 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRegulation of Language Models With Interpretability Will Likely Result In A Performance Trade-Off
Dec 12, 2024Regulation is increasingly cited as the most important and pressing concern in machine learning. However, it is currently unknown how to implement this, and perhaps more importantly, how it would effect model performance alongside human collaboration if actually realized. In this paper, we attempt to answer these questions by building a regulatable large-language model (LLM), and then quantifying how the additional constraints involved affect (1) model performance, alongside (2) human collaboration. Our empirical results reveal that it is possible to force an LLM to use human-defined features in a transparent way, but a "regulation performance trade-off" previously not considered reveals itself in the form of a 7.34% classification performance drop. Surprisingly however, we show that despite this, such systems actually improve human task performance speed and appropriate confidence in a realistic deployment setting compared to no AI assistance, thus paving a way for fair, regulatable AI, which benefits users.
Explainable deep learning improves human mental models of self-driving cars
Nov 27, 2024Self-driving cars increasingly rely on deep neural networks to achieve human-like driving. However, the opacity of such black-box motion planners makes it challenging for the human behind the wheel to accurately anticipate when they will fail, with potentially catastrophic consequences. Here, we introduce concept-wrapper network (i.e., CW-Net), a method for explaining the behavior of black-box motion planners by grounding their reasoning in human-interpretable concepts. We deploy CW-Net on a real self-driving car and show that the resulting explanations refine the human driver's mental model of the car, allowing them to better predict its behavior and adjust their own behavior accordingly. Unlike previous work using toy domains or simulations, our study presents the first real-world demonstration of how to build authentic autonomous vehicles (AVs) that give interpretable, causally faithful explanations for their decisions, without sacrificing performance. We anticipate our method could be applied to other safety-critical systems with a human in the loop, such as autonomous drones and robotic surgeons. Overall, our study suggests a pathway to explainability for autonomous agents as a whole, which can help make them more transparent, their deployment safer, and their usage more ethical.
The Utility of "Even if..." Semifactual Explanation to Optimise Positive Outcomes
Oct 29, 2023When users receive either a positive or negative outcome from an automated system, Explainable AI (XAI) has almost exclusively focused on how to mutate negative outcomes into positive ones by crossing a decision boundary using counterfactuals (e.g., \textit{"If you earn 2k more, we will accept your loan application"}). Here, we instead focus on \textit{positive} outcomes, and take the novel step of using XAI to optimise them (e.g., \textit{"Even if you wish to half your down-payment, we will still accept your loan application"}). Explanations such as these that employ "even if..." reasoning, and do not cross a decision boundary, are known as semifactuals. To instantiate semifactuals in this context, we introduce the concept of \textit{Gain} (i.e., how much a user stands to benefit from the explanation), and consider the first causal formalisation of semifactuals. Tests on benchmark datasets show our algorithms are better at maximising gain compared to prior work, and that causality is important in the process. Most importantly however, a user study supports our main hypothesis by showing people find semifactual explanations more useful than counterfactuals when they receive the positive outcome of a loan acceptance.
Generating Plausible Counterfactual Explanations for Deep Transformers in Financial Text Classification
Oct 23, 2020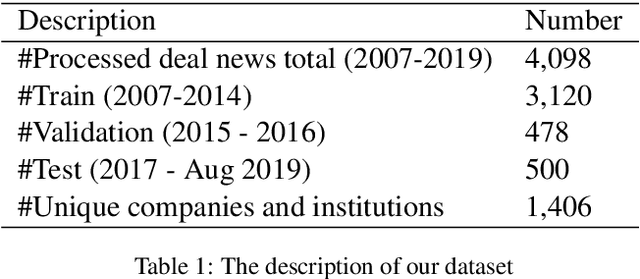
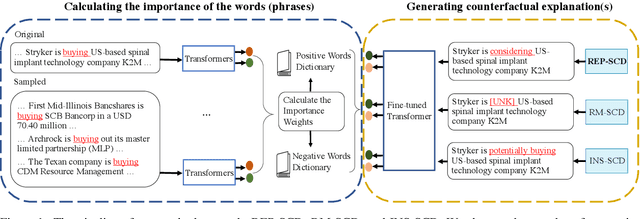
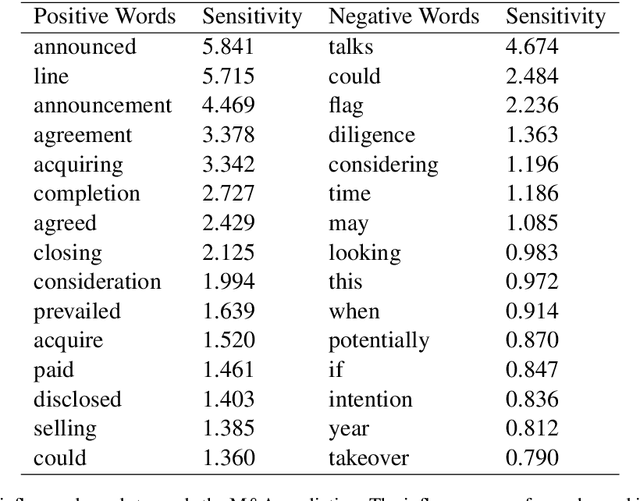
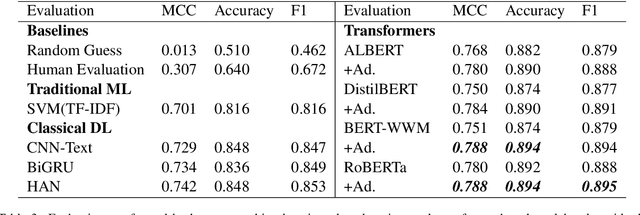
Corporate mergers and acquisitions (M&A) account for billions of dollars of investment globally every year, and offer an interesting and challenging domain for artificial intelligence. However, in these highly sensitive domains, it is crucial to not only have a highly robust and accurate model, but be able to generate useful explanations to garner a user's trust in the automated system. Regrettably, the recent research regarding eXplainable AI (XAI) in financial text classification has received little to no attention, and many current methods for generating textual-based explanations result in highly implausible explanations, which damage a user's trust in the system. To address these issues, this paper proposes a novel methodology for producing plausible counterfactual explanations, whilst exploring the regularization benefits of adversarial training on language models in the domain of FinTech. Exhaustive quantitative experiments demonstrate that not only does this approach improve the model accuracy when compared to the current state-of-the-art and human performance, but it also generates counterfactual explanations which are significantly more plausible based on human trials.
Play MNIST For Me! User Studies on the Effects of Post-Hoc, Example-Based Explanations & Error Rates on Debugging a Deep Learning, Black-Box Classifier
Sep 10, 2020

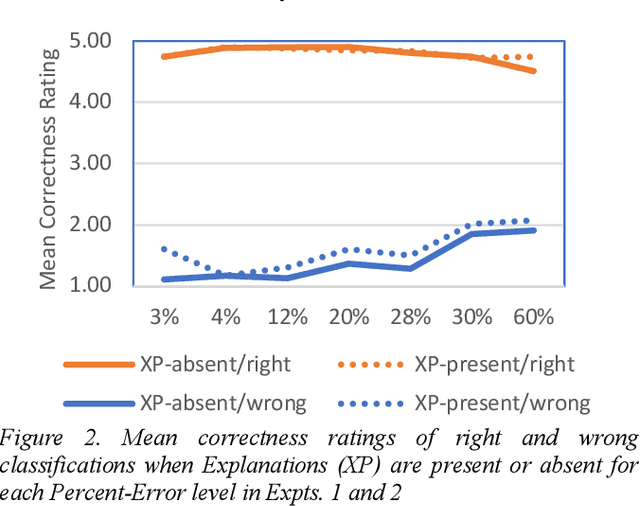
This paper reports two experiments (N=349) on the impact of post hoc explanations by example and error rates on peoples perceptions of a black box classifier. Both experiments show that when people are given case based explanations, from an implemented ANN CBR twin system, they perceive miss classifications to be more correct. They also show that as error rates increase above 4%, people trust the classifier less and view it as being less correct, less reasonable and less trustworthy. The implications of these results for XAI are discussed.
* 2 Figures, 1 Table, 8 pages
On Generating Plausible Counterfactual and Semi-Factual Explanations for Deep Learning
Sep 10, 2020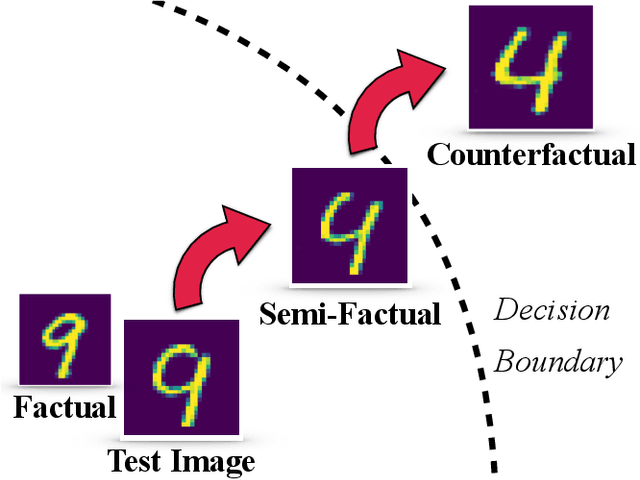



There is a growing concern that the recent progress made in AI, especially regarding the predictive competence of deep learning models, will be undermined by a failure to properly explain their operation and outputs. In response to this disquiet counterfactual explanations have become massively popular in eXplainable AI (XAI) due to their proposed computational psychological, and legal benefits. In contrast however, semifactuals, which are a similar way humans commonly explain their reasoning, have surprisingly received no attention. Most counterfactual methods address tabular rather than image data, partly due to the nondiscrete nature of the latter making good counterfactuals difficult to define. Additionally generating plausible looking explanations which lie on the data manifold is another issue which hampers progress. This paper advances a novel method for generating plausible counterfactuals (and semifactuals) for black box CNN classifiers doing computer vision. The present method, called PlausIble Exceptionality-based Contrastive Explanations (PIECE), modifies all exceptional features in a test image to be normal from the perspective of the counterfactual class (hence concretely defining a counterfactual). Two controlled experiments compare this method to others in the literature, showing that PIECE not only generates the most plausible counterfactuals on several measures, but also the best semifactuals.
The Twin-System Approach as One Generic Solution for XAI: An Overview of ANN-CBR Twins for Explaining Deep Learning
May 20, 2019


The notion of twin systems is proposed to address the eXplainable AI (XAI) problem, where an uninterpretable black-box system is mapped to a white-box 'twin' that is more interpretable. In this short paper, we overview very recent work that advances a generic solution to the XAI problem, the so called twin system approach. The most popular twinning in the literature is that between an Artificial Neural Networks (ANN ) as a black box and Case Based Reasoning (CBR) system as a white-box, where the latter acts as an interpretable proxy for the former. We outline how recent work reviving this idea has applied it to deep learning methods. Furthermore, we detail the many fruitful directions in which this work may be taken; such as, determining the most (i) accurate feature-weighting methods to be used, (ii) appropriate deployments for explanatory cases, (iii) useful cases of explanatory value to users.