 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-Cycle Spatio-Temporal Adaptation in Human-Robot Teaming
Apr 21, 2026Effective human-robot teaming is crucial for the practical deployment of robots in human workspaces. However, optimizing joint human-robot plans remains a challenge due to the difficulty of modeling individualized human capabilities and preferences. While prior research has leveraged the multi-cycle structure of domains like manufacturing to learn an individual's tendencies and adapt plans over repeated interactions, these techniques typically consider task-level and motion-level adaptation in isolation. Task-level methods optimize allocation and scheduling but often ignore spatial interference in close-proximity scenarios; conversely, motion-level methods focus on collision avoidance while ignoring the broader task context. This paper introduces RAPIDDS, a framework that unifies these approaches by modeling an individual's spatial behavior (motion paths) and temporal behavior (time required to complete tasks) over multiple cycles. RAPIDDS then jointly adapts task schedules and steers diffusion models of robot motions to maximize efficiency and minimize proximity accounting for these individualized models. We demonstrate the importance of this dual adaptation through an ablation study in simulation and a physical robot scenario using a 7-DOF robot arm. Finally, we present a user study (n=32) showing significant plan improvement compared to non-adaptive systems across both objective metrics, such as efficiency and proximity, and subjective measures, including fluency and user preference. See this paper's companion video at: https://youtu.be/55Q3lq1fINs.
Context Matters: Learning Generalizable Rewards via Calibrated Features
Jun 17, 2025A key challenge in reward learning from human input is that desired agent behavior often changes based on context. Traditional methods typically treat each new context as a separate task with its own reward function. For example, if a previously ignored stove becomes too hot to be around, the robot must learn a new reward from scratch, even though the underlying preference for prioritizing safety over efficiency remains unchanged. We observe that context influences not the underlying preference itself, but rather the $\textit{saliency}$--or importance--of reward features. For instance, stove heat affects the importance of the robot's proximity, yet the human's safety preference stays the same. Existing multi-task and meta IRL methods learn context-dependent representations $\textit{implicitly}$--without distinguishing between preferences and feature importance--resulting in substantial data requirements. Instead, we propose $\textit{explicitly}$ modeling context-invariant preferences separately from context-dependent feature saliency, creating modular reward representations that adapt to new contexts. To achieve this, we introduce $\textit{calibrated features}$--representations that capture contextual effects on feature saliency--and present specialized paired comparison queries that isolate saliency from preference for efficient learning. Experiments with simulated users show our method significantly improves sample efficiency, requiring 10x fewer preference queries than baselines to achieve equivalent reward accuracy, with up to 15% better performance in low-data regimes (5-10 queries). An in-person user study (N=12) demonstrates that participants can effectively teach their unique personal contextual preferences using our method, enabling more adaptable and personalized reward learning.
Inference-Time Policy Steering through Human Interactions
Nov 25, 2024



Generative policies trained with human demonstrations can autonomously accomplish multimodal, long-horizon tasks. However, during inference, humans are often removed from the policy execution loop, limiting the ability to guide a pre-trained policy towards a specific sub-goal or trajectory shape among multiple predictions. Naive human intervention may inadvertently exacerbate distribution shift, leading to constraint violations or execution failures. To better align policy output with human intent without inducing out-of-distribution errors, we propose an Inference-Time Policy Steering (ITPS) framework that leverages human interactions to bias the generative sampling process, rather than fine-tuning the policy on interaction data. We evaluate ITPS across three simulated and real-world benchmarks, testing three forms of human interaction and associated alignment distance metrics. Among six sampling strategies, our proposed stochastic sampling with diffusion policy achieves the best trade-off between alignment and distribution shift. Videos are available at https://yanweiw.github.io/itps/.
Versatile Demonstration Interface: Toward More Flexible Robot Demonstration Collection
Oct 24, 2024



Previous methods for Learning from Demonstration leverage several approaches for a human to teach motions to a robot, including teleoperation, kinesthetic teaching, and natural demonstrations. However, little previous work has explored more general interfaces that allow for multiple demonstration types. Given the varied preferences of human demonstrators and task characteristics, a flexible tool that enables multiple demonstration types could be crucial for broader robot skill training. In this work, we propose Versatile Demonstration Interface (VDI), an attachment for collaborative robots that simplifies the collection of three common types of demonstrations. Designed for flexible deployment in industrial settings, our tool requires no additional instrumentation of the environment. Our prototype interface captures human demonstrations through a combination of vision, force sensing, and state tracking (e.g., through the robot proprioception or AprilTag tracking). Through a user study where we deployed our prototype VDI at a local manufacturing innovation center with manufacturing experts, we demonstrated the efficacy of our prototype in representative industrial tasks. Interactions from our study exposed a range of industrial use cases for VDI, clear relationships between demonstration preferences and task criteria, and insights for future tool design.
Grounding Language Plans in Demonstrations Through Counterfactual Perturbations
Mar 25, 2024



Grounding the common-sense reasoning of Large Language Models in physical domains remains a pivotal yet unsolved problem for embodied AI. Whereas prior works have focused on leveraging LLMs directly for planning in symbolic spaces, this work uses LLMs to guide the search of task structures and constraints implicit in multi-step demonstrations. Specifically, we borrow from manipulation planning literature the concept of mode families, which group robot configurations by specific motion constraints, to serve as an abstraction layer between the high-level language representations of an LLM and the low-level physical trajectories of a robot. By replaying a few human demonstrations with synthetic perturbations, we generate coverage over the demonstrations' state space with additional successful executions as well as counterfactuals that fail the task. Our explanation-based learning framework trains an end-to-end differentiable neural network to predict successful trajectories from failures and as a by-product learns classifiers that ground low-level states and images in mode families without dense labeling. The learned grounding classifiers can further be used to translate language plans into reactive policies in the physical domain in an interpretable manner. We show our approach improves the interpretability and reactivity of imitation learning through 2D navigation and simulated and real robot manipulation tasks. Website: https://sites.google.com/view/grounding-plans
Understanding Entrainment in Human Groups: Optimising Human-Robot Collaboration from Lessons Learned during Human-Human Collaboration
Feb 23, 2024



Successful entrainment during collaboration positively affects trust, willingness to collaborate, and likeability towards collaborators. In this paper, we present a mixed-method study to investigate characteristics of successful entrainment leading to pair and group-based synchronisation. Drawing inspiration from industrial settings, we designed a fast-paced, short-cycle repetitive task. Using motion tracking, we investigated entrainment in both dyadic and triadic task completion. Furthermore, we utilise audio-video recordings and semi-structured interviews to contextualise participants' experiences. This paper contributes to the Human-Computer/Robot Interaction (HCI/HRI) literature using a human-centred approach to identify characteristics of entrainment during pair- and group-based collaboration. We present five characteristics related to successful entrainment. These are related to the occurrence of entrainment, leader-follower patterns, interpersonal communication, the importance of the point-of-assembly, and the value of acoustic feedback. Finally, we present three design considerations for future research and design on collaboration with robots.
Human-Guided Complexity-Controlled Abstractions
Oct 27, 2023



Neural networks often learn task-specific latent representations that fail to generalize to novel settings or tasks. Conversely, humans learn discrete representations (i.e., concepts or words) at a variety of abstraction levels (e.g., "bird" vs. "sparrow") and deploy the appropriate abstraction based on task. Inspired by this, we train neural models to generate a spectrum of discrete representations, and control the complexity of the representations (roughly, how many bits are allocated for encoding inputs) by tuning the entropy of the distribution over representations. In finetuning experiments, using only a small number of labeled examples for a new task, we show that (1) tuning the representation to a task-appropriate complexity level supports the highest finetuning performance, and (2) in a human-participant study, users were able to identify the appropriate complexity level for a downstream task using visualizations of discrete representations. Our results indicate a promising direction for rapid model finetuning by leveraging human insight.
An Information Bottleneck Characterization of the Understanding-Workload Tradeoff
Oct 11, 2023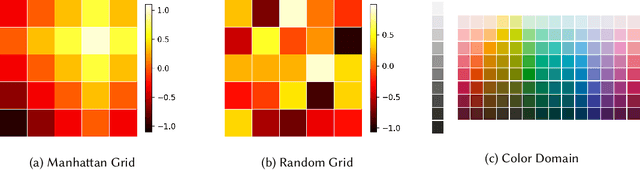
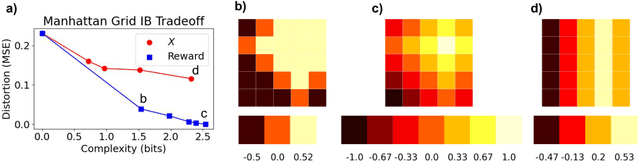
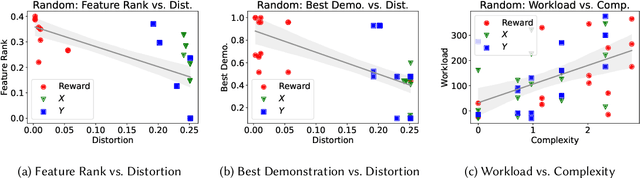
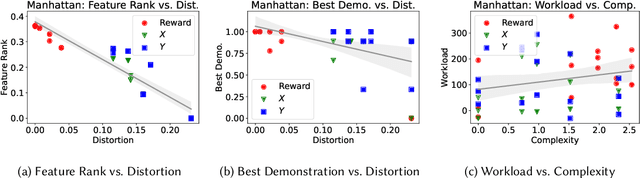
Recent advances in artificial intelligence (AI) have underscored the need for explainable AI (XAI) to support human understanding of AI systems. Consideration of human factors that impact explanation efficacy, such as mental workload and human understanding, is central to effective XAI design. Existing work in XAI has demonstrated a tradeoff between understanding and workload induced by different types of explanations. Explaining complex concepts through abstractions (hand-crafted groupings of related problem features) has been shown to effectively address and balance this workload-understanding tradeoff. In this work, we characterize the workload-understanding balance via the Information Bottleneck method: an information-theoretic approach which automatically generates abstractions that maximize informativeness and minimize complexity. In particular, we establish empirical connections between workload and complexity and between understanding and informativeness through human-subject experiments. This empirical link between human factors and information-theoretic concepts provides an important mathematical characterization of the workload-understanding tradeoff which enables user-tailored XAI design.
Diagnosis, Feedback, Adaptation: A Human-in-the-Loop Framework for Test-Time Policy Adaptation
Jul 13, 2023



Policies often fail due to distribution shift -- changes in the state and reward that occur when a policy is deployed in new environments. Data augmentation can increase robustness by making the model invariant to task-irrelevant changes in the agent's observation. However, designers don't know which concepts are irrelevant a priori, especially when different end users have different preferences about how the task is performed. We propose an interactive framework to leverage feedback directly from the user to identify personalized task-irrelevant concepts. Our key idea is to generate counterfactual demonstrations that allow users to quickly identify possible task-relevant and irrelevant concepts. The knowledge of task-irrelevant concepts is then used to perform data augmentation and thus obtain a policy adapted to personalized user objectives. We present experiments validating our framework on discrete and continuous control tasks with real human users. Our method (1) enables users to better understand agent failure, (2) reduces the number of demonstrations required for fine-tuning, and (3) aligns the agent to individual user task preferences.
Towards Collaborative Plan Acquisition through Theory of Mind Modeling in Situated Dialogue
May 18, 2023



Collaborative tasks often begin with partial task knowledge and incomplete initial plans from each partner. To complete these tasks, agents need to engage in situated communication with their partners and coordinate their partial plans towards a complete plan to achieve a joint task goal. While such collaboration seems effortless in a human-human team, it is highly challenging for human-AI collaboration. To address this limitation, this paper takes a step towards collaborative plan acquisition, where humans and agents strive to learn and communicate with each other to acquire a complete plan for joint tasks. Specifically, we formulate a novel problem for agents to predict the missing task knowledge for themselves and for their partners based on rich perceptual and dialogue history. We extend a situated dialogue benchmark for symmetric collaborative tasks in a 3D blocks world and investigate computational strategies for plan acquisition. Our empirical results suggest that predicting the partner's missing knowledge is a more viable approach than predicting one's own. We show that explicit modeling of the partner's dialogue moves and mental states produces improved and more stable results than without. These results provide insight for future AI agents that can predict what knowledge their partner is missing and, therefore, can proactively communicate such information to help their partner acquire such missing knowledge toward a common understanding of joint tasks.