 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRelational Probing: LM-to-Graph Adaptation for Financial Prediction
Apr 11, 2026Language models can be used to identify relationships between financial entities in text. However, while structured output mechanisms exist, prompting-based pipelines still incur autoregressive decoding costs and decouple graph construction from downstream optimization. We propose \emph{Relational Probing}, which replaces the standard language-model head with a relation head that induces a relational graph directly from language-model hidden states and is trained jointly with the downstream task model for stock-trend prediction. This approach both learns semantic representations and preserves the strict structure of the induced relational graph. It enables language-model outputs to go beyond text, allowing them to be reshaped into task-specific formats for downstream models. To enhance reproducibility, we provide an operational definition of small language models (SLMs): models that can be fine-tuned end-to-end on a single 24GB GPU under specified batch-size and sequence-length settings. Experiments use Qwen3 backbones (0.6B/1.7B/4B) as upstream SLMs and compare against a co-occurrence baseline. Relational Probing yields consistent performance improvements at competitive inference cost.
Taxonomy-Aligned Risk Extraction from 10-K Filings with Autonomous Improvement Using LLMs
Jan 21, 2026We present a methodology for extracting structured risk factors from corporate 10-K filings while maintaining adherence to a predefined hierarchical taxonomy. Our three-stage pipeline combines LLM extraction with supporting quotes, embedding-based semantic mapping to taxonomy categories, and LLM-as-a-judge validation that filters spurious assignments. To evaluate our approach, we extract 10,688 risk factors from S&P 500 companies and examine risk profile similarity across industry clusters. Beyond extraction, we introduce autonomous taxonomy maintenance where an AI agent analyzes evaluation feedback to identify problematic categories, diagnose failure patterns, and propose refinements, achieving 104.7% improvement in embedding separation in a case study. External validation confirms the taxonomy captures economically meaningful structure: same-industry companies exhibit 63% higher risk profile similarity than cross-industry pairs (Cohen's d=1.06, AUC 0.82, p<0.001). The methodology generalizes to any domain requiring taxonomy-aligned extraction from unstructured text, with autonomous improvement enabling continuous quality maintenance and enhancement as systems process more documents.
Contrastive Learning of Asset Embeddings from Financial Time Series
Jul 26, 2024Representation learning has emerged as a powerful paradigm for extracting valuable latent features from complex, high-dimensional data. In financial domains, learning informative representations for assets can be used for tasks like sector classification, and risk management. However, the complex and stochastic nature of financial markets poses unique challenges. We propose a novel contrastive learning framework to generate asset embeddings from financial time series data. Our approach leverages the similarity of asset returns over many subwindows to generate informative positive and negative samples, using a statistical sampling strategy based on hypothesis testing to address the noisy nature of financial data. We explore various contrastive loss functions that capture the relationships between assets in different ways to learn a discriminative representation space. Experiments on real-world datasets demonstrate the effectiveness of the learned asset embeddings on benchmark industry classification and portfolio optimization tasks. In each case our novel approaches significantly outperform existing baselines highlighting the potential for contrastive learning to capture meaningful and actionable relationships in financial data.
Extracting Structured Insights from Financial News: An Augmented LLM Driven Approach
Jul 22, 2024



Financial news plays a crucial role in decision-making processes across the financial sector, yet the efficient processing of this information into a structured format remains challenging. This paper presents a novel approach to financial news processing that leverages Large Language Models (LLMs) to overcome limitations that previously prevented the extraction of structured data from unstructured financial news. We introduce a system that extracts relevant company tickers from raw news article content, performs sentiment analysis at the company level, and generates summaries, all without relying on pre-structured data feeds. Our methodology combines the generative capabilities of LLMs, and recent prompting techniques, with a robust validation framework that uses a tailored string similarity approach. Evaluation on a dataset of 5530 financial news articles demonstrates the effectiveness of our approach, with 90% of articles not missing any tickers compared with current data providers, and 22% of articles having additional relevant tickers. In addition to this paper, the methodology has been implemented at scale with the resulting processed data made available through a live API endpoint, which is updated in real-time with the latest news. To the best of our knowledge, we are the first data provider to offer granular, per-company sentiment analysis from news articles, enhancing the depth of information available to market participants. We also release the evaluation dataset of 5530 processed articles as a static file, which we hope will facilitate further research leveraging financial news.
Industry Classification Using a Novel Financial Time-Series Case Representation
Apr 29, 2023


The financial domain has proven to be a fertile source of challenging machine learning problems across a variety of tasks including prediction, clustering, and classification. Researchers can access an abundance of time-series data and even modest performance improvements can be translated into significant additional value. In this work, we consider the use of case-based reasoning for an important task in this domain, by using historical stock returns time-series data for industry sector classification. We discuss why time-series data can present some significant representational challenges for conventional case-based reasoning approaches, and in response, we propose a novel representation based on stock returns embeddings, which can be readily calculated from raw stock returns data. We argue that this representation is well suited to case-based reasoning and evaluate our approach using a large-scale public dataset for the industry sector classification task, demonstrating substantial performance improvements over several baselines using more conventional representations.
Stock Embeddings: Learning Distributed Representations for Financial Assets
Feb 14, 2022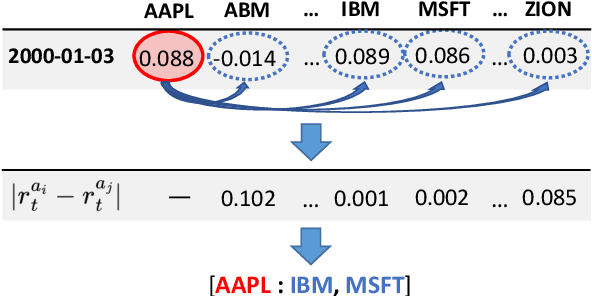
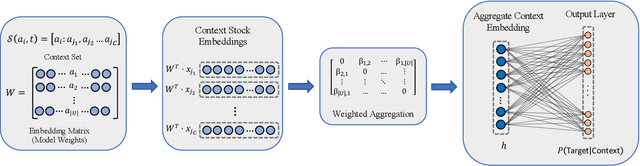
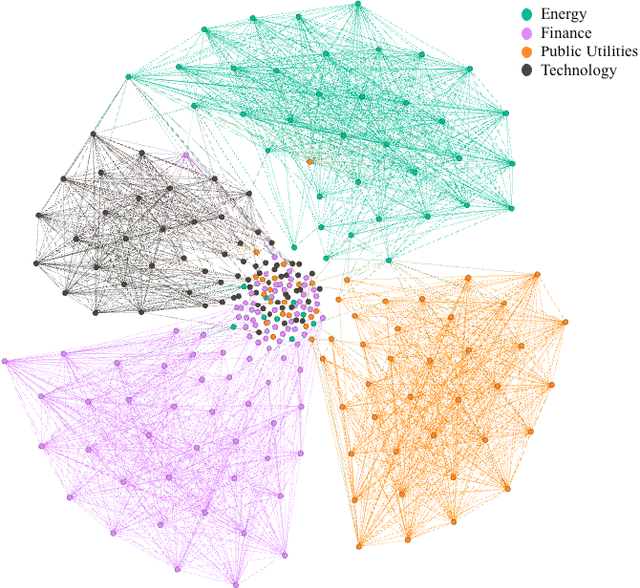
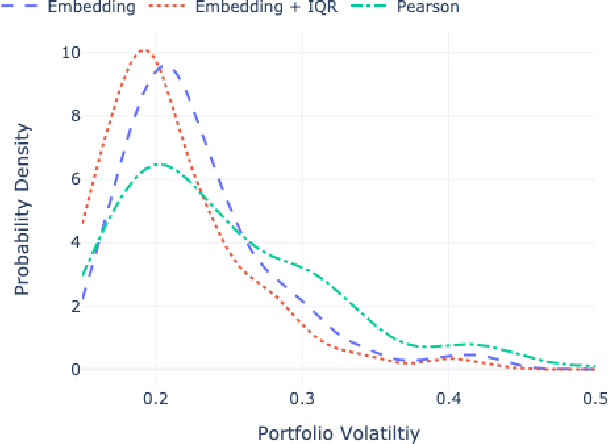
Identifying meaningful relationships between the price movements of financial assets is a challenging but important problem in a variety of financial applications. However with recent research, particularly those using machine learning and deep learning techniques, focused mostly on price forecasting, the literature investigating the modelling of asset correlations has lagged somewhat. To address this, inspired by recent successes in natural language processing, we propose a neural model for training stock embeddings, which harnesses the dynamics of historical returns data in order to learn the nuanced relationships that exist between financial assets. We describe our approach in detail and discuss a number of ways that it can be used in the financial domain. Furthermore, we present the evaluation results to demonstrate the utility of this approach, compared to several important benchmarks, in two real-world financial analytics tasks.
Measuring Financial Time Series Similarity With a View to Identifying Profitable Stock Market Opportunities
Jul 07, 2021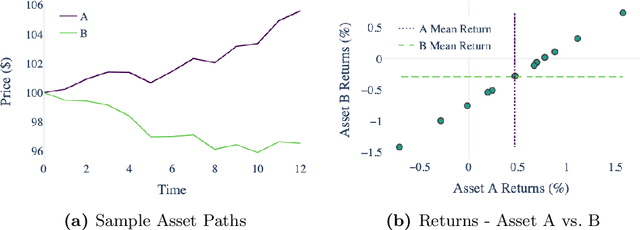
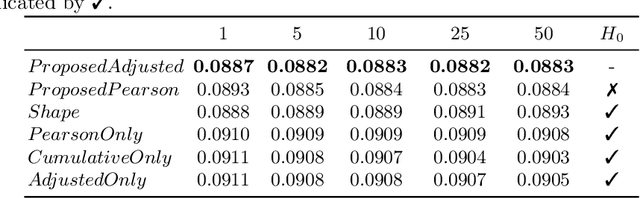
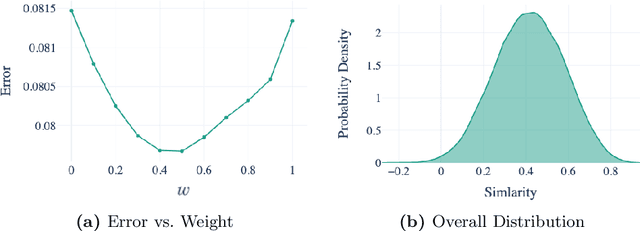
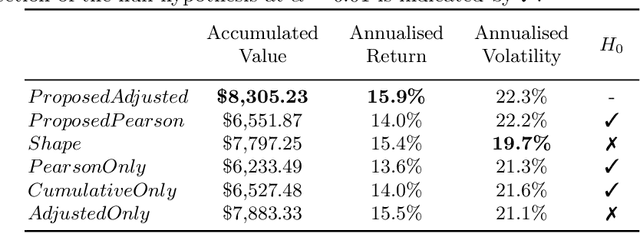
Forecasting stock returns is a challenging problem due to the highly stochastic nature of the market and the vast array of factors and events that can influence trading volume and prices. Nevertheless it has proven to be an attractive target for machine learning research because of the potential for even modest levels of prediction accuracy to deliver significant benefits. In this paper, we describe a case-based reasoning approach to predicting stock market returns using only historical pricing data. We argue that one of the impediments for case-based stock prediction has been the lack of a suitable similarity metric when it comes to identifying similar pricing histories as the basis for a future prediction -- traditional Euclidean and correlation based approaches are not effective for a variety of reasons -- and in this regard, a key contribution of this work is the development of a novel similarity metric for comparing historical pricing data. We demonstrate the benefits of this metric and the case-based approach in a real-world application in comparison to a variety of conventional benchmarks.