 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Hierarchical and Geometry-Aware Graph Representations for Text-to-CAD
Apr 11, 2026Text-to-CAD code generation is a long-horizon task that translates textual instructions into long sequences of interdependent operations. Existing methods typically decode text directly into executable code (e.g., bpy) without explicitly modeling assembly hierarchy or geometric constraints, which enlarges the search space, accumulates local errors, and often causes cascading failures in complex assemblies. To address this issue, we propose a hierarchical and geometry-aware graph as an intermediate representation. The graph models multi-level parts and components as nodes and encodes explicit geometric constraints as edges. Instead of mapping text directly to code, our framework first predicts structure and constraints, then conditions action sequencing and code generation, thereby improving geometric fidelity and constraint satisfaction. We further introduce a structure-aware progressive curriculum learning strategy that constructs graded tasks through controlled structural edits, explores the model's capability boundary, and synthesizes boundary examples for iterative training. In addition, we build a 12K dataset with instructions, decomposition graphs, action sequences, and bpy code, together with graph- and constraint-oriented evaluation metrics. Extensive experiments show that our method consistently outperforms existing approaches in both geometric fidelity and accurate satisfaction of geometric constraints.
ThinkDrive: Chain-of-Thought Guided Progressive Reinforcement Learning Fine-Tuning for Autonomous Driving
Jan 08, 2026With the rapid advancement of large language models (LLMs) technologies, their application in the domain of autonomous driving has become increasingly widespread. However, existing methods suffer from unstructured reasoning, poor generalization, and misalignment with human driving intent. While Chain-of-Thought (CoT) reasoning enhances decision transparency, conventional supervised fine-tuning (SFT) fails to fully exploit its potential, and reinforcement learning (RL) approaches face instability and suboptimal reasoning depth. We propose ThinkDrive, a CoT guided progressive RL fine-tuning framework for autonomous driving that synergizes explicit reasoning with difficulty-aware adaptive policy optimization. Our method employs a two-stage training strategy. First, we perform SFT using CoT explanations. Then, we apply progressive RL with a difficulty-aware adaptive policy optimizer that dynamically adjusts learning intensity based on sample complexity. We evaluate our approach on a public dataset. The results show that ThinkDrive outperforms strong RL baselines by 1.45%, 1.95%, and 1.01% on exam, easy-exam, and accuracy, respectively. Moreover, a 2B-parameter model trained with our method surpasses the much larger GPT-4o by 3.28% on the exam metric.
AIVD: Adaptive Edge-Cloud Collaboration for Accurate and Efficient Industrial Visual Detection
Jan 08, 2026Multimodal large language models (MLLMs) demonstrate exceptional capabilities in semantic understanding and visual reasoning, yet they still face challenges in precise object localization and resource-constrained edge-cloud deployment. To address this, this paper proposes the AIVD framework, which achieves unified precise localization and high-quality semantic generation through the collaboration between lightweight edge detectors and cloud-based MLLMs. To enhance the cloud MLLM's robustness against edge cropped-box noise and scenario variations, we design an efficient fine-tuning strategy with visual-semantic collaborative augmentation, significantly improving classification accuracy and semantic consistency. Furthermore, to maintain high throughput and low latency across heterogeneous edge devices and dynamic network conditions, we propose a heterogeneous resource-aware dynamic scheduling algorithm. Experimental results demonstrate that AIVD substantially reduces resource consumption while improving MLLM classification performance and semantic generation quality. The proposed scheduling strategy also achieves higher throughput and lower latency across diverse scenarios.
Order-Level Attention Similarity Across Language Models: A Latent Commonality
Nov 07, 2025
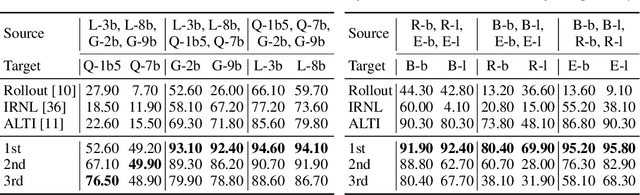


In this paper, we explore an important yet previously neglected question: Do context aggregation patterns across Language Models (LMs) share commonalities? While some works have investigated context aggregation or attention weights in LMs, they typically focus on individual models or attention heads, lacking a systematic analysis across multiple LMs to explore their commonalities. In contrast, we focus on the commonalities among LMs, which can deepen our understanding of LMs and even facilitate cross-model knowledge transfer. In this work, we introduce the Order-Level Attention (OLA) derived from the order-wise decomposition of Attention Rollout and reveal that the OLA at the same order across LMs exhibits significant similarities. Furthermore, we discover an implicit mapping between OLA and syntactic knowledge. Based on these two findings, we propose the Transferable OLA Adapter (TOA), a training-free cross-LM adapter transfer method. Specifically, we treat the OLA as a unified syntactic feature representation and train an adapter that takes OLA as input. Due to the similarities in OLA across LMs, the adapter generalizes to unseen LMs without requiring any parameter updates. Extensive experiments demonstrate that TOA's cross-LM generalization effectively enhances the performance of unseen LMs. Code is available at https://github.com/jinglin-liang/OLAS.
Explainable deep learning improves human mental models of self-driving cars
Nov 27, 2024Self-driving cars increasingly rely on deep neural networks to achieve human-like driving. However, the opacity of such black-box motion planners makes it challenging for the human behind the wheel to accurately anticipate when they will fail, with potentially catastrophic consequences. Here, we introduce concept-wrapper network (i.e., CW-Net), a method for explaining the behavior of black-box motion planners by grounding their reasoning in human-interpretable concepts. We deploy CW-Net on a real self-driving car and show that the resulting explanations refine the human driver's mental model of the car, allowing them to better predict its behavior and adjust their own behavior accordingly. Unlike previous work using toy domains or simulations, our study presents the first real-world demonstration of how to build authentic autonomous vehicles (AVs) that give interpretable, causally faithful explanations for their decisions, without sacrificing performance. We anticipate our method could be applied to other safety-critical systems with a human in the loop, such as autonomous drones and robotic surgeons. Overall, our study suggests a pathway to explainability for autonomous agents as a whole, which can help make them more transparent, their deployment safer, and their usage more ethical.
Task Difficulty Aware Parameter Allocation & Regularization for Lifelong Learning
Apr 11, 2023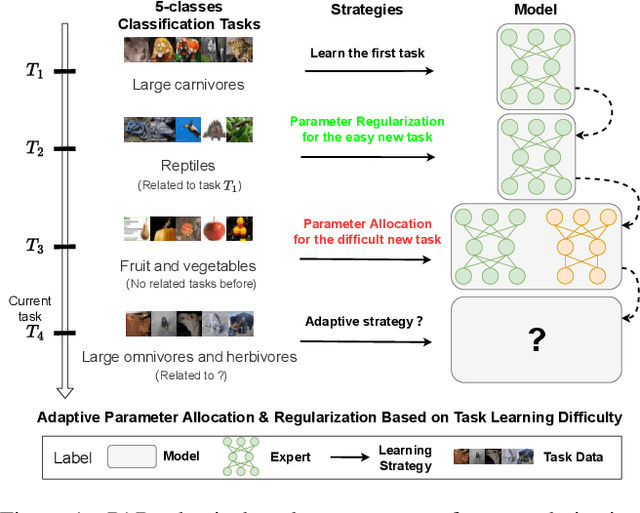
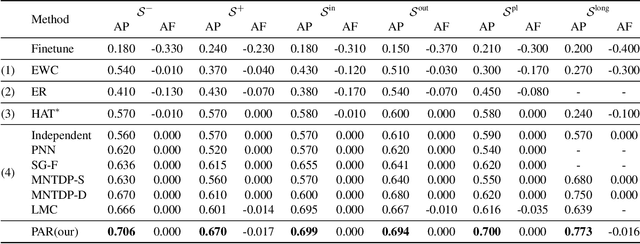
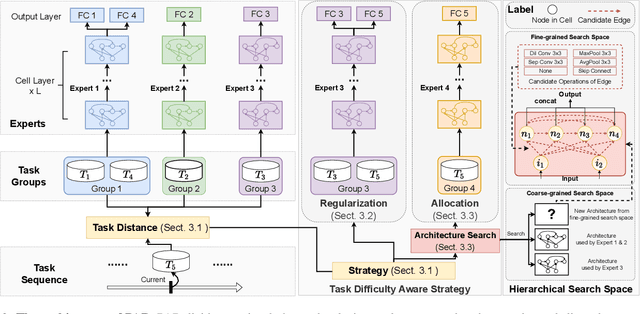

Parameter regularization or allocation methods are effective in overcoming catastrophic forgetting in lifelong learning. However, they solve all tasks in a sequence uniformly and ignore the differences in the learning difficulty of different tasks. So parameter regularization methods face significant forgetting when learning a new task very different from learned tasks, and parameter allocation methods face unnecessary parameter overhead when learning simple tasks. In this paper, we propose the Parameter Allocation & Regularization (PAR), which adaptively select an appropriate strategy for each task from parameter allocation and regularization based on its learning difficulty. A task is easy for a model that has learned tasks related to it and vice versa. We propose a divergence estimation method based on the Nearest-Prototype distance to measure the task relatedness using only features of the new task. Moreover, we propose a time-efficient relatedness-aware sampling-based architecture search strategy to reduce the parameter overhead for allocation. Experimental results on multiple benchmarks demonstrate that, compared with SOTAs, our method is scalable and significantly reduces the model's redundancy while improving the model's performance. Further qualitative analysis indicates that PAR obtains reasonable task-relatedness.
Diverse Instance Discovery: Vision-Transformer for Instance-Aware Multi-Label Image Recognition
Apr 22, 2022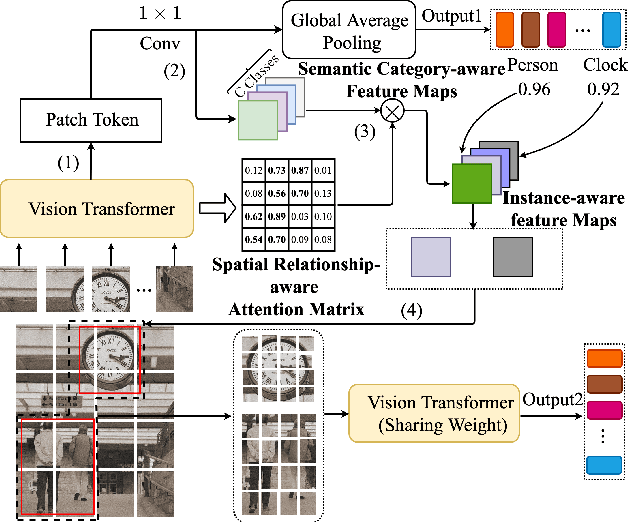
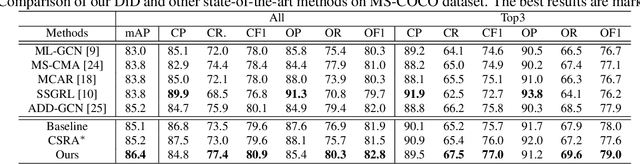
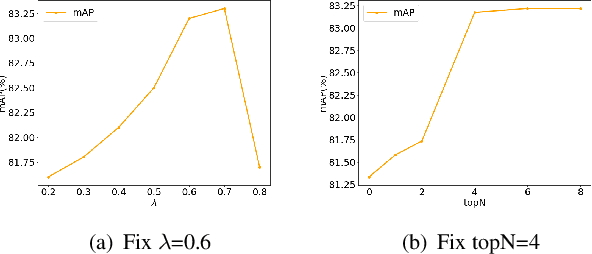
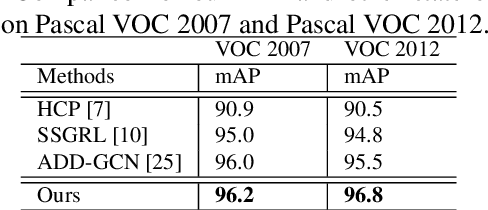
Previous works on multi-label image recognition (MLIR) usually use CNNs as a starting point for research. In this paper, we take pure Vision Transformer (ViT) as the research base and make full use of the advantages of Transformer with long-range dependency modeling to circumvent the disadvantages of CNNs limited to local receptive field. However, for multi-label images containing multiple objects from different categories, scales, and spatial relations, it is not optimal to use global information alone. Our goal is to leverage ViT's patch tokens and self-attention mechanism to mine rich instances in multi-label images, named diverse instance discovery (DiD). To this end, we propose a semantic category-aware module and a spatial relationship-aware module, respectively, and then combine the two by a re-constraint strategy to obtain instance-aware attention maps. Finally, we propose a weakly supervised object localization-based approach to extract multi-scale local features, to form a multi-view pipeline. Our method requires only weakly supervised information at the label level, no additional knowledge injection or other strongly supervised information is required. Experiments on three benchmark datasets show that our method significantly outperforms previous works and achieves state-of-the-art results under fair experimental comparisons.
DRDF: Determining the Importance of Different Multimodal Information with Dual-Router Dynamic Framework
Jul 21, 2021

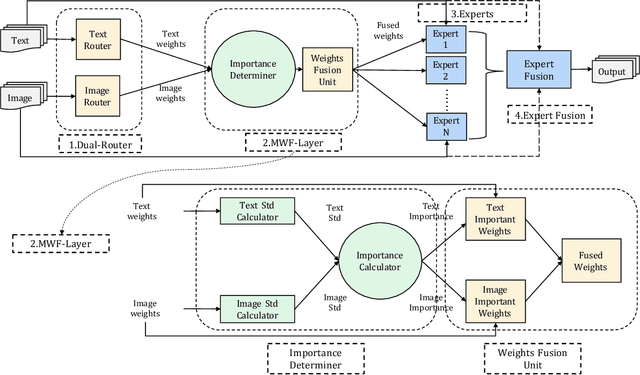
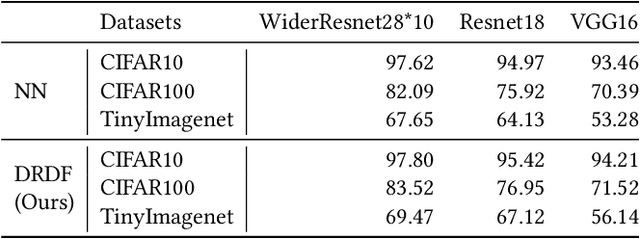
In multimodal tasks, we find that the importance of text and image modal information is different for different input cases, and for this motivation, we propose a high-performance and highly general Dual-Router Dynamic Framework (DRDF), consisting of Dual-Router, MWF-Layer, experts and expert fusion unit. The text router and image router in Dual-Router accept text modal information and image modal information, and use MWF-Layer to determine the importance of modal information. Based on the result of the determination, MWF-Layer generates fused weights for the fusion of experts. Experts are model backbones that match the current task. DRDF has high performance and high generality, and we have tested 12 backbones such as Visual BERT on multimodal dataset Hateful memes, unimodal dataset CIFAR10, CIFAR100, and TinyImagenet. Our DRDF outperforms all the baselines. We also verified the components of DRDF in detail by ablations, compared and discussed the reasons and ideas of DRDF design.
RAMS-Trans: Recurrent Attention Multi-scale Transformer forFine-grained Image Recognition
Jul 17, 2021
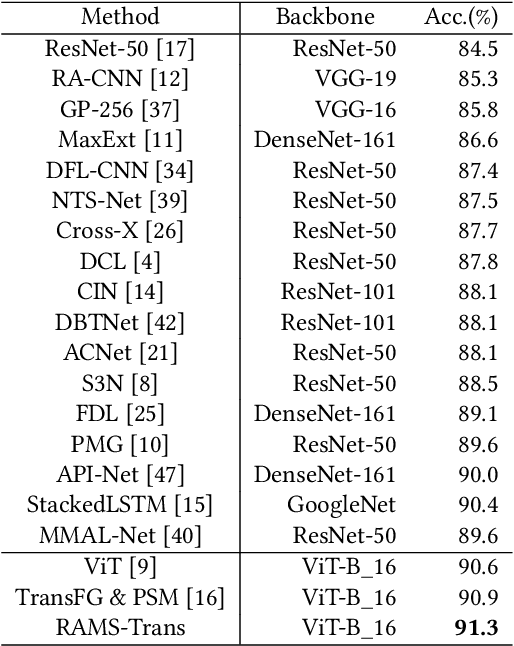
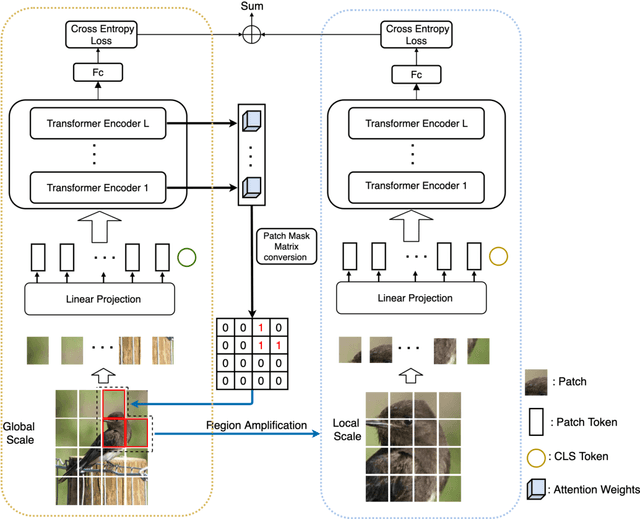
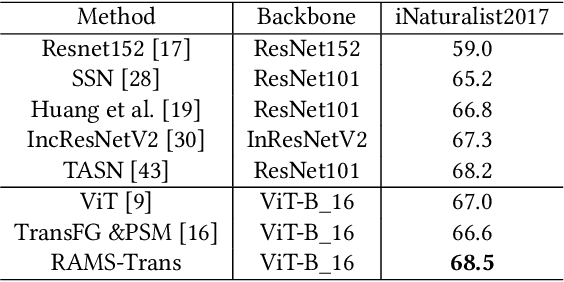
In fine-grained image recognition (FGIR), the localization and amplification of region attention is an important factor, which has been explored a lot by convolutional neural networks (CNNs) based approaches. The recently developed vision transformer (ViT) has achieved promising results on computer vision tasks. Compared with CNNs, Image sequentialization is a brand new manner. However, ViT is limited in its receptive field size and thus lacks local attention like CNNs due to the fixed size of its patches, and is unable to generate multi-scale features to learn discriminative region attention. To facilitate the learning of discriminative region attention without box/part annotations, we use the strength of the attention weights to measure the importance of the patch tokens corresponding to the raw images. We propose the recurrent attention multi-scale transformer (RAMS-Trans), which uses the transformer's self-attention to recursively learn discriminative region attention in a multi-scale manner. Specifically, at the core of our approach lies the dynamic patch proposal module (DPPM) guided region amplification to complete the integration of multi-scale image patches. The DPPM starts with the full-size image patches and iteratively scales up the region attention to generate new patches from global to local by the intensity of the attention weights generated at each scale as an indicator. Our approach requires only the attention weights that come with ViT itself and can be easily trained end-to-end. Extensive experiments demonstrate that RAMS-Trans performs better than concurrent works, in addition to efficient CNN models, achieving state-of-the-art results on three benchmark datasets.
Lifelong Learning with Searchable Extension Units
Mar 19, 2020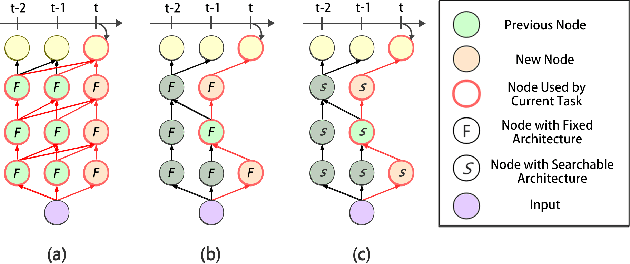
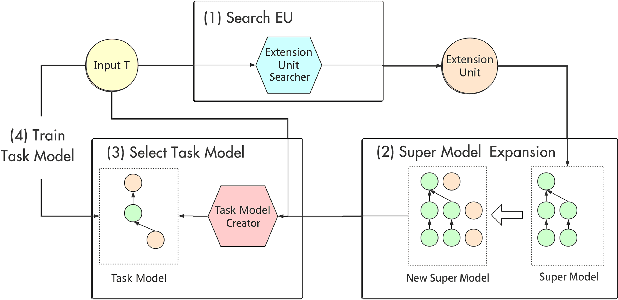
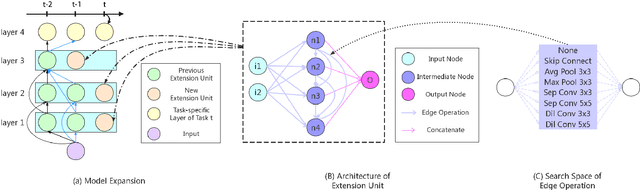
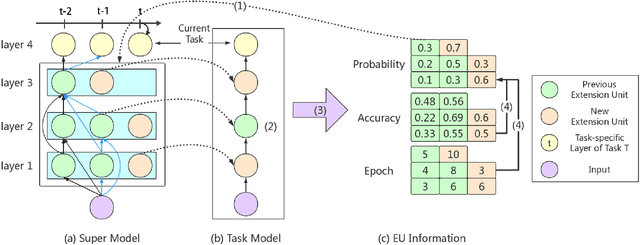
Lifelong learning remains an open problem. One of its main difficulties is catastrophic forgetting. Many dynamic expansion approaches have been proposed to address this problem, but they all use homogeneous models of predefined structure for all tasks. The common original model and expansion structures ignore the requirement of different model structures on different tasks, which leads to a less compact model for multiple tasks and causes the model size to increase rapidly as the number of tasks increases. Moreover, they can not perform best on all tasks. To solve those problems, in this paper, we propose a new lifelong learning framework named Searchable Extension Units (SEU) by introducing Neural Architecture Search into lifelong learning, which breaks down the need for a predefined original model and searches for specific extension units for different tasks, without compromising the performance of the model on different tasks. Our approach can obtain a much more compact model without catastrophic forgetting. The experimental results on the PMNIST, the split CIFAR10 dataset, the split CIFAR100 dataset, and the Mixture dataset empirically prove that our method can achieve higher accuracy with much smaller model, whose size is about 25-33 percentage of that of the state-of-the-art methods.