 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHDDLGym: A Tool for Studying Multi-Agent Hierarchical Problems Defined in HDDL with OpenAI Gym
May 28, 2025In recent years, reinforcement learning (RL) methods have been widely tested using tools like OpenAI Gym, though many tasks in these environments could also benefit from hierarchical planning. However, there is a lack of a tool that enables seamless integration of hierarchical planning with RL. Hierarchical Domain Definition Language (HDDL), used in classical planning, introduces a structured approach well-suited for model-based RL to address this gap. To bridge this integration, we introduce HDDLGym, a Python-based tool that automatically generates OpenAI Gym environments from HDDL domains and problems. HDDLGym serves as a link between RL and hierarchical planning, supporting multi-agent scenarios and enabling collaborative planning among agents. This paper provides an overview of HDDLGym's design and implementation, highlighting the challenges and design choices involved in integrating HDDL with the Gym interface, and applying RL policies to support hierarchical planning. We also provide detailed instructions and demonstrations for using the HDDLGym framework, including how to work with existing HDDL domains and problems from International Planning Competitions, exemplified by the Transport domain. Additionally, we offer guidance on creating new HDDL domains for multi-agent scenarios and demonstrate the practical use of HDDLGym in the Overcooked domain. By leveraging the advantages of HDDL and Gym, HDDLGym aims to be a valuable tool for studying RL in hierarchical planning, particularly in multi-agent contexts.
REALM: Real-Time Estimates of Assistance for Learned Models in Human-Robot Interaction
Apr 12, 2025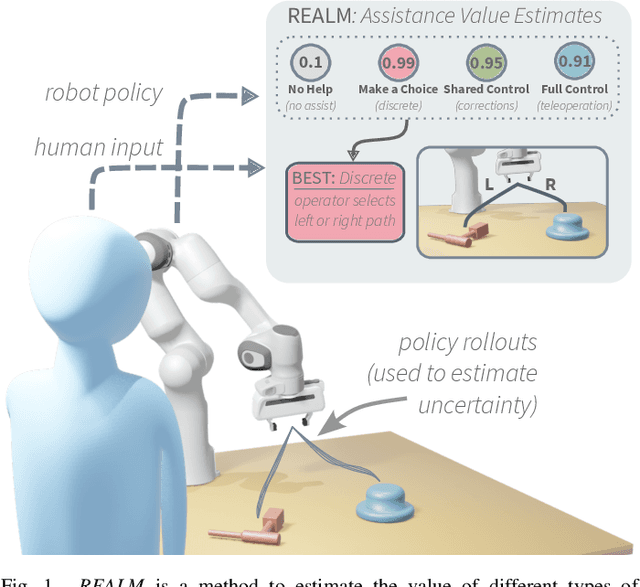


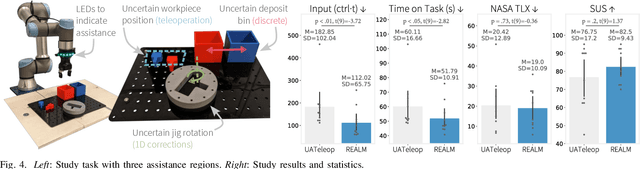
There are a variety of mechanisms (i.e., input types) for real-time human interaction that can facilitate effective human-robot teaming. For example, previous works have shown how teleoperation, corrective, and discrete (i.e., preference over a small number of choices) input can enable robots to complete complex tasks. However, few previous works have looked at combining different methods, and in particular, opportunities for a robot to estimate and elicit the most effective form of assistance given its understanding of a task. In this paper, we propose a method for estimating the value of different human assistance mechanisms based on the action uncertainty of a robot policy. Our key idea is to construct mathematical expressions for the expected post-interaction differential entropy (i.e., uncertainty) of a stochastic robot policy to compare the expected value of different interactions. As each type of human input imposes a different requirement for human involvement, we demonstrate how differential entropy estimates can be combined with a likelihood penalization approach to effectively balance feedback informational needs with the level of required input. We demonstrate evidence of how our approach interfaces with emergent learning models (e.g., a diffusion model) to produce accurate assistance value estimates through both simulation and a robot user study. Our user study results indicate that the proposed approach can enable task completion with minimal human feedback for uncertain robot behaviors.
Regulation of Language Models With Interpretability Will Likely Result In A Performance Trade-Off
Dec 12, 2024Regulation is increasingly cited as the most important and pressing concern in machine learning. However, it is currently unknown how to implement this, and perhaps more importantly, how it would effect model performance alongside human collaboration if actually realized. In this paper, we attempt to answer these questions by building a regulatable large-language model (LLM), and then quantifying how the additional constraints involved affect (1) model performance, alongside (2) human collaboration. Our empirical results reveal that it is possible to force an LLM to use human-defined features in a transparent way, but a "regulation performance trade-off" previously not considered reveals itself in the form of a 7.34% classification performance drop. Surprisingly however, we show that despite this, such systems actually improve human task performance speed and appropriate confidence in a realistic deployment setting compared to no AI assistance, thus paving a way for fair, regulatable AI, which benefits users.
Explainable deep learning improves human mental models of self-driving cars
Nov 27, 2024Self-driving cars increasingly rely on deep neural networks to achieve human-like driving. However, the opacity of such black-box motion planners makes it challenging for the human behind the wheel to accurately anticipate when they will fail, with potentially catastrophic consequences. Here, we introduce concept-wrapper network (i.e., CW-Net), a method for explaining the behavior of black-box motion planners by grounding their reasoning in human-interpretable concepts. We deploy CW-Net on a real self-driving car and show that the resulting explanations refine the human driver's mental model of the car, allowing them to better predict its behavior and adjust their own behavior accordingly. Unlike previous work using toy domains or simulations, our study presents the first real-world demonstration of how to build authentic autonomous vehicles (AVs) that give interpretable, causally faithful explanations for their decisions, without sacrificing performance. We anticipate our method could be applied to other safety-critical systems with a human in the loop, such as autonomous drones and robotic surgeons. Overall, our study suggests a pathway to explainability for autonomous agents as a whole, which can help make them more transparent, their deployment safer, and their usage more ethical.
Automation from the Worker's Perspective
Sep 30, 2024
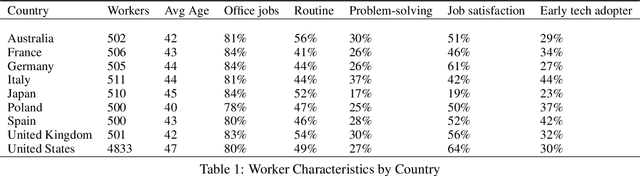
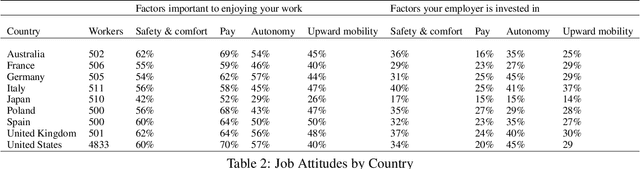
Common narratives about automation often pit new technologies against workers. The introduction of advanced machine tools, industrial robots, and AI have all been met with concern that technological progress will mean fewer jobs. However, workers themselves offer a more optimistic, nuanced perspective. Drawing on a far-reaching 2024 survey of more than 9,000 workers across nine countries, this paper finds that more workers report potential benefits from new technologies like robots and AI for their safety and comfort at work, their pay, and their autonomy on the job than report potential costs. Workers with jobs that ask them to solve complex problems, workers who feel valued by their employers, and workers who are motivated to move up in their careers are all more likely to see new technologies as beneficial. In contrast to assumptions in previous research, more formal education is in some cases associated with more negative attitudes toward automation and its impact on work. In an experimental setting, the prospect of financial incentives for workers improve their perceptions of automation technologies, whereas the prospect of increased input about how new technologies are used does not have a significant effect on workers' attitudes toward automation.
Adaptive Language-Guided Abstraction from Contrastive Explanations
Sep 12, 2024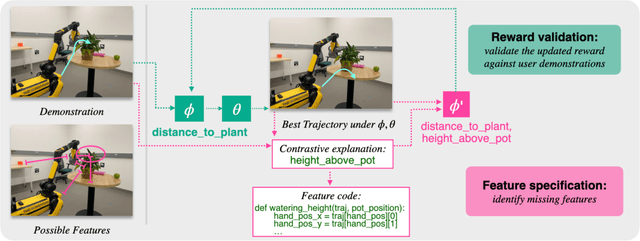
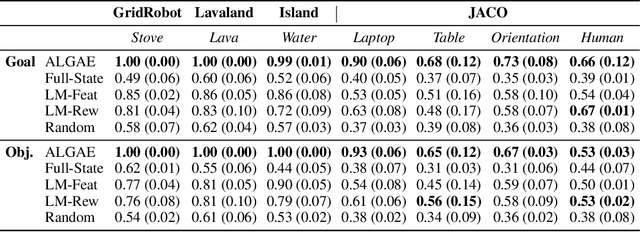

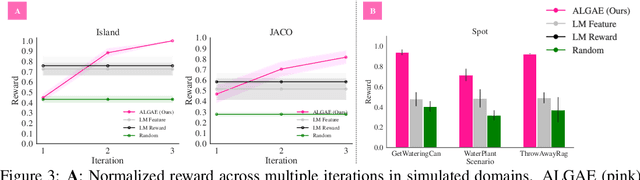
Many approaches to robot learning begin by inferring a reward function from a set of human demonstrations. To learn a good reward, it is necessary to determine which features of the environment are relevant before determining how these features should be used to compute reward. End-to-end methods for joint feature and reward learning (e.g., using deep networks or program synthesis techniques) often yield brittle reward functions that are sensitive to spurious state features. By contrast, humans can often generalizably learn from a small number of demonstrations by incorporating strong priors about what features of a demonstration are likely meaningful for a task of interest. How do we build robots that leverage this kind of background knowledge when learning from new demonstrations? This paper describes a method named ALGAE (Adaptive Language-Guided Abstraction from [Contrastive] Explanations) which alternates between using language models to iteratively identify human-meaningful features needed to explain demonstrated behavior, then standard inverse reinforcement learning techniques to assign weights to these features. Experiments across a variety of both simulated and real-world robot environments show that ALGAE learns generalizable reward functions defined on interpretable features using only small numbers of demonstrations. Importantly, ALGAE can recognize when features are missing, then extract and define those features without any human input -- making it possible to quickly and efficiently acquire rich representations of user behavior.
Enhancing Preference-based Linear Bandits via Human Response Time
Sep 09, 2024Binary human choice feedback is widely used in interactive preference learning for its simplicity, but it provides limited information about preference strength. To overcome this limitation, we leverage human response times, which inversely correlate with preference strength, as complementary information. Our work integrates the EZ-diffusion model, which jointly models human choices and response times, into preference-based linear bandits. We introduce a computationally efficient utility estimator that reformulates the utility estimation problem using both choices and response times as a linear regression problem. Theoretical and empirical comparisons with traditional choice-only estimators reveal that for queries with strong preferences ("easy" queries), choices alone provide limited information, while response times offer valuable complementary information about preference strength. As a result, incorporating response times makes easy queries more useful. We demonstrate this advantage in the fixed-budget best-arm identification problem, with simulations based on three real-world datasets, consistently showing accelerated learning when response times are incorporated.
Object Permanence Filter for Robust Tracking with Interactive Robots
Mar 13, 2024



Object permanence, which refers to the concept that objects continue to exist even when they are no longer perceivable through the senses, is a crucial aspect of human cognitive development. In this work, we seek to incorporate this understanding into interactive robots by proposing a set of assumptions and rules to represent object permanence in multi-object, multi-agent interactive scenarios. We integrate these rules into the particle filter, resulting in the Object Permanence Filter (OPF). For multi-object scenarios, we propose an ensemble of K interconnected OPFs, where each filter predicts plausible object tracks that are resilient to missing, noisy, and kinematically or dynamically infeasible measurements, thus bringing perceptional robustness. Through several interactive scenarios, we demonstrate that the proposed OPF approach provides robust tracking in human-robot interactive tasks agnostic to measurement type, even in the presence of prolonged and complete occlusion. Webpage: https://opfilter.github.io/.
Learning with Language-Guided State Abstractions
Mar 06, 2024We describe a framework for using natural language to design state abstractions for imitation learning. Generalizable policy learning in high-dimensional observation spaces is facilitated by well-designed state representations, which can surface important features of an environment and hide irrelevant ones. These state representations are typically manually specified, or derived from other labor-intensive labeling procedures. Our method, LGA (language-guided abstraction), uses a combination of natural language supervision and background knowledge from language models (LMs) to automatically build state representations tailored to unseen tasks. In LGA, a user first provides a (possibly incomplete) description of a target task in natural language; next, a pre-trained LM translates this task description into a state abstraction function that masks out irrelevant features; finally, an imitation policy is trained using a small number of demonstrations and LGA-generated abstract states. Experiments on simulated robotic tasks show that LGA yields state abstractions similar to those designed by humans, but in a fraction of the time, and that these abstractions improve generalization and robustness in the presence of spurious correlations and ambiguous specifications. We illustrate the utility of the learned abstractions on mobile manipulation tasks with a Spot robot.
Preference-Conditioned Language-Guided Abstraction
Feb 05, 2024



Learning from demonstrations is a common way for users to teach robots, but it is prone to spurious feature correlations. Recent work constructs state abstractions, i.e. visual representations containing task-relevant features, from language as a way to perform more generalizable learning. However, these abstractions also depend on a user's preference for what matters in a task, which may be hard to describe or infeasible to exhaustively specify using language alone. How do we construct abstractions to capture these latent preferences? We observe that how humans behave reveals how they see the world. Our key insight is that changes in human behavior inform us that there are differences in preferences for how humans see the world, i.e. their state abstractions. In this work, we propose using language models (LMs) to query for those preferences directly given knowledge that a change in behavior has occurred. In our framework, we use the LM in two ways: first, given a text description of the task and knowledge of behavioral change between states, we query the LM for possible hidden preferences; second, given the most likely preference, we query the LM to construct the state abstraction. In this framework, the LM is also able to ask the human directly when uncertain about its own estimate. We demonstrate our framework's ability to construct effective preference-conditioned abstractions in simulated experiments, a user study, as well as on a real Spot robot performing mobile manipulation tasks.