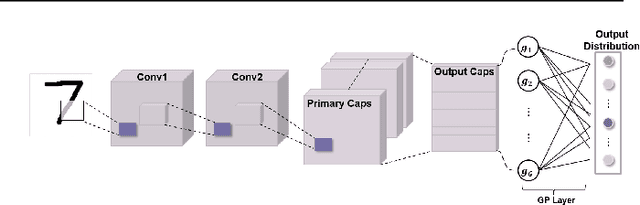
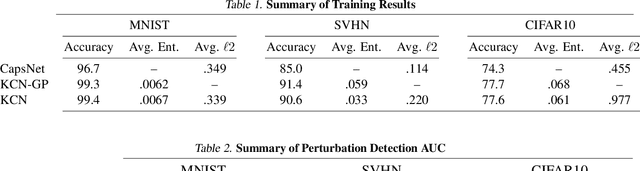
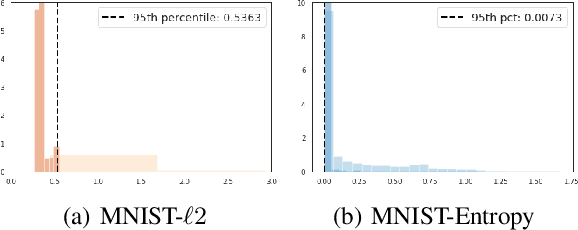
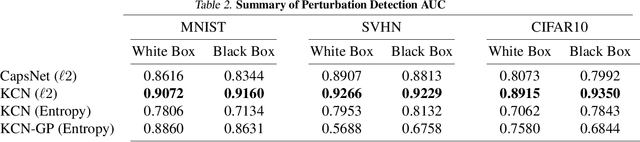
Capsule Networks attempt to represent patterns in images in a way that preserves hierarchical spatial relationships. Additionally, research has demonstrated that these techniques may be robust against adversarial perturbations. We present an improvement to training capsule networks with added robustness via non-parametric kernel methods. The representations learned through the capsule network are used to construct covariance kernels for Gaussian processes (GPs). We demonstrate that this approach achieves comparable prediction performance to Capsule Networks while improving robustness to adversarial perturbations and providing a meaningful measure of uncertainty that may aid in the detection of adversarial inputs.
Interpretable Reinforcement Learning via Differentiable Decision Trees
Mar 22, 2019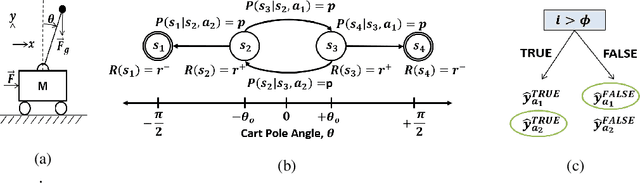

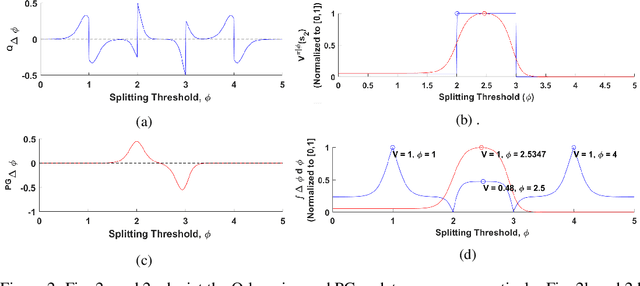

Decision trees are ubiquitous in machine learning for their ease of use and interpretability; however, they are not typically implemented in reinforcement learning because they cannot be updated via stochastic gradient descent. Traditional applications of decision trees for reinforcement learning have focused instead on making commitments to decision boundaries as the tree is grown one layer at a time. We overcome this critical limitation by allowing for a gradient update over the entire tree structure that improves sample complexity when a tree is fuzzy and interpretability when sharp. We offer three key contributions towards this goal. First, we motivate the need for policy gradient-based learning by examining the theoretical properties of gradient descent over differentiable decision trees. Second, we introduce a regularization framework that yields interpretability via sparsity in the tree structure. Third, we demonstrate the ability to construct a decision tree via policy gradient in canonical reinforcement learning domains and supervised learning benchmarks.
Robust and Efficient Transfer Learning with Hidden-Parameter Markov Decision Processes
Oct 31, 2017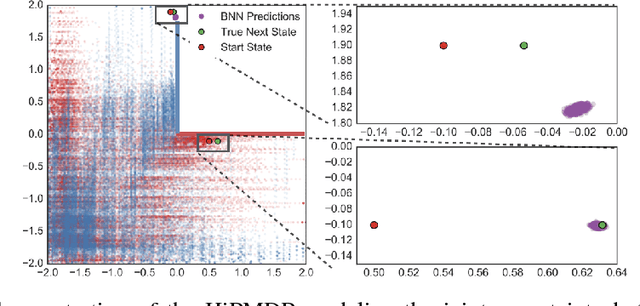
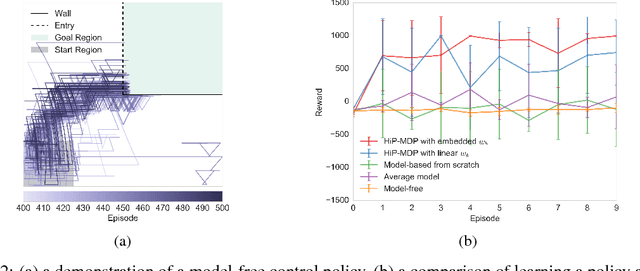
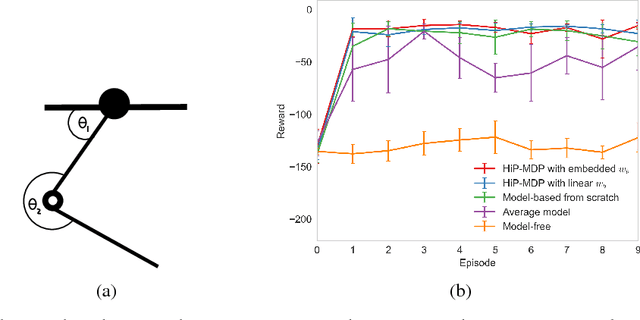
We introduce a new formulation of the Hidden Parameter Markov Decision Process (HiP-MDP), a framework for modeling families of related tasks using low-dimensional latent embeddings. Our new framework correctly models the joint uncertainty in the latent parameters and the state space. We also replace the original Gaussian Process-based model with a Bayesian Neural Network, enabling more scalable inference. Thus, we expand the scope of the HiP-MDP to applications with higher dimensions and more complex dynamics.
Transfer Learning Across Patient Variations with Hidden Parameter Markov Decision Processes
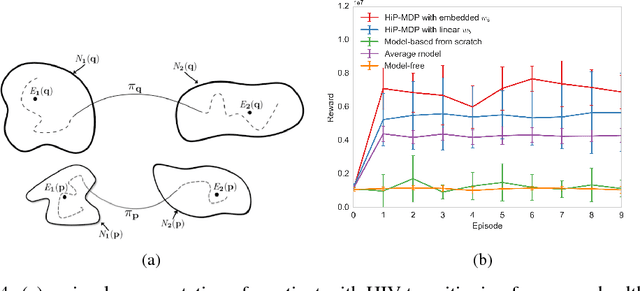
Dec 01, 2016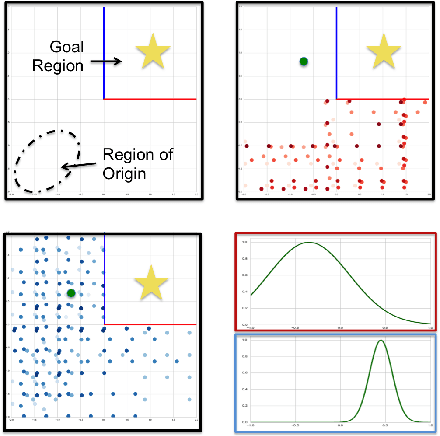
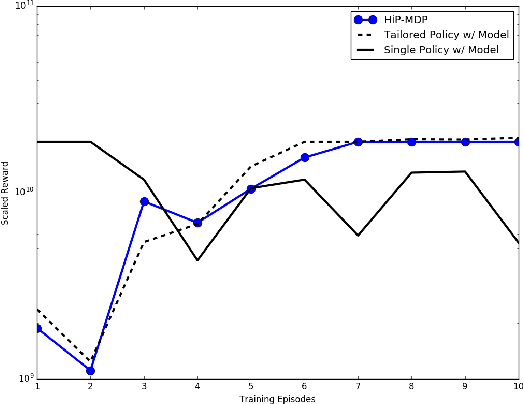
Due to physiological variation, patients diagnosed with the same condition may exhibit divergent, but related, responses to the same treatments. Hidden Parameter Markov Decision Processes (HiP-MDPs) tackle this transfer-learning problem by embedding these tasks into a low-dimensional space. However, the original formulation of HiP-MDP had a critical flaw: the embedding uncertainty was modeled independently of the agent's state uncertainty, requiring an unnatural training procedure in which all tasks visited every part of the state space---possible for robots that can be moved to a particular location, impossible for human patients. We update the HiP-MDP framework and extend it to more robustly develop personalized medicine strategies for HIV treatment.