 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSafe Predictors for Enforcing Input-Output Specifications
Jan 29, 2020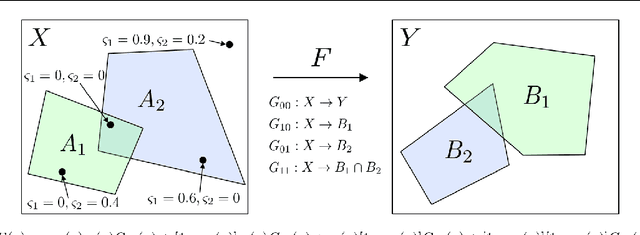


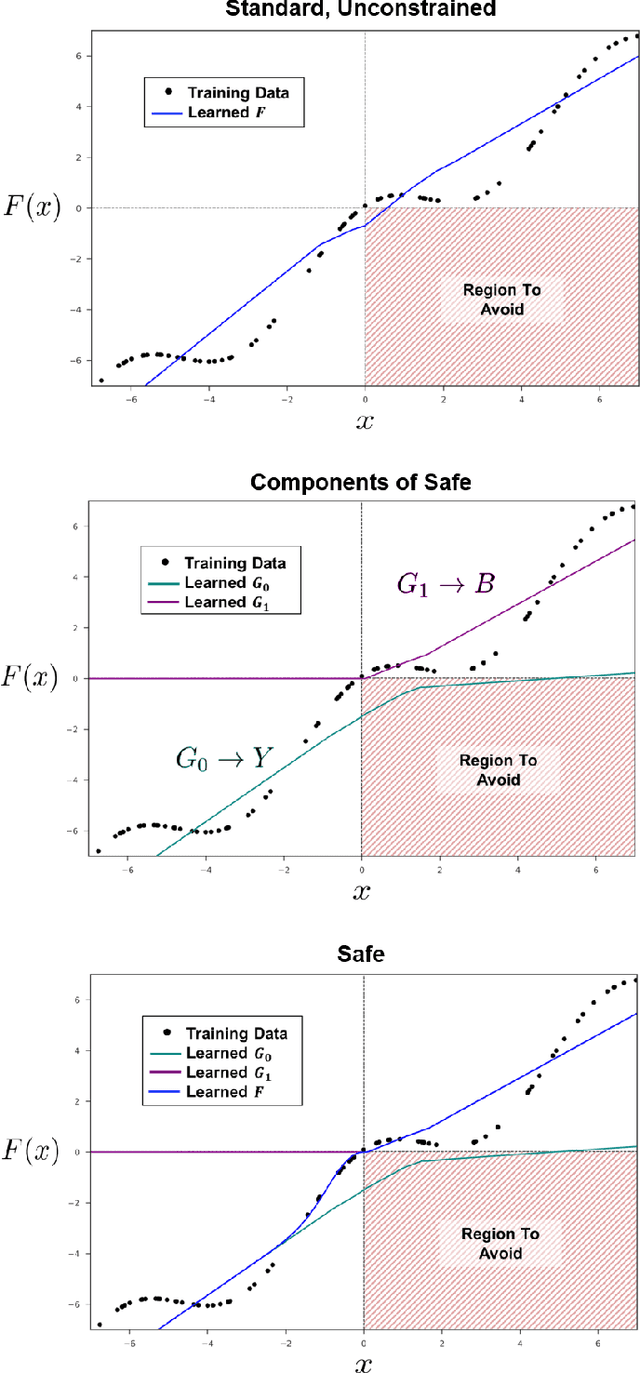
We present an approach for designing correct-by-construction neural networks (and other machine learning models) that are guaranteed to be consistent with a collection of input-output specifications before, during, and after algorithm training. Our method involves designing a constrained predictor for each set of compatible constraints, and combining them safely via a convex combination of their predictions. We demonstrate our approach on synthetic datasets and an aircraft collision avoidance problem.
Kernelized Capsule Networks
Jun 07, 2019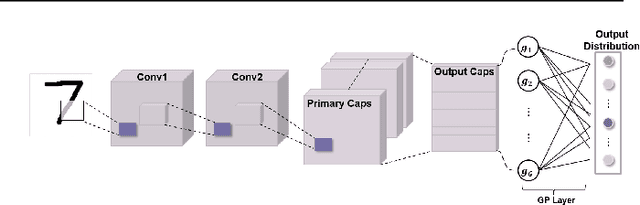
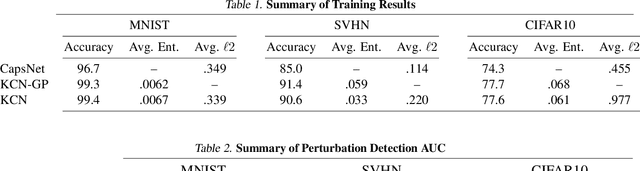
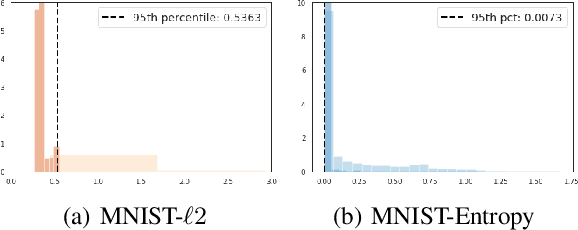
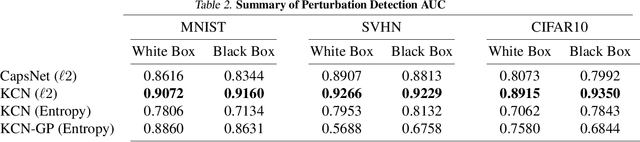
Capsule Networks attempt to represent patterns in images in a way that preserves hierarchical spatial relationships. Additionally, research has demonstrated that these techniques may be robust against adversarial perturbations. We present an improvement to training capsule networks with added robustness via non-parametric kernel methods. The representations learned through the capsule network are used to construct covariance kernels for Gaussian processes (GPs). We demonstrate that this approach achieves comparable prediction performance to Capsule Networks while improving robustness to adversarial perturbations and providing a meaningful measure of uncertainty that may aid in the detection of adversarial inputs.
Interpretable Reinforcement Learning via Differentiable Decision Trees
Mar 22, 2019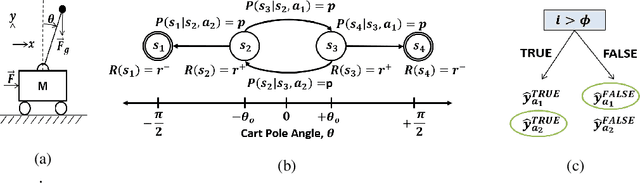

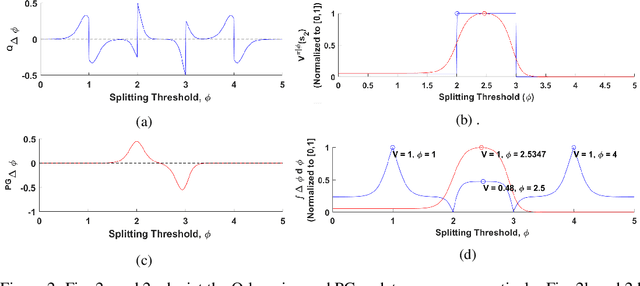

Decision trees are ubiquitous in machine learning for their ease of use and interpretability; however, they are not typically implemented in reinforcement learning because they cannot be updated via stochastic gradient descent. Traditional applications of decision trees for reinforcement learning have focused instead on making commitments to decision boundaries as the tree is grown one layer at a time. We overcome this critical limitation by allowing for a gradient update over the entire tree structure that improves sample complexity when a tree is fuzzy and interpretability when sharp. We offer three key contributions towards this goal. First, we motivate the need for policy gradient-based learning by examining the theoretical properties of gradient descent over differentiable decision trees. Second, we introduce a regularization framework that yields interpretability via sparsity in the tree structure. Third, we demonstrate the ability to construct a decision tree via policy gradient in canonical reinforcement learning domains and supervised learning benchmarks.
Learning Robust Representations for Automatic Target Recognition
Nov 26, 2018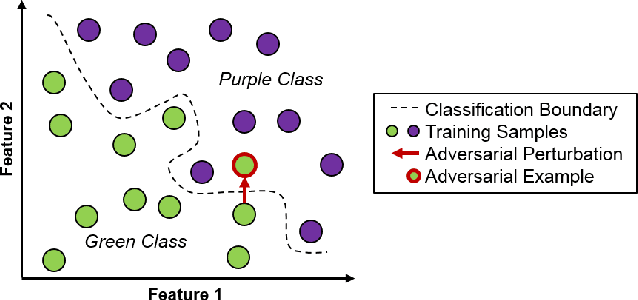
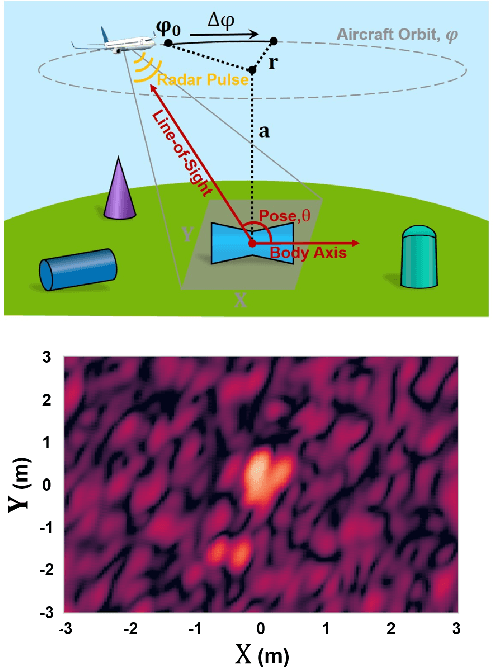

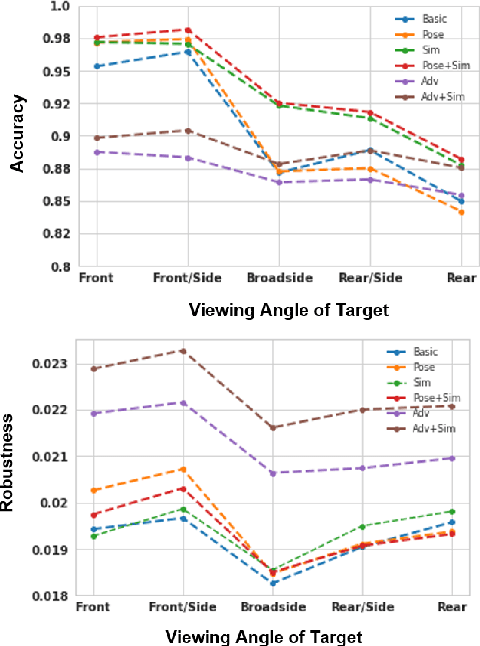
Radio frequency (RF) sensors are used alongside other sensing modalities to provide rich representations of the world. Given the high variability of complex-valued target responses, RF systems are susceptible to attacks masking true target characteristics from accurate identification. In this work, we evaluate different techniques for building robust classification architectures exploiting learned physical structure in received synthetic aperture radar signals of simulated 3D targets.
Human-Machine Collaborative Optimization via Apprenticeship Scheduling
May 11, 2018
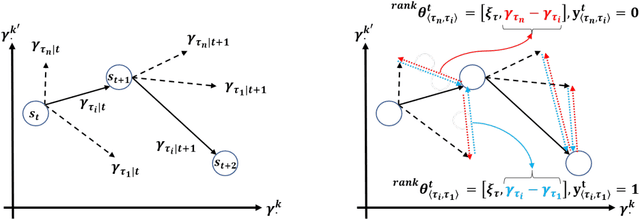

Coordinating agents to complete a set of tasks with intercoupled temporal and resource constraints is computationally challenging, yet human domain experts can solve these difficult scheduling problems using paradigms learned through years of apprenticeship. A process for manually codifying this domain knowledge within a computational framework is necessary to scale beyond the ``single-expert, single-trainee" apprenticeship model. However, human domain experts often have difficulty describing their decision-making processes, causing the codification of this knowledge to become laborious. We propose a new approach for capturing domain-expert heuristics through a pairwise ranking formulation. Our approach is model-free and does not require enumerating or iterating through a large state space. We empirically demonstrate that this approach accurately learns multifaceted heuristics on a synthetic data set incorporating job-shop scheduling and vehicle routing problems, as well as on two real-world data sets consisting of demonstrations of experts solving a weapon-to-target assignment problem and a hospital resource allocation problem. We also demonstrate that policies learned from human scheduling demonstration via apprenticeship learning can substantially improve the efficiency of a branch-and-bound search for an optimal schedule. We employ this human-machine collaborative optimization technique on a variant of the weapon-to-target assignment problem. We demonstrate that this technique generates solutions substantially superior to those produced by human domain experts at a rate up to 9.5 times faster than an optimization approach and can be applied to optimally solve problems twice as complex as those solved by a human demonstrator.