 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRelational Probing: LM-to-Graph Adaptation for Financial Prediction
Apr 11, 2026Language models can be used to identify relationships between financial entities in text. However, while structured output mechanisms exist, prompting-based pipelines still incur autoregressive decoding costs and decouple graph construction from downstream optimization. We propose \emph{Relational Probing}, which replaces the standard language-model head with a relation head that induces a relational graph directly from language-model hidden states and is trained jointly with the downstream task model for stock-trend prediction. This approach both learns semantic representations and preserves the strict structure of the induced relational graph. It enables language-model outputs to go beyond text, allowing them to be reshaped into task-specific formats for downstream models. To enhance reproducibility, we provide an operational definition of small language models (SLMs): models that can be fine-tuned end-to-end on a single 24GB GPU under specified batch-size and sequence-length settings. Experiments use Qwen3 backbones (0.6B/1.7B/4B) as upstream SLMs and compare against a co-occurrence baseline. Relational Probing yields consistent performance improvements at competitive inference cost.
GAPNet: Plug-in Jointly Learning Task-Specific Graph for Dynamic Stock Relation
Jan 31, 2026The advent of the web has led to a paradigm shift in the financial relations, with the real-time dissemination of news, social discourse, and financial filings contributing significantly to the reshaping of financial forecasting. The existing methods rely on establishing relations a priori, i.e. predefining graphs to capture inter-stock relationships. However, the stock-related web signals are characterised by high levels of noise, asynchrony, and challenging to obtain, resulting in poor generalisability and non-alignment between the predefined graphs and the downstream tasks. To address this, we propose GAPNet, a Graph Adaptation Plug-in Network that jointly learns task-specific topology and representations in an end-to-end manner. GAPNet attaches to existing pairwise graph or hypergraph backbone models, enabling the dynamic adaptation and rewiring of edge topologies via two complementary components: a Spatial Perception Layer that captures short-term co-movements across assets, and a Temporal Perception Layer that maintains long-term dependency under distribution shift. Across two real-world stock datasets, GAPNet has been shown to consistently enhance the profitability and stability in comparision to the state-of-the-art models, yielding annualised cumulative returns of up to 0.47 for RT-GCN and 0.63 for CI-STHPAN, with peak Sharpe Ratio of 2.20 and 2.12 respectively. The plug-and-play design of GAPNet ensures its broad applicability to diverse GNN-based architectures. Our results underscore that jointly learning graph structures and representations is essential for task-specific relational modeling.
NGAT: A Node-level Graph Attention Network for Long-term Stock Prediction
Jul 02, 2025Graph representation learning methods have been widely adopted in financial applications to enhance company representations by leveraging inter-firm relationships. However, current approaches face three key challenges: (1) The advantages of relational information are obscured by limitations in downstream task designs; (2) Existing graph models specifically designed for stock prediction often suffer from excessive complexity and poor generalization; (3) Experience-based construction of corporate relationship graphs lacks effective comparison of different graph structures. To address these limitations, we propose a long-term stock prediction task and develop a Node-level Graph Attention Network (NGAT) specifically tailored for corporate relationship graphs. Furthermore, we experimentally demonstrate the limitations of existing graph comparison methods based on model downstream task performance. Experimental results across two datasets consistently demonstrate the effectiveness of our proposed task and model. The project is publicly available on GitHub to encourage reproducibility and future research.
Deep Learning Approaches for Medical Imaging Under Varying Degrees of Label Availability: A Comprehensive Survey
Apr 15, 2025



Deep learning has achieved significant breakthroughs in medical imaging, but these advancements are often dependent on large, well-annotated datasets. However, obtaining such datasets poses a significant challenge, as it requires time-consuming and labor-intensive annotations from medical experts. Consequently, there is growing interest in learning paradigms such as incomplete, inexact, and absent supervision, which are designed to operate under limited, inexact, or missing labels. This survey categorizes and reviews the evolving research in these areas, analyzing around 600 notable contributions since 2018. It covers tasks such as image classification, segmentation, and detection across various medical application areas, including but not limited to brain, chest, and cardiac imaging. We attempt to establish the relationships among existing research studies in related areas. We provide formal definitions of different learning paradigms and offer a comprehensive summary and interpretation of various learning mechanisms and strategies, aiding readers in better understanding the current research landscape and ideas. We also discuss potential future research challenges.
Transformers4NewsRec: A Transformer-based News Recommendation Framework
Oct 17, 2024



Pre-trained transformer models have shown great promise in various natural language processing tasks, including personalized news recommendations. To harness the power of these models, we introduce Transformers4NewsRec, a new Python framework built on the \textbf{Transformers} library. This framework is designed to unify and compare the performance of various news recommendation models, including deep neural networks and graph-based models. Transformers4NewsRec offers flexibility in terms of model selection, data preprocessing, and evaluation, allowing both quantitative and qualitative analysis.
Contrastive Learning of Asset Embeddings from Financial Time Series
Jul 26, 2024Representation learning has emerged as a powerful paradigm for extracting valuable latent features from complex, high-dimensional data. In financial domains, learning informative representations for assets can be used for tasks like sector classification, and risk management. However, the complex and stochastic nature of financial markets poses unique challenges. We propose a novel contrastive learning framework to generate asset embeddings from financial time series data. Our approach leverages the similarity of asset returns over many subwindows to generate informative positive and negative samples, using a statistical sampling strategy based on hypothesis testing to address the noisy nature of financial data. We explore various contrastive loss functions that capture the relationships between assets in different ways to learn a discriminative representation space. Experiments on real-world datasets demonstrate the effectiveness of the learned asset embeddings on benchmark industry classification and portfolio optimization tasks. In each case our novel approaches significantly outperform existing baselines highlighting the potential for contrastive learning to capture meaningful and actionable relationships in financial data.
Breaking the Barrier: Selective Uncertainty-based Active Learning for Medical Image Segmentation
Jan 29, 2024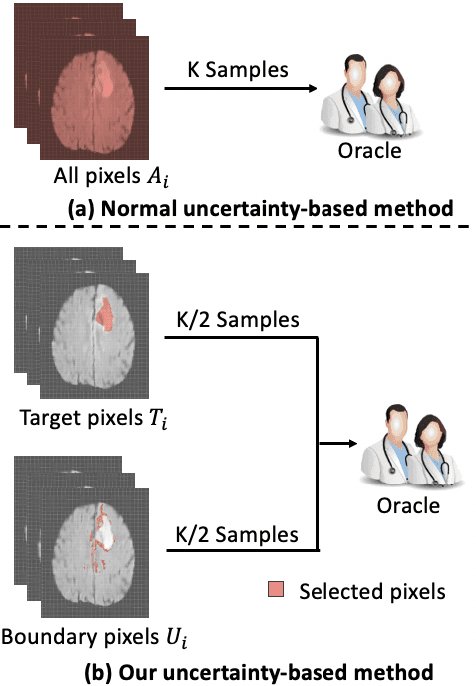

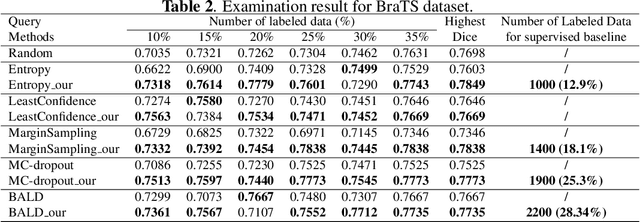
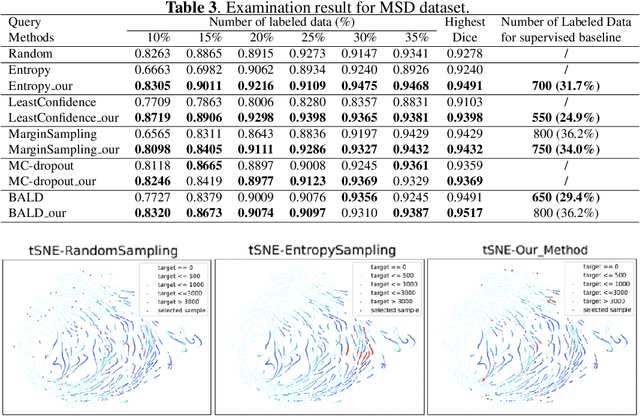
Active learning (AL) has found wide applications in medical image segmentation, aiming to alleviate the annotation workload and enhance performance. Conventional uncertainty-based AL methods, such as entropy and Bayesian, often rely on an aggregate of all pixel-level metrics. However, in imbalanced settings, these methods tend to neglect the significance of target regions, eg., lesions, and tumors. Moreover, uncertainty-based selection introduces redundancy. These factors lead to unsatisfactory performance, and in many cases, even underperform random sampling. To solve this problem, we introduce a novel approach called the Selective Uncertainty-based AL, avoiding the conventional practice of summing up the metrics of all pixels. Through a filtering process, our strategy prioritizes pixels within target areas and those near decision boundaries. This resolves the aforementioned disregard for target areas and redundancy. Our method showed substantial improvements across five different uncertainty-based methods and two distinct datasets, utilizing fewer labeled data to reach the supervised baseline and consistently achieving the highest overall performance. Our code is available at https://github.com/HelenMa9998/Selective\_Uncertainty\_AL.
RecPrompt: A Prompt Tuning Framework for News Recommendation Using Large Language Models
Dec 16, 2023



In the evolving field of personalized news recommendation, understanding the semantics of the underlying data is crucial. Large Language Models (LLMs) like GPT-4 have shown promising performance in understanding natural language. However, the extent of their applicability in news recommendation systems remains to be validated. This paper introduces RecPrompt, the first framework for news recommendation that leverages the capabilities of LLMs through prompt engineering. This system incorporates a prompt optimizer that applies an iterative bootstrapping process, enhancing the LLM-based recommender's ability to align news content with user preferences and interests more effectively. Moreover, this study offers insights into the effective use of LLMs in news recommendation, emphasizing both the advantages and the challenges of incorporating LLMs into recommendation systems.
Can We Transfer Noise Patterns? A Multi-environment Spectrum Analysis Model Using Generated Cases
Aug 14, 2023



Spectrum analysis systems in online water quality testing are designed to detect types and concentrations of pollutants and enable regulatory agencies to respond promptly to pollution incidents. However, spectral data-based testing devices suffer from complex noise patterns when deployed in non-laboratory environments. To make the analysis model applicable to more environments, we propose a noise patterns transferring model, which takes the spectrum of standard water samples in different environments as cases and learns the differences in their noise patterns, thus enabling noise patterns to transfer to unknown samples. Unfortunately, the inevitable sample-level baseline noise makes the model unable to obtain the paired data that only differ in dataset-level environmental noise. To address the problem, we generate a sample-to-sample case-base to exclude the interference of sample-level noise on dataset-level noise learning, enhancing the system's learning performance. Experiments on spectral data with different background noises demonstrate the good noise-transferring ability of the proposed method against baseline systems ranging from wavelet denoising, deep neural networks, and generative models. From this research, we posit that our method can enhance the performance of DL models by generating high-quality cases. The source code is made publicly available online at https://github.com/Magnomic/CNST.
Going Beyond Local: Global Graph-Enhanced Personalized News Recommendations
Jul 31, 2023



Precisely recommending candidate news articles to users has always been a core challenge for personalized news recommendation systems. Most recent works primarily focus on using advanced natural language processing techniques to extract semantic information from rich textual data, employing content-based methods derived from local historical news. However, this approach lacks a global perspective, failing to account for users' hidden motivations and behaviors beyond semantic information. To address this challenge, we propose a novel model called GLORY (Global-LOcal news Recommendation sYstem), which combines global representations learned from other users with local representations to enhance personalized recommendation systems. We accomplish this by constructing a Global-aware Historical News Encoder, which includes a global news graph and employs gated graph neural networks to enrich news representations, thereby fusing historical news representations by a historical news aggregator. Similarly, we extend this approach to a Global Candidate News Encoder, utilizing a global entity graph and a candidate news aggregator to enhance candidate news representation. Evaluation results on two public news datasets demonstrate that our method outperforms existing approaches. Furthermore, our model offers more diverse recommendations.