 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning to Assist: Collaborative VLAs for Implicit Human-Robot Collaboration
Jun 10, 2026Human-robot collaboration (HRC) combines the complementary strengths of humans and robots to improve task efficiency. However, many existing collaborative systems rely on hand-engineered pipelines, limiting their scalability and flexibility for new tasks. In this work, we show that models trained end-to-end with imitation learning, specifically vision-language-action (VLA) models, can support collaborative manipulation, and characterize the key factors affecting their real-world performance. We evaluate two state-of-the-art models and identify a failure mode of action-chunking policies in implicit HRC, where demonstration action leakage (i.e., action chunks crossing latent task transitions) can cause premature assistive behavior. We find that this issue increases with longer execution horizons and occurs in real-world collaborative VLA systems, such as when a robot attempts to hand over a tool before the person is ready. We propose an inference-time steering method to mitigate these erroneous assistive actions while preserving policy performance. Finally, through a 16-participant user study on a long-horizon collaborative assembly task, we show that steering enables a longer execution horizon while mitigating premature assistance, leading to faster collaboration and fewer failures compared to a shorter-horizon policy.
Hide-and-Seek in Trajectories: Discovering Failure Signals for VLA Runtime Monitoring
May 29, 2026Vision-Language-Action (VLA) models enable robots to follow natural language instructions and generalize across diverse tasks, but they remain vulnerable to execution failures that compromise reliability in real-world deployment. Detecting such failures during execution is therefore critical for the robust deployment of embodied systems. Existing failure detection methods either rely on expensive action resampling or external models, while alternatives propagate trajectory-level labels uniformly across every timestep, obscuring localized failure signals. In this paper, we propose \textbf{Hide-and-Seek}, a framework that formulates VLA failure detection as a coarsely supervised learning problem. By combining inter-trajectory and intra-trajectory contrastive objectives, Hide-and-Seek localizes failure-indicative actions and induces temporally structured failure signals from trajectory-level supervision alone, without any step-level annotation. We evaluate Hide-and-Seek on LIBERO, VLABench, and a real-world robotic platform across three representative VLA policies: OpenVLA, $π_0$, and $π_{0.5}$.Our method achieves state-of-the-art multi-task failure detection performance with a practical accuracy--timeliness trade-off under conformal prediction, and generalizes well to both seen and unseen tasks.
Multi-Cycle Spatio-Temporal Adaptation in Human-Robot Teaming
Apr 21, 2026Effective human-robot teaming is crucial for the practical deployment of robots in human workspaces. However, optimizing joint human-robot plans remains a challenge due to the difficulty of modeling individualized human capabilities and preferences. While prior research has leveraged the multi-cycle structure of domains like manufacturing to learn an individual's tendencies and adapt plans over repeated interactions, these techniques typically consider task-level and motion-level adaptation in isolation. Task-level methods optimize allocation and scheduling but often ignore spatial interference in close-proximity scenarios; conversely, motion-level methods focus on collision avoidance while ignoring the broader task context. This paper introduces RAPIDDS, a framework that unifies these approaches by modeling an individual's spatial behavior (motion paths) and temporal behavior (time required to complete tasks) over multiple cycles. RAPIDDS then jointly adapts task schedules and steers diffusion models of robot motions to maximize efficiency and minimize proximity accounting for these individualized models. We demonstrate the importance of this dual adaptation through an ablation study in simulation and a physical robot scenario using a 7-DOF robot arm. Finally, we present a user study (n=32) showing significant plan improvement compared to non-adaptive systems across both objective metrics, such as efficiency and proximity, and subjective measures, including fluency and user preference. See this paper's companion video at: https://youtu.be/55Q3lq1fINs.
REALM: Real-Time Estimates of Assistance for Learned Models in Human-Robot Interaction
Apr 12, 2025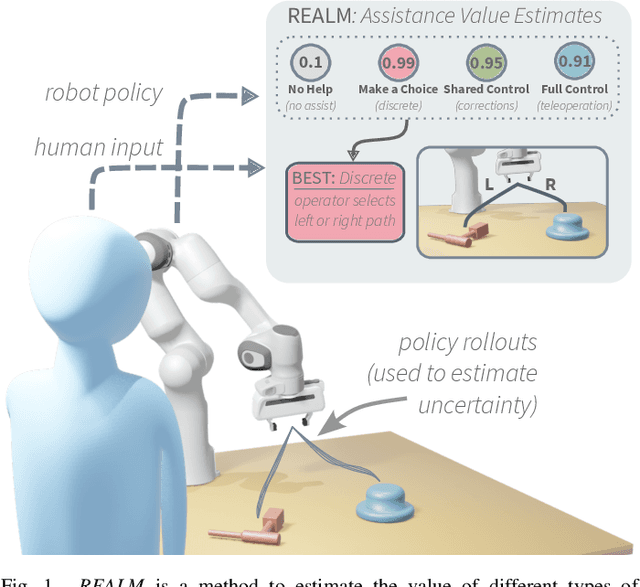


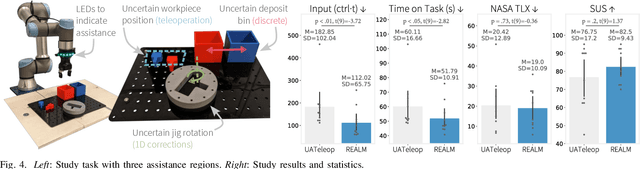
There are a variety of mechanisms (i.e., input types) for real-time human interaction that can facilitate effective human-robot teaming. For example, previous works have shown how teleoperation, corrective, and discrete (i.e., preference over a small number of choices) input can enable robots to complete complex tasks. However, few previous works have looked at combining different methods, and in particular, opportunities for a robot to estimate and elicit the most effective form of assistance given its understanding of a task. In this paper, we propose a method for estimating the value of different human assistance mechanisms based on the action uncertainty of a robot policy. Our key idea is to construct mathematical expressions for the expected post-interaction differential entropy (i.e., uncertainty) of a stochastic robot policy to compare the expected value of different interactions. As each type of human input imposes a different requirement for human involvement, we demonstrate how differential entropy estimates can be combined with a likelihood penalization approach to effectively balance feedback informational needs with the level of required input. We demonstrate evidence of how our approach interfaces with emergent learning models (e.g., a diffusion model) to produce accurate assistance value estimates through both simulation and a robot user study. Our user study results indicate that the proposed approach can enable task completion with minimal human feedback for uncertain robot behaviors.
Versatile Demonstration Interface: Toward More Flexible Robot Demonstration Collection
Oct 24, 2024



Previous methods for Learning from Demonstration leverage several approaches for a human to teach motions to a robot, including teleoperation, kinesthetic teaching, and natural demonstrations. However, little previous work has explored more general interfaces that allow for multiple demonstration types. Given the varied preferences of human demonstrators and task characteristics, a flexible tool that enables multiple demonstration types could be crucial for broader robot skill training. In this work, we propose Versatile Demonstration Interface (VDI), an attachment for collaborative robots that simplifies the collection of three common types of demonstrations. Designed for flexible deployment in industrial settings, our tool requires no additional instrumentation of the environment. Our prototype interface captures human demonstrations through a combination of vision, force sensing, and state tracking (e.g., through the robot proprioception or AprilTag tracking). Through a user study where we deployed our prototype VDI at a local manufacturing innovation center with manufacturing experts, we demonstrated the efficacy of our prototype in representative industrial tasks. Interactions from our study exposed a range of industrial use cases for VDI, clear relationships between demonstration preferences and task criteria, and insights for future tool design.
GeoSACS: Geometric Shared Autonomy via Canal Surfaces
Apr 15, 2024We introduce GeoSACS, a geometric framework for shared autonomy (SA). In variable environments, SA methods can be used to combine robotic capabilities with real-time human input in a way that offloads the physical task from the human. To remain intuitive, it can be helpful to simplify requirements for human input (i.e., reduce the dimensionality), which create challenges for to map low-dimensional human inputs to the higher dimensional control space of robots without requiring large amounts of data. We built GeoSACS on canal surfaces, a geometric framework that represents potential robot trajectories as a canal from as few as two demonstrations. GeoSACS maps user corrections on the cross-sections of this canal to provide an efficient SA framework. We extend canal surfaces to consider orientation and update the control frames to support intuitive mapping from user input to robot motions. Finally, we demonstrate GeoSACS in two preliminary studies, including a complex manipulation task where a robot loads laundry into a washer.
Grounding Language Plans in Demonstrations Through Counterfactual Perturbations
Mar 25, 2024



Grounding the common-sense reasoning of Large Language Models in physical domains remains a pivotal yet unsolved problem for embodied AI. Whereas prior works have focused on leveraging LLMs directly for planning in symbolic spaces, this work uses LLMs to guide the search of task structures and constraints implicit in multi-step demonstrations. Specifically, we borrow from manipulation planning literature the concept of mode families, which group robot configurations by specific motion constraints, to serve as an abstraction layer between the high-level language representations of an LLM and the low-level physical trajectories of a robot. By replaying a few human demonstrations with synthetic perturbations, we generate coverage over the demonstrations' state space with additional successful executions as well as counterfactuals that fail the task. Our explanation-based learning framework trains an end-to-end differentiable neural network to predict successful trajectories from failures and as a by-product learns classifiers that ground low-level states and images in mode families without dense labeling. The learned grounding classifiers can further be used to translate language plans into reactive policies in the physical domain in an interpretable manner. We show our approach improves the interpretability and reactivity of imitation learning through 2D navigation and simulated and real robot manipulation tasks. Website: https://sites.google.com/view/grounding-plans
A System for Human-Robot Teaming through End-User Programming and Shared Autonomy
Jan 22, 2024



Many industrial tasks-such as sanding, installing fasteners, and wire harnessing-are difficult to automate due to task complexity and variability. We instead investigate deploying robots in an assistive role for these tasks, where the robot assumes the physical task burden and the skilled worker provides both the high-level task planning and low-level feedback necessary to effectively complete the task. In this article, we describe the development of a system for flexible human-robot teaming that combines state-of-the-art methods in end-user programming and shared autonomy and its implementation in sanding applications. We demonstrate the use of the system in two types of sanding tasks, situated in aircraft manufacturing, that highlight two potential workflows within the human-robot teaming setup. We conclude by discussing challenges and opportunities in human-robot teaming identified during the development, application, and demonstration of our system.
Handheld Haptic Device with Coupled Bidirectional Input
May 30, 2023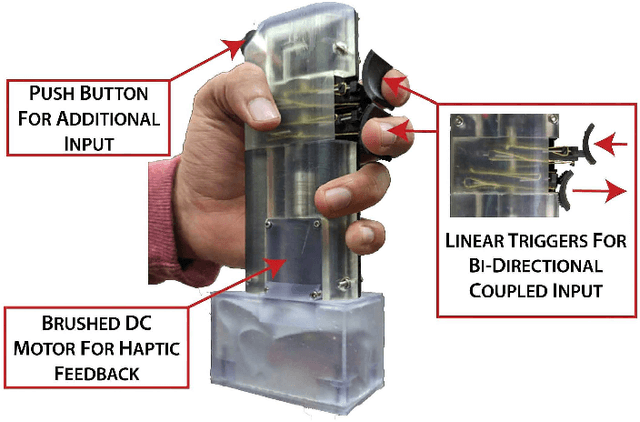
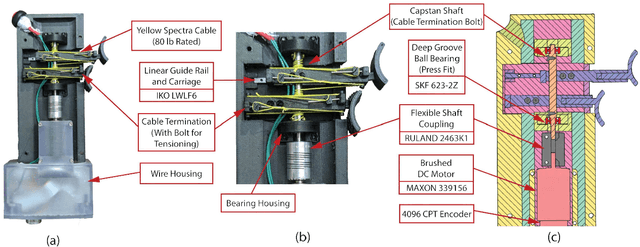
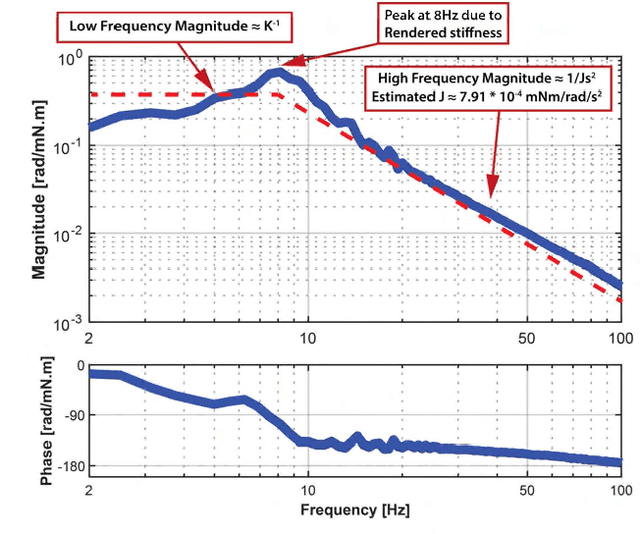

Handheld kinesthetic haptic interfaces can provide greater mobility and richer tactile information as compared to traditional grounded devices. In this paper, we introduce a new handheld haptic interface which takes input using bidirectional coupled finger flexion. We present the device design motivation and design details and experimentally evaluate its performance in terms of transparency and rendering bandwidth using a handheld prototype device. In addition, we assess the device's functional performance through a user study comparing the proposed device to a commonly used grounded input device in a set of targeting and tracking tasks.
Coordinated Multi-Robot Shared Autonomy Based on Scheduling and Demonstrations
Mar 28, 2023Shared autonomy methods, where a human operator and a robot arm work together, have enabled robots to complete a range of complex and highly variable tasks. Existing work primarily focuses on one human sharing autonomy with a single robot. By contrast, in this paper we present an approach for multi-robot shared autonomy that enables one operator to provide real-time corrections across two coordinated robots completing the same task in parallel. Sharing autonomy with multiple robots presents fundamental challenges. The human can only correct one robot at a time, and without coordination, the human may be left idle for long periods of time. Accordingly, we develop an approach that aligns the robot's learned motions to best utilize the human's expertise. Our key idea is to leverage Learning from Demonstration (LfD) and time warping to schedule the motions of the robots based on when they may require assistance. Our method uses variability in operator demonstrations to identify the types of corrections an operator might apply during shared autonomy, leverages flexibility in how quickly the task was performed in demonstrations to aid in scheduling, and iteratively estimates the likelihood of when corrections may be needed to ensure that only one robot is completing an action requiring assistance. Through a preliminary simulated study, we show that our method can decrease the overall time spent sanding by iteratively estimating the times when each robot could need assistance and generating an optimized schedule that allows the operator to provide corrections to each robot during these times.